 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerified Critical Step Optimization for LLM Agents
Feb 03, 2026As large language model agents tackle increasingly complex long-horizon tasks, effective post-training becomes critical. Prior work faces fundamental challenges: outcome-only rewards fail to precisely attribute credit to intermediate steps, estimated step-level rewards introduce systematic noise, and Monte Carlo sampling approaches for step reward estimation incur prohibitive computational cost. Inspired by findings that only a small fraction of high-entropy tokens drive effective RL for reasoning, we propose Critical Step Optimization (CSO), which focuses preference learning on verified critical steps, decision points where alternate actions demonstrably flip task outcomes from failure to success. Crucially, our method starts from failed policy trajectories rather than expert demonstrations, directly targeting the policy model's weaknesses. We use a process reward model (PRM) to identify candidate critical steps, leverage expert models to propose high-quality alternatives, then continue execution from these alternatives using the policy model itself until task completion. Only alternatives that the policy successfully executes to correct outcomes are verified and used as DPO training data, ensuring both quality and policy reachability. This yields fine-grained, verifiable supervision at critical decisions while avoiding trajectory-level coarseness and step-level noise. Experiments on GAIA-Text-103 and XBench-DeepSearch show that CSO achieves 37% and 26% relative improvement over the SFT baseline and substantially outperforms other post-training methods, while requiring supervision at only 16% of trajectory steps. This demonstrates the effectiveness of selective verification-based learning for agent post-training.
CLUE: Non-parametric Verification from Experience via Hidden-State Clustering
Oct 02, 2025



Assessing the quality of Large Language Model (LLM) outputs presents a critical challenge. Previous methods either rely on text-level information (e.g., reward models, majority voting), which can overfit to superficial cues, or on calibrated confidence from token probabilities, which would fail on less-calibrated models. Yet both of these signals are, in fact, partial projections of a richer source of information: the model's internal hidden states. Early layers, closer to token embeddings, preserve semantic and lexical features that underpin text-based judgments, while later layers increasingly align with output logits, embedding confidence-related information. This paper explores hidden states directly as a unified foundation for verification. We show that the correctness of a solution is encoded as a geometrically separable signature within the trajectory of hidden activations. To validate this, we present Clue (Clustering and Experience-based Verification), a deliberately minimalist, non-parametric verifier. With no trainable parameters, CLUE only summarizes each reasoning trace by an hidden state delta and classifies correctness via nearest-centroid distance to ``success'' and ``failure'' clusters formed from past experience. The simplicity of this method highlights the strength of the underlying signal. Empirically, CLUE consistently outperforms LLM-as-a-judge baselines and matches or exceeds modern confidence-based methods in reranking candidates, improving both top-1 and majority-vote accuracy across AIME 24/25 and GPQA. As a highlight, on AIME 24 with a 1.5B model, CLUE boosts accuracy from 56.7% (majority@64) to 70.0% (top-maj@16).
VOGUE: Guiding Exploration with Visual Uncertainty Improves Multimodal Reasoning
Oct 01, 2025



Reinforcement learning with verifiable rewards (RLVR) improves reasoning in large language models (LLMs) but struggles with exploration, an issue that still persists for multimodal LLMs (MLLMs). Current methods treat the visual input as a fixed, deterministic condition, overlooking a critical source of ambiguity and struggling to build policies robust to plausible visual variations. We introduce $\textbf{VOGUE (Visual Uncertainty Guided Exploration)}$, a novel method that shifts exploration from the output (text) to the input (visual) space. By treating the image as a stochastic context, VOGUE quantifies the policy's sensitivity to visual perturbations using the symmetric KL divergence between a "raw" and "noisy" branch, creating a direct signal for uncertainty-aware exploration. This signal shapes the learning objective via an uncertainty-proportional bonus, which, combined with a token-entropy bonus and an annealed sampling schedule, effectively balances exploration and exploitation. Implemented within GRPO on two model scales (Qwen2.5-VL-3B/7B), VOGUE boosts pass@1 accuracy by an average of 2.6% on three visual math benchmarks and 3.7% on three general-domain reasoning benchmarks, while simultaneously increasing pass@4 performance and mitigating the exploration decay commonly observed in RL fine-tuning. Our work shows that grounding exploration in the inherent uncertainty of visual inputs is an effective strategy for improving multimodal reasoning.
