 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaRubric: Generative Multimodal Reward Modeling via Joint Planning and Verification
May 10, 2026Aligning Multimodal Large Language Models (MLLMs) requires reliable reward models, yet existing single-step evaluators can suffer from lazy judging, exploiting language priors over fine-grained visual verification. While rubric-based evaluation mitigates these biases in text-only settings, extending it to multimodal tasks is bottlenecked by the complexity of visual reasoning. The critical differences between responses often depend on instance-specific visual details. Robust evaluation requires dynamically synthesizing rubrics that isolate spatial and factual discrepancies. To address this, we introduce $\textbf{DeltaRubric}$, an approach that reformulates multimodal preference evaluation as a plan-and-execute process within a single MLLM. DeltaRubric operates in two steps: acting first as a $\textit{Disagreement Planner}$, the model generates a neutral, instance-specific verification checklist. Transitioning into a $\textit{Checklist Verifier}$, it executes these self-generated checks against the image and question to produce the final grounded judgment. We formulate DeltaRubric as a multi-role reinforcement learning problem, jointly optimizing planning and verification capabilities. Validated on Qwen3-VL 4B and 8B Instruct models, DeltaRubric achieves solid empirical gains. For instance, On VL-RewardBench, it improves base model overall accuracy by $\textbf{+22.6}$ (4B) and $\textbf{+18.8}$ (8B) points, largely outperforming standard no-rubric baselines. The results demonstrate that decomposing evaluation into structured, verifiable steps leads to more reliable and generalizable multimodal reward modeling.
Reinforcing Multimodal Reasoning Against Visual Degradation
May 10, 2026Reinforcement Learning has significantly advanced the reasoning capabilities of Multimodal Large Language Models (MLLMs), yet the resulting policies remain brittle against real-world visual degradations such as blur, compression artifacts, and low-resolution scans. Prior robustness techniques from vision and deep RL rely on static data augmentation or value-based regularization, neither of which transfers cleanly to critic-free RL fine-tuning of autoregressive MLLMs. Reinforcing reasoning against such corruptions is non-trivial: naively injecting degraded views during rollout induces reward poisoning, where perceptual occlusions trigger hallucinated trajectories and destabilize optimization. We propose ROMA, an RL fine-tuning framework that modifies the optimization dynamics to reinforce reasoning against visual degradation while preserving clean-input performance. A dual-forward-pass strategy uses teacher forcing to evaluate corrupted views against clean-image trajectories, avoiding new rollouts on degraded inputs. For distributional consistency, we apply a token-level surrogate KL penalty against the worst-case augmentation; to prevent policy collapse under regularization, an auxiliary policy gradient loss anchored to clean-image advantages preserves a reliable reward signal; and to avoid systematically incorrect invariance, correctness-conditioned regularization restricts enforcement to successful trajectories. On Qwen3-VL 4B/8B across seven multimodal reasoning benchmarks, our method improves robustness by +2.4% on seen and +2.3% on unseen corruptions over GRPO while matching clean accuracy.
Zero Shot Coordination for Sparse Reward Tasks with Diverse Reward Shapings
Apr 28, 2026Many Multi-Agent Reinforcement Learning (MARL) agents fail to adapt properly to cooperating with agents trained with the same objectives but different seeds, algorithms, or other training differences. This is the problem of Zero-Shot Coordination (ZSC), which focuses on training agents to cooperate well with unknown agents. ZSC has been studied for a variety of tabular cases and simple games such as Hanabi, achieving excellent results. However, existing solutions to ZSC only consider identical rewards for your trained agents and all future partners. This is not realistic for the trained agents, as they do not consider the problem of cooperating with agents that have identical sparse objectives but shape the rewards for those objectives in different manner. To address this issue, we show how to train an ensemble of methods using randomized reward shapings chosen using 4 selection algorithms. Experiments done on the Overcooked environment demonstrate consistent improvements of 62.2%-119.2% in sparse reward over baseline ZSC algorithms when playing with agents that have identical sparse rewards but different reward shapings.
WESPR: Wind-adaptive Energy-Efficient Safe Perception & Planning for Robust Flight with Quadrotors
Mar 10, 2026Local wind conditions strongly influence drone performance: headwinds increase flight time, crosswinds and wind shear hinder agility in cluttered spaces, while tailwinds reduce travel time. Although adaptive controllers can mitigate turbulence, they remain unaware of the surrounding geometry that generates it, preventing proactive avoidance. Existing methods that model how wind interacts with the environment typically rely on computationally expensive fluid dynamics simulations, limiting real-time adaptation to new environments and conditions. To bridge this gap, we present WESPR, a fast framework that predicts how environmental geometry affects local wind conditions, enabling proactive path planning and control adaptation. Our lightweight pipeline integrates geometric perception and local weather data to estimate wind fields, compute cost-efficient paths, and adjust control strategies-all within 10 seconds. We validate WESPR on a Crazyflie drone navigating turbulent obstacle courses. Our results show a 12.5-58.7% reduction in maximum trajectory deviation and a 24.6% improvement in stability compared to a wind-agnostic adaptive controller.
Active Asymmetric Multi-Agent Multimodal Learning under Uncertainty
Feb 04, 2026Multi-agent systems are increasingly equipped with heterogeneous multimodal sensors, enabling richer perception but introducing modality-specific and agent-dependent uncertainty. Existing multi-agent collaboration frameworks typically reason at the agent level, assume homogeneous sensing, and handle uncertainty implicitly, limiting robustness under sensor corruption. We propose Active Asymmetric Multi-Agent Multimodal Learning under Uncertainty (A2MAML), a principled approach for uncertainty-aware, modality-level collaboration. A2MAML models each modality-specific feature as a stochastic estimate with uncertainty prediction, actively selects reliable agent-modality pairs, and aggregates information via Bayesian inverse-variance weighting. This formulation enables fine-grained, modality-level fusion, supports asymmetric modality availability, and provides a principled mechanism to suppress corrupted or noisy modalities. Extensive experiments on connected autonomous driving scenarios for collaborative accident detection demonstrate that A2MAML consistently outperforms both single-agent and collaborative baselines, achieving up to 18.7% higher accident detection rate.
PRISM: Performer RS-IMLE for Single-pass Multisensory Imitation Learning
Feb 02, 2026Robotic imitation learning typically requires models that capture multimodal action distributions while operating at real-time control rates and accommodating multiple sensing modalities. Although recent generative approaches such as diffusion models, flow matching, and Implicit Maximum Likelihood Estimation (IMLE) have achieved promising results, they often satisfy only a subset of these requirements. To address this, we introduce PRISM, a single-pass policy based on a batch-global rejection-sampling variant of IMLE. PRISM couples a temporal multisensory encoder (integrating RGB, depth, tactile, audio, and proprioception) with a linear-attention generator using a Performer architecture. We demonstrate the efficacy of PRISM on a diverse real-world hardware suite, including loco-manipulation using a Unitree Go2 with a 7-DoF arm D1 and tabletop manipulation with a UR5 manipulator. Across challenging physical tasks such as pre-manipulation parking, high-precision insertion, and multi-object pick-and-place, PRISM outperforms state-of-the-art diffusion policies by 10-25% in success rate while maintaining high-frequency (30-50 Hz) closed-loop control. We further validate our approach on large-scale simulation benchmarks, including CALVIN, MetaWorld, and Robomimic. In CALVIN (10% data split), PRISM improves success rates by approximately 25% over diffusion and approximately 20% over flow matching, while simultaneously reducing trajectory jerk by 20x-50x. These results position PRISM as a fast, accurate, and multisensory imitation policy that retains multimodal action coverage without the latency of iterative sampling.
Stable and Efficient Single-Rollout RL for Multimodal Reasoning
Dec 20, 2025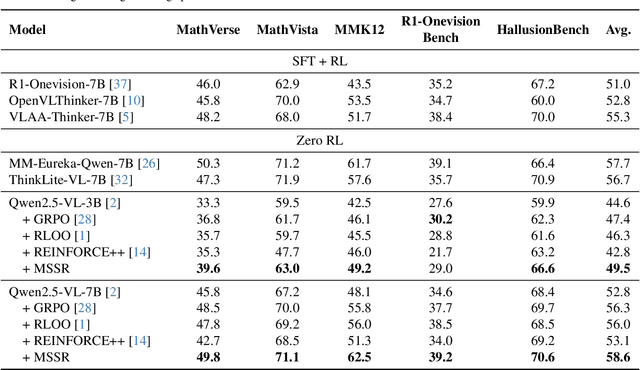
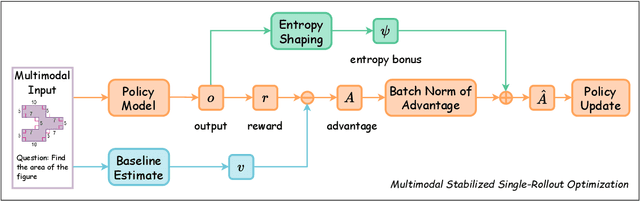

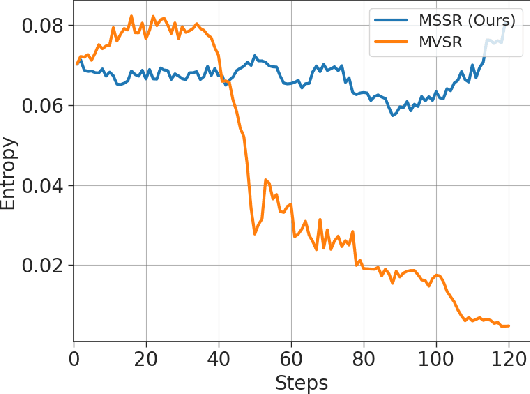
Reinforcement Learning with Verifiable Rewards (RLVR) has become a key paradigm to improve the reasoning capabilities of Multimodal Large Language Models (MLLMs). However, prevalent group-based algorithms such as GRPO require multi-rollout sampling for each prompt. While more efficient single-rollout variants have recently been explored in text-only settings, we find that they suffer from severe instability in multimodal contexts, often leading to training collapse. To address this training efficiency-stability trade-off, we introduce $\textbf{MSSR}$ (Multimodal Stabilized Single-Rollout), a group-free RLVR framework that achieves both stable optimization and effective multimodal reasoning performance. MSSR achieves this via an entropy-based advantage-shaping mechanism that adaptively regularizes advantage magnitudes, preventing collapse and maintaining training stability. While such mechanisms have been used in group-based RLVR, we show that in the multimodal single-rollout setting they are not merely beneficial but essential for stability. In in-distribution evaluations, MSSR demonstrates superior training compute efficiency, achieving similar validation accuracy to the group-based baseline with half the training steps. When trained for the same number of steps, MSSR's performance surpasses the group-based baseline and shows consistent generalization improvements across five diverse reasoning-intensive benchmarks. Together, these results demonstrate that MSSR enables stable, compute-efficient, and effective RLVR for complex multimodal reasoning tasks.
AFFORD2ACT: Affordance-Guided Automatic Keypoint Selection for Generalizable and Lightweight Robotic Manipulation
Oct 01, 2025Vision-based robot learning often relies on dense image or point-cloud inputs, which are computationally heavy and entangle irrelevant background features. Existing keypoint-based approaches can focus on manipulation-centric features and be lightweight, but either depend on manual heuristics or task-coupled selection, limiting scalability and semantic understanding. To address this, we propose AFFORD2ACT, an affordance-guided framework that distills a minimal set of semantic 2D keypoints from a text prompt and a single image. AFFORD2ACT follows a three-stage pipeline: affordance filtering, category-level keypoint construction, and transformer-based policy learning with embedded gating to reason about the most relevant keypoints, yielding a compact 38-dimensional state policy that can be trained in 15 minutes, which performs well in real-time without proprioception or dense representations. Across diverse real-world manipulation tasks, AFFORD2ACT consistently improves data efficiency, achieving an 82% success rate on unseen objects, novel categories, backgrounds, and distractors.
VOGUE: Guiding Exploration with Visual Uncertainty Improves Multimodal Reasoning
Oct 01, 2025



Reinforcement learning with verifiable rewards (RLVR) improves reasoning in large language models (LLMs) but struggles with exploration, an issue that still persists for multimodal LLMs (MLLMs). Current methods treat the visual input as a fixed, deterministic condition, overlooking a critical source of ambiguity and struggling to build policies robust to plausible visual variations. We introduce $\textbf{VOGUE (Visual Uncertainty Guided Exploration)}$, a novel method that shifts exploration from the output (text) to the input (visual) space. By treating the image as a stochastic context, VOGUE quantifies the policy's sensitivity to visual perturbations using the symmetric KL divergence between a "raw" and "noisy" branch, creating a direct signal for uncertainty-aware exploration. This signal shapes the learning objective via an uncertainty-proportional bonus, which, combined with a token-entropy bonus and an annealed sampling schedule, effectively balances exploration and exploitation. Implemented within GRPO on two model scales (Qwen2.5-VL-3B/7B), VOGUE boosts pass@1 accuracy by an average of 2.6% on three visual math benchmarks and 3.7% on three general-domain reasoning benchmarks, while simultaneously increasing pass@4 performance and mitigating the exploration decay commonly observed in RL fine-tuning. Our work shows that grounding exploration in the inherent uncertainty of visual inputs is an effective strategy for improving multimodal reasoning.
Multi-Agent Trust Region Policy Optimisation: A Joint Constraint Approach
Aug 14, 2025Multi-agent reinforcement learning (MARL) requires coordinated and stable policy updates among interacting agents. Heterogeneous-Agent Trust Region Policy Optimization (HATRPO) enforces per-agent trust region constraints using Kullback-Leibler (KL) divergence to stabilize training. However, assigning each agent the same KL threshold can lead to slow and locally optimal updates, especially in heterogeneous settings. To address this limitation, we propose two approaches for allocating the KL divergence threshold across agents: HATRPO-W, a Karush-Kuhn-Tucker-based (KKT-based) method that optimizes threshold assignment under global KL constraints, and HATRPO-G, a greedy algorithm that prioritizes agents based on improvement-to-divergence ratio. By connecting sequential policy optimization with constrained threshold scheduling, our approach enables more flexible and effective learning in heterogeneous-agent settings. Experimental results demonstrate that our methods significantly boost the performance of HATRPO, achieving faster convergence and higher final rewards across diverse MARL benchmarks. Specifically, HATRPO-W and HATRPO-G achieve comparable improvements in final performance, each exceeding 22.5%. Notably, HATRPO-W also demonstrates more stable learning dynamics, as reflected by its lower variance.