 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
Dec 29, 2023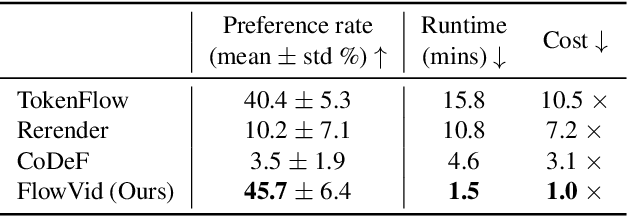

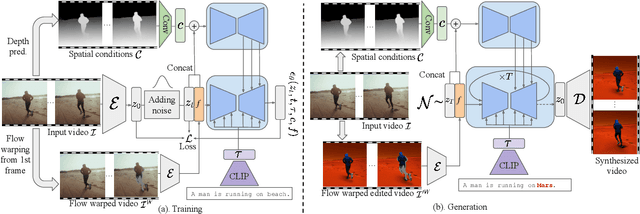

Diffusion models have transformed the image-to-image (I2I) synthesis and are now permeating into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames. This paper proposes a consistent V2V synthesis framework by jointly leveraging spatial conditions and temporal optical flow clues within the source video. Contrary to prior methods that strictly adhere to optical flow, our approach harnesses its benefits while handling the imperfection in flow estimation. We encode the optical flow via warping from the first frame and serve it as a supplementary reference in the diffusion model. This enables our model for video synthesis by editing the first frame with any prevalent I2I models and then propagating edits to successive frames. Our V2V model, FlowVid, demonstrates remarkable properties: (1) Flexibility: FlowVid works seamlessly with existing I2I models, facilitating various modifications, including stylization, object swaps, and local edits. (2) Efficiency: Generation of a 4-second video with 30 FPS and 512x512 resolution takes only 1.5 minutes, which is 3.1x, 7.2x, and 10.5x faster than CoDeF, Rerender, and TokenFlow, respectively. (3) High-quality: In user studies, our FlowVid is preferred 45.7% of the time, outperforming CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).
Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis
Dec 20, 2023



In this paper, we introduce Fairy, a minimalist yet robust adaptation of image-editing diffusion models, enhancing them for video editing applications. Our approach centers on the concept of anchor-based cross-frame attention, a mechanism that implicitly propagates diffusion features across frames, ensuring superior temporal coherence and high-fidelity synthesis. Fairy not only addresses limitations of previous models, including memory and processing speed. It also improves temporal consistency through a unique data augmentation strategy. This strategy renders the model equivariant to affine transformations in both source and target images. Remarkably efficient, Fairy generates 120-frame 512x384 videos (4-second duration at 30 FPS) in just 14 seconds, outpacing prior works by at least 44x. A comprehensive user study, involving 1000 generated samples, confirms that our approach delivers superior quality, decisively outperforming established methods.
AVID: Any-Length Video Inpainting with Diffusion Model
Dec 06, 2023



Recent advances in diffusion models have successfully enabled text-guided image inpainting. While it seems straightforward to extend such editing capability into video domain, there has been fewer works regarding text-guided video inpainting. Given a video, a masked region at its initial frame, and an editing prompt, it requires a model to do infilling at each frame following the editing guidance while keeping the out-of-mask region intact. There are three main challenges in text-guided video inpainting: ($i$) temporal consistency of the edited video, ($ii$) supporting different inpainting types at different structural fidelity level, and ($iii$) dealing with variable video length. To address these challenges, we introduce Any-Length Video Inpainting with Diffusion Model, dubbed as AVID. At its core, our model is equipped with effective motion modules and adjustable structure guidance, for fixed-length video inpainting. Building on top of that, we propose a novel Temporal MultiDiffusion sampling pipeline with an middle-frame attention guidance mechanism, facilitating the generation of videos with any desired duration. Our comprehensive experiments show our model can robustly deal with various inpainting types at different video duration range, with high quality. More visualization results is made publicly available at https://zhang-zx.github.io/AVID/ .
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence
Dec 05, 2023



Current diffusion-based video editing primarily focuses on structure-preserved editing by utilizing various dense correspondences to ensure temporal consistency and motion alignment. However, these approaches are often ineffective when the target edit involves a shape change. To embark on video editing with shape change, we explore customized video subject swapping in this work, where we aim to replace the main subject in a source video with a target subject having a distinct identity and potentially different shape. In contrast to previous methods that rely on dense correspondences, we introduce the VideoSwap framework that exploits semantic point correspondences, inspired by our observation that only a small number of semantic points are necessary to align the subject's motion trajectory and modify its shape. We also introduce various user-point interactions (\eg, removing points and dragging points) to address various semantic point correspondence. Extensive experiments demonstrate state-of-the-art video subject swapping results across a variety of real-world videos.
Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression
Nov 17, 2023



We introduce Style Tailoring, a recipe to finetune Latent Diffusion Models (LDMs) in a distinct domain with high visual quality, prompt alignment and scene diversity. We choose sticker image generation as the target domain, as the images significantly differ from photorealistic samples typically generated by large-scale LDMs. We start with a competent text-to-image model, like Emu, and show that relying on prompt engineering with a photorealistic model to generate stickers leads to poor prompt alignment and scene diversity. To overcome these drawbacks, we first finetune Emu on millions of sticker-like images collected using weak supervision to elicit diversity. Next, we curate human-in-the-loop (HITL) Alignment and Style datasets from model generations, and finetune to improve prompt alignment and style alignment respectively. Sequential finetuning on these datasets poses a tradeoff between better style alignment and prompt alignment gains. To address this tradeoff, we propose a novel fine-tuning method called Style Tailoring, which jointly fits the content and style distribution and achieves best tradeoff. Evaluation results show our method improves visual quality by 14%, prompt alignment by 16.2% and scene diversity by 15.3%, compared to prompt engineering the base Emu model for stickers generation.
AMELI: Enhancing Multimodal Entity Linking with Fine-Grained Attributes
May 24, 2023



We propose attribute-aware multimodal entity linking, where the input is a mention described with a text and image, and the goal is to predict the corresponding target entity from a multimodal knowledge base (KB) where each entity is also described with a text description, a visual image and a set of attributes and values. To support this research, we construct AMELI, a large-scale dataset consisting of 18,472 reviews and 35,598 products. To establish baseline performance on AMELI, we experiment with the current state-of-the-art multimodal entity linking approaches and our enhanced attribute-aware model and demonstrate the importance of incorporating the attribute information into the entity linking process. To be best of our knowledge, we are the first to build benchmark dataset and solutions for the attribute-aware multimodal entity linking task. Datasets and codes will be made publicly available.
Learning Procedure-aware Video Representation from Instructional Videos and Their Narrations
Mar