 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMARIS: A Memory-Augmented Rubric Improvement System for Rubric-Based Reinforcement Learning
May 18, 2026Rubric-based reward shaping is an effective method for fine-tuning LLMs via RL, where structured rubrics decompose standard outcome rewards into multiple dimensions to provide richer reward signals. Recent works make the rubrics adaptive based on local signals such as the rollouts from the current step or pairwise comparisons. However, these methods discard the diagnostics produced during evaluation after immediate use and prevent the long-term accumulation and strategic reuse of evaluation knowledge. This forces the system to re-derive evaluation principles from scratch, limits its ability to detect recurring suboptimal behaviors, and forfeits the curriculum-like progression that a persistent training history would naturally support. To address these limitations, we introduce AMARIS, which grounds rubric modifications in long-term training history. At each training step, AMARIS analyzes individual rollouts, aggregates findings into step-level summaries, retrieves relevant historical context from a persistent evaluation memory through both static (recent steps) and dynamic (semantically matched) retrieval, and updates rubrics based on these accumulated analyses. This procedure runs asynchronously alongside the normal RL loop with minimal overhead. Experiments across both closed and open-ended domains show that AMARIS consistently outperforms the baselines. Ablation studies show that static and dynamic memory retrieval contributes to the performance gain and their combination provides the strongest results with moderate retrieval budgets sufficient to provide most of the gain, and that the entire pipeline adds only ~5\% time overhead through asynchronous execution. These results show that persistent evaluation memory can transform rubric-based reward shaping from a stateless, per-step heuristic into an evidence-driven loop for RL training.
A Skill-augmented Agentic Framework and Benchmark for Multi-Video Understanding
Mar 16, 2026Multimodal Large Language Models have achieved strong performance in single-video understanding, yet their ability to reason across multiple videos remains limited. Existing approaches typically concatenate multiple videos into a single input and perform direct inference, which introduces training-inference mismatch, information loss from frame compression, and a lack of explicit cross-video coordination. Meanwhile, current multi-video benchmarks primarily emphasize event-level comparison, leaving identity-level matching, fine-grained discrimination, and structured multi-step reasoning underexplored. To address these gaps, we introduce MVX-Bench, a Multi-Video Cross-Dimension Benchmark that reformulates 11 classical computer vision tasks into a unified multi-video question-answering framework, comprising 1,442 questions over 4,255 videos from diverse real-world datasets. We further propose SAMA, a Skill-Augmented Agentic Framework for Multi-Video Understanding, which integrates visual tools, task-specific skills, and a conflict-aware verification mechanism to enable iterative and structured reasoning. Experimental results show that SAMA outperforms strong open-source baselines and GPT on MVX-Bench, and ablations validate the effectiveness of skill design and conflict resolution.
Is Grokking Worthwhile? Functional Analysis and Transferability of Generalization Circuits in Transformers
Jan 14, 2026While Large Language Models (LLMs) excel at factual retrieval, they often struggle with the "curse of two-hop reasoning" in compositional tasks. Recent research suggests that parameter-sharing transformers can bridge this gap by forming a "Generalization Circuit" during a prolonged "grokking" phase. A fundamental question arises: Is a grokked model superior to its non-grokked counterparts on downstream tasks? Furthermore, is the extensive computational cost of waiting for the grokking phase worthwhile? In this work, we conduct a mechanistic study to evaluate the Generalization Circuit's role in knowledge assimilation and transfer. We demonstrate that: (i) The inference paths established by non-grokked and grokked models for in-distribution compositional queries are identical. This suggests that the "Generalization Circuit" does not represent the sudden acquisition of a new reasoning paradigm. Instead, we argue that grokking is the process of integrating memorized atomic facts into an naturally established reasoning path. (ii) Achieving high accuracy on unseen cases after prolonged training and the formation of a certain reasoning path are not bound; they can occur independently under specific data regimes. (iii) Even a mature circuit exhibits limited transferability when integrating new knowledge, suggesting that "grokked" Transformers do not achieve a full mastery of compositional logic.
Event Extraction in Large Language Model
Dec 22, 2025Large language models (LLMs) and multimodal LLMs are changing event extraction (EE): prompting and generation can often produce structured outputs in zero shot or few shot settings. Yet LLM based pipelines face deployment gaps, including hallucinations under weak constraints, fragile temporal and causal linking over long contexts and across documents, and limited long horizon knowledge management within a bounded context window. We argue that EE should be viewed as a system component that provides a cognitive scaffold for LLM centered solutions. Event schemas and slot constraints create interfaces for grounding and verification; event centric structures act as controlled intermediate representations for stepwise reasoning; event links support relation aware retrieval with graph based RAG; and event stores offer updatable episodic and agent memory beyond the context window. This survey covers EE in text and multimodal settings, organizing tasks and taxonomy, tracing method evolution from rule based and neural models to instruction driven and generative frameworks, and summarizing formulations, decoding strategies, architectures, representations, datasets, and evaluation. We also review cross lingual, low resource, and domain specific settings, and highlight open challenges and future directions for reliable event centric systems. Finally, we outline open challenges and future directions that are central to the LLM era, aiming to evolve EE from static extraction into a structurally reliable, agent ready perception and memory layer for open world systems.
HiPRAG: Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation
Oct 09, 2025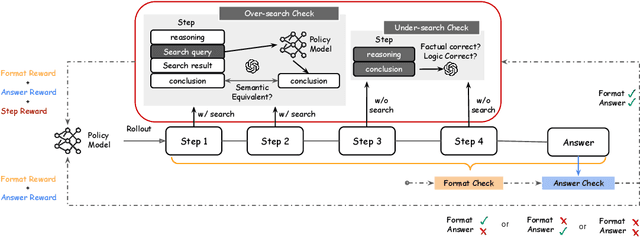
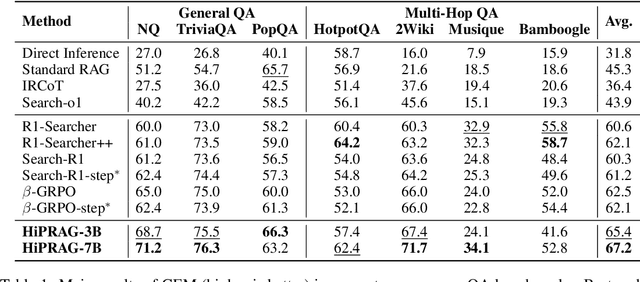
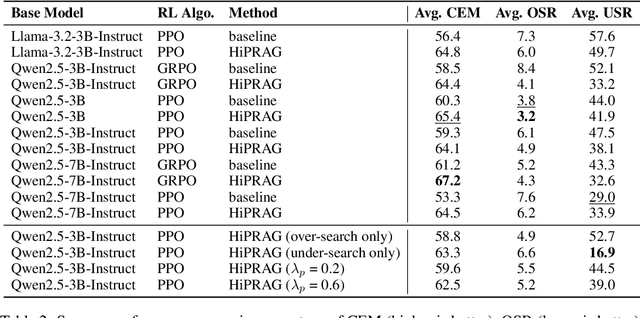
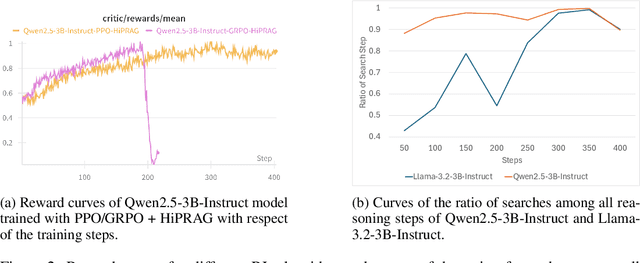
Agentic RAG is a powerful technique for incorporating external information that LLMs lack, enabling better problem solving and question answering. However, suboptimal search behaviors exist widely, such as over-search (retrieving information already known) and under-search (failing to search when necessary), which leads to unnecessary overhead and unreliable outputs. Current training methods, which typically rely on outcome-based rewards in a RL framework, lack the fine-grained control needed to address these inefficiencies. To overcome this, we introduce Hierarchical Process Rewards for Efficient agentic RAG (HiPRAG), a training methodology that incorporates a fine-grained, knowledge-grounded process reward into the RL training. Our approach evaluates the necessity of each search decision on-the-fly by decomposing the agent's reasoning trajectory into discrete, parsable steps. We then apply a hierarchical reward function that provides an additional bonus based on the proportion of optimal search and non-search steps, on top of commonly used outcome and format rewards. Experiments on the Qwen2.5 and Llama-3.2 models across seven diverse QA benchmarks show that our method achieves average accuracies of 65.4% (3B) and 67.2% (7B). This is accomplished while improving search efficiency, reducing the over-search rate to just 2.3% and concurrently lowering the under-search rate. These results demonstrate the efficacy of optimizing the reasoning process itself, not just the final outcome. Further experiments and analysis demonstrate that HiPRAG shows good generalizability across a wide range of RL algorithms, model families, sizes, and types. This work demonstrates the importance and potential of fine-grained control through RL, for improving the efficiency and optimality of reasoning for search agents.
CLUE: Non-parametric Verification from Experience via Hidden-State Clustering
Oct 02, 2025



Assessing the quality of Large Language Model (LLM) outputs presents a critical challenge. Previous methods either rely on text-level information (e.g., reward models, majority voting), which can overfit to superficial cues, or on calibrated confidence from token probabilities, which would fail on less-calibrated models. Yet both of these signals are, in fact, partial projections of a richer source of information: the model's internal hidden states. Early layers, closer to token embeddings, preserve semantic and lexical features that underpin text-based judgments, while later layers increasingly align with output logits, embedding confidence-related information. This paper explores hidden states directly as a unified foundation for verification. We show that the correctness of a solution is encoded as a geometrically separable signature within the trajectory of hidden activations. To validate this, we present Clue (Clustering and Experience-based Verification), a deliberately minimalist, non-parametric verifier. With no trainable parameters, CLUE only summarizes each reasoning trace by an hidden state delta and classifies correctness via nearest-centroid distance to ``success'' and ``failure'' clusters formed from past experience. The simplicity of this method highlights the strength of the underlying signal. Empirically, CLUE consistently outperforms LLM-as-a-judge baselines and matches or exceeds modern confidence-based methods in reranking candidates, improving both top-1 and majority-vote accuracy across AIME 24/25 and GPQA. As a highlight, on AIME 24 with a 1.5B model, CLUE boosts accuracy from 56.7% (majority@64) to 70.0% (top-maj@16).
SciEvent: Benchmarking Multi-domain Scientific Event Extraction
Sep 19, 2025



Scientific information extraction (SciIE) has primarily relied on entity-relation extraction in narrow domains, limiting its applicability to interdisciplinary research and struggling to capture the necessary context of scientific information, often resulting in fragmented or conflicting statements. In this paper, we introduce SciEvent, a novel multi-domain benchmark of scientific abstracts annotated via a unified event extraction (EE) schema designed to enable structured and context-aware understanding of scientific content. It includes 500 abstracts across five research domains, with manual annotations of event segments, triggers, and fine-grained arguments. We define SciIE as a multi-stage EE pipeline: (1) segmenting abstracts into core scientific activities--Background, Method, Result, and Conclusion; and (2) extracting the corresponding triggers and arguments. Experiments with fine-tuned EE models, large language models (LLMs), and human annotators reveal a performance gap, with current models struggling in domains such as sociology and humanities. SciEvent serves as a challenging benchmark and a step toward generalizable, multi-domain SciIE.
FIFA: Unified Faithfulness Evaluation Framework for Text-to-Video and Video-to-Text Generation
Jul 09, 2025

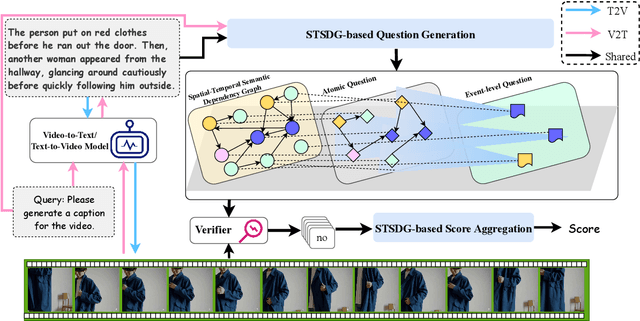
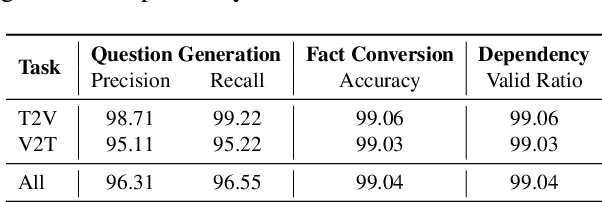
Video Multimodal Large Language Models (VideoMLLMs) have achieved remarkable progress in both Video-to-Text and Text-to-Video tasks. However, they often suffer fro hallucinations, generating content that contradicts the visual input. Existing evaluation methods are limited to one task (e.g., V2T) and also fail to assess hallucinations in open-ended, free-form responses. To address this gap, we propose FIFA, a unified FaIthFulness evAluation framework that extracts comprehensive descriptive facts, models their semantic dependencies via a Spatio-Temporal Semantic Dependency Graph, and verifies them using VideoQA models. We further introduce Post-Correction, a tool-based correction framework that revises hallucinated content. Extensive experiments demonstrate that FIFA aligns more closely with human judgment than existing evaluation methods, and that Post-Correction effectively improves factual consistency in both text and video generation.
Search Wisely: Mitigating Sub-optimal Agentic Searches By Reducing Uncertainty
May 22, 2025



Agentic Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by enabling dynamic, multi-step reasoning and information retrieval. However, these systems often exhibit sub-optimal search behaviors like over-search (retrieving redundant information) and under-search (failing to retrieve necessary information), which hinder efficiency and reliability. This work formally defines and quantifies these behaviors, revealing their prevalence across multiple QA datasets and agentic RAG systems (e.g., one model could have avoided searching in 27.7% of its search steps). Furthermore, we demonstrate a crucial link between these inefficiencies and the models' uncertainty regarding their own knowledge boundaries, where response accuracy correlates with model's uncertainty in its search decisions. To address this, we propose $\beta$-GRPO, a reinforcement learning-based training method that incorporates confidence threshold to reward high-certainty search decisions. Experiments on seven QA benchmarks show that $\beta$-GRPO enable a 3B model with better agentic RAG ability, outperforming other strong baselines with a 4% higher average exact match score.
A Comprehensive Analysis for Visual Object Hallucination in Large Vision-Language Models
May 04, 2025
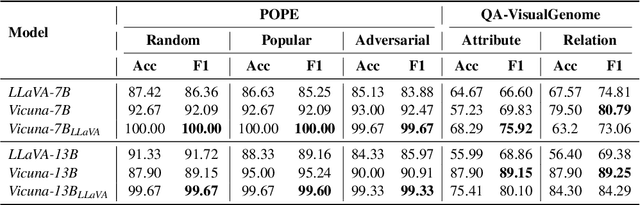


Large Vision-Language Models (LVLMs) demonstrate remarkable capabilities in multimodal tasks, but visual object hallucination remains a persistent issue. It refers to scenarios where models generate inaccurate visual object-related information based on the query input, potentially leading to misinformation and concerns about safety and reliability. Previous works focus on the evaluation and mitigation of visual hallucinations, but the underlying causes have not been comprehensively investigated. In this paper, we analyze each component of LLaVA-like LVLMs -- the large language model, the vision backbone, and the projector -- to identify potential sources of error and their impact. Based on our observations, we propose methods to mitigate hallucination for each problematic component. Additionally, we developed two hallucination benchmarks: QA-VisualGenome, which emphasizes attribute and relation hallucinations, and QA-FB15k, which focuses on cognition-based hallucinations.