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
Sep 18, 2025Large language models (LLMs) are increasingly trained with reinforcement learning from verifiable rewards (RLVR), yet real-world deployment demands models that can self-improve without labels or external judges. Existing label-free methods, confidence minimization, self-consistency, or majority-vote objectives, stabilize learning but steadily shrink exploration, causing an entropy collapse: generations become shorter, less diverse, and brittle. Unlike prior approaches such as Test-Time Reinforcement Learning (TTRL), which primarily adapt models to the immediate unlabeled dataset at hand, our goal is broader: to enable general improvements without sacrificing the model's inherent exploration capacity and generalization ability, i.e., evolving. We formalize this issue and propose EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL), a simple rule that couples stability with variation under a label-free setting. EVOL-RL keeps the majority-voted answer as a stable anchor (selection) while adding a novelty-aware reward that favors responses whose reasoning differs from what has already been produced (variation), measured in semantic space. Implemented with GRPO, EVOL-RL also uses asymmetric clipping to preserve strong signals and an entropy regularizer to sustain search. This majority-for-selection + novelty-for-variation design prevents collapse, maintains longer and more informative chains of thought, and improves both pass@1 and pass@n. EVOL-RL consistently outperforms the majority-only TTRL baseline; e.g., training on label-free AIME24 lifts Qwen3-4B-Base AIME25 pass@1 from TTRL's 4.6% to 16.4%, and pass@16 from 18.5% to 37.9%. EVOL-RL not only prevents diversity collapse but also unlocks stronger generalization across domains (e.g., GPQA). Furthermore, we demonstrate that EVOL-RL also boosts performance in the RLVR setting, highlighting its broad applicability.
EconProver: Towards More Economical Test-Time Scaling for Automated Theorem Proving
Sep 16, 2025Large Language Models (LLMs) have recently advanced the field of Automated Theorem Proving (ATP), attaining substantial performance gains through widely adopted test-time scaling strategies, notably reflective Chain-of-Thought (CoT) reasoning and increased sampling passes. However, they both introduce significant computational overhead for inference. Moreover, existing cost analyses typically regulate only the number of sampling passes, while neglecting the substantial disparities in sampling costs introduced by different scaling strategies. In this paper, we systematically compare the efficiency of different test-time scaling strategies for ATP models and demonstrate the inefficiency of the current state-of-the-art (SOTA) open-source approaches. We then investigate approaches to significantly reduce token usage and sample passes while maintaining the original performance. Specifically, we propose two complementary methods that can be integrated into a unified EconRL pipeline for amplified benefits: (1) a dynamic Chain-of-Thought (CoT) switching mechanism designed to mitigate unnecessary token consumption, and (2) Diverse parallel-scaled reinforcement learning (RL) with trainable prefixes to enhance pass rates under constrained sampling passes. Experiments on miniF2F and ProofNet demonstrate that our EconProver achieves comparable performance to baseline methods with only 12% of the computational cost. This work provides actionable insights for deploying lightweight ATP models without sacrificing performance.
CDE: Curiosity-Driven Exploration for Efficient Reinforcement Learning in Large Language Models
Sep 11, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) is a powerful paradigm for enhancing the reasoning ability of Large Language Models (LLMs). Yet current RLVR methods often explore poorly, leading to premature convergence and entropy collapse. To address this challenge, we introduce Curiosity-Driven Exploration (CDE), a framework that leverages the model's own intrinsic sense of curiosity to guide exploration. We formalize curiosity with signals from both the actor and the critic: for the actor, we use perplexity over its generated response, and for the critic, we use the variance of value estimates from a multi-head architecture. Both signals serve as an exploration bonus within the RLVR framework to guide the model. Our theoretical analysis shows that the actor-wise bonus inherently penalizes overconfident errors and promotes diversity among correct responses; moreover, we connect the critic-wise bonus to the well-established count-based exploration bonus in RL. Empirically, our method achieves an approximate +3 point improvement over standard RLVR using GRPO/PPO on AIME benchmarks. Further analysis identifies a calibration collapse mechanism within RLVR, shedding light on common LLM failure modes.
DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning
May 29, 2025



Theorem proving serves as a major testbed for evaluating complex reasoning abilities in large language models (LLMs). However, traditional automated theorem proving (ATP) approaches rely heavily on formal proof systems that poorly align with LLMs' strength derived from informal, natural language knowledge acquired during pre-training. In this work, we propose DeepTheorem, a comprehensive informal theorem-proving framework exploiting natural language to enhance LLM mathematical reasoning. DeepTheorem includes a large-scale benchmark dataset consisting of 121K high-quality IMO-level informal theorems and proofs spanning diverse mathematical domains, rigorously annotated for correctness, difficulty, and topic categories, accompanied by systematically constructed verifiable theorem variants. We devise a novel reinforcement learning strategy (RL-Zero) explicitly tailored to informal theorem proving, leveraging the verified theorem variants to incentivize robust mathematical inference. Additionally, we propose comprehensive outcome and process evaluation metrics examining proof correctness and the quality of reasoning steps. Extensive experimental analyses demonstrate DeepTheorem significantly improves LLM theorem-proving performance compared to existing datasets and supervised fine-tuning protocols, achieving state-of-the-art accuracy and reasoning quality. Our findings highlight DeepTheorem's potential to fundamentally advance automated informal theorem proving and mathematical exploration.
MPS-Prover: Advancing Stepwise Theorem Proving by Multi-Perspective Search and Data Curation
May 16, 2025Automated Theorem Proving (ATP) in formal languages remains a formidable challenge in AI, demanding rigorous logical deduction and navigating vast search spaces. While large language models (LLMs) have shown promising performance, existing stepwise provers often suffer from biased search guidance, leading to inefficiencies and suboptimal proof strategies. This paper introduces the Multi-Perspective Search Prover (MPS-Prover), a novel stepwise ATP system designed to overcome these limitations. MPS-Prover incorporates two key innovations: a highly effective post-training data curation strategy that prunes approximately 40% of redundant training data without sacrificing performance, and a multi-perspective tree search mechanism. This search integrates a learned critic model with strategically designed heuristic rules to diversify tactic selection, prevent getting trapped in unproductive states, and enhance search robustness. Extensive evaluations demonstrate that MPS-Prover achieves state-of-the-art performance on multiple challenging benchmarks, including miniF2F and ProofNet, outperforming prior 7B parameter models. Furthermore, our analyses reveal that MPS-Prover generates significantly shorter and more diverse proofs compared to existing stepwise and whole-proof methods, highlighting its efficiency and efficacy. Our work advances the capabilities of LLM-based formal reasoning and offers a robust framework and a comprehensive analysis for developing more powerful theorem provers.
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning
Apr 15, 2025



The capacity for complex mathematical reasoning is a key benchmark for artificial intelligence. While reinforcement learning (RL) applied to LLMs shows promise, progress is significantly hindered by the lack of large-scale training data that is sufficiently challenging, possesses verifiable answer formats suitable for RL, and is free from contamination with evaluation benchmarks. To address these limitations, we introduce DeepMath-103K, a new, large-scale dataset comprising approximately 103K mathematical problems, specifically designed to train advanced reasoning models via RL. DeepMath-103K is curated through a rigorous pipeline involving source analysis, stringent decontamination against numerous benchmarks, and filtering for high difficulty (primarily Levels 5-9), significantly exceeding existing open resources in challenge. Each problem includes a verifiable final answer, enabling rule-based RL, and three distinct R1-generated solutions suitable for diverse training paradigms like supervised fine-tuning or distillation. Spanning a wide range of mathematical topics, DeepMath-103K promotes the development of generalizable reasoning. We demonstrate that models trained on DeepMath-103K achieve significant improvements on challenging mathematical benchmarks, validating its effectiveness. We release DeepMath-103K publicly to facilitate community progress in building more capable AI reasoning systems: https://github.com/zwhe99/DeepMath.
Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains
Apr 01, 2025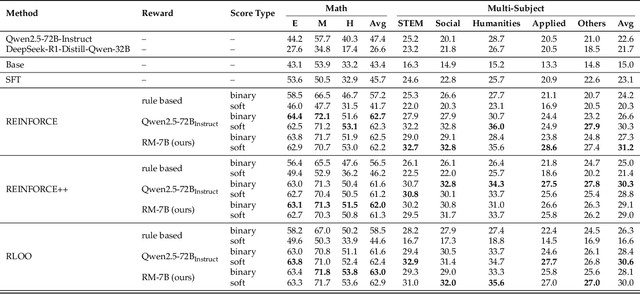
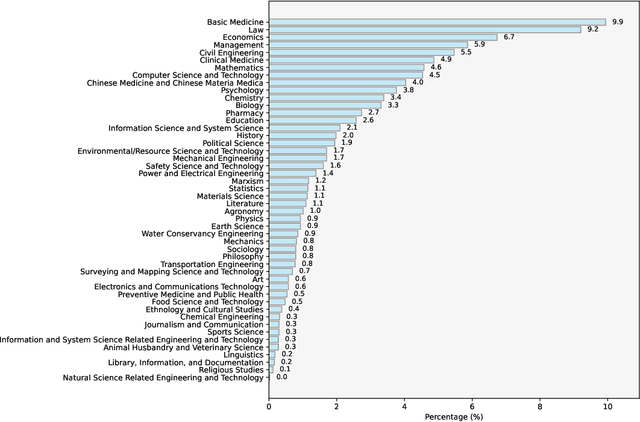
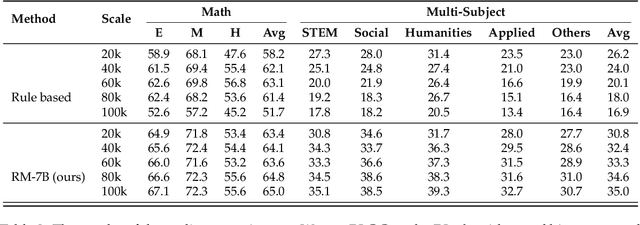

Reinforcement learning with verifiable rewards (RLVR) has demonstrated significant success in enhancing mathematical reasoning and coding performance of large language models (LLMs), especially when structured reference answers are accessible for verification. However, its extension to broader, less structured domains remains unexplored. In this work, we investigate the effectiveness and scalability of RLVR across diverse real-world domains including medicine, chemistry, psychology, economics, and education, where structured reference answers are typically unavailable. We reveal that binary verification judgments on broad-domain tasks exhibit high consistency across various LLMs provided expert-written reference answers exist. Motivated by this finding, we utilize a generative scoring technique that yields soft, model-based reward signals to overcome limitations posed by binary verifications, especially in free-form, unstructured answer scenarios. We further demonstrate the feasibility of training cross-domain generative reward models using relatively small (7B) LLMs without the need for extensive domain-specific annotation. Through comprehensive experiments, our RLVR framework establishes clear performance gains, significantly outperforming state-of-the-art open-source aligned models such as Qwen2.5-72B and DeepSeek-R1-Distill-Qwen-32B across domains in free-form settings. Our approach notably enhances the robustness, flexibility, and scalability of RLVR, representing a substantial step towards practical reinforcement learning applications in complex, noisy-label scenarios.