 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Modal Fine-Grained Alignment via Granularity-Aware and Region-Uncertain Modeling
Nov 19, 2025Fine-grained image-text alignment is a pivotal challenge in multimodal learning, underpinning key applications such as visual question answering, image captioning, and vision-language navigation. Unlike global alignment, fine-grained alignment requires precise correspondence between localized visual regions and textual tokens, often hindered by noisy attention mechanisms and oversimplified modeling of cross-modal relationships. In this work, we identify two fundamental limitations of existing approaches: the lack of robust intra-modal mechanisms to assess the significance of visual and textual tokens, leading to poor generalization in complex scenes; and the absence of fine-grained uncertainty modeling, which fails to capture the one-to-many and many-to-one nature of region-word correspondences. To address these issues, we propose a unified approach that incorporates significance-aware and granularity-aware modeling and region-level uncertainty modeling. Our method leverages modality-specific biases to identify salient features without relying on brittle cross-modal attention, and represents region features as a mixture of Gaussian distributions to capture fine-grained uncertainty. Extensive experiments on Flickr30K and MS-COCO demonstrate that our approach achieves state-of-the-art performance across various backbone architectures, significantly enhancing the robustness and interpretability of fine-grained image-text alignment.
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Apr 15, 2021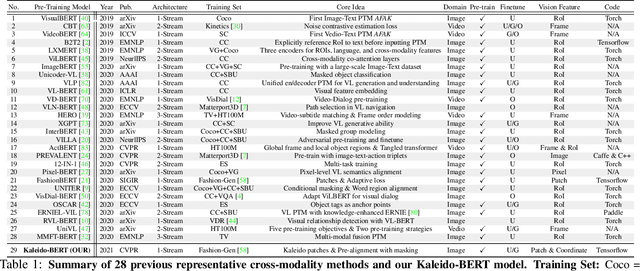
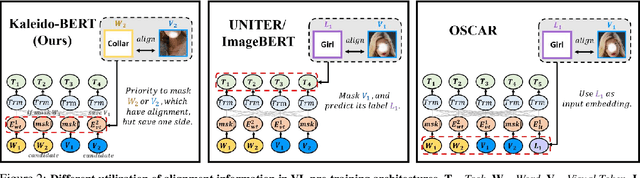
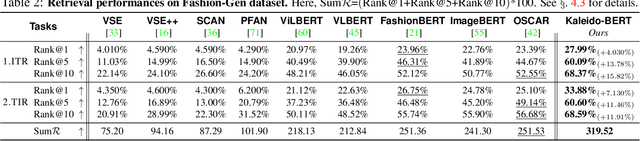
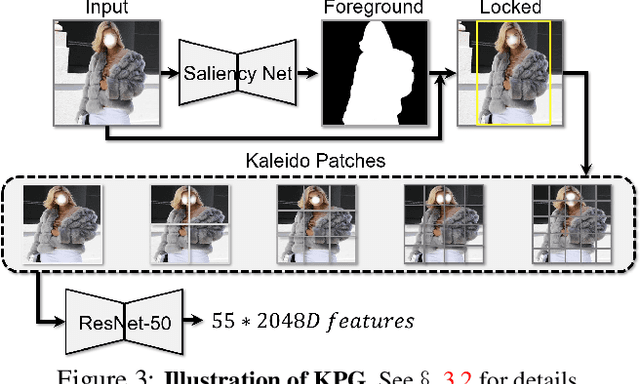
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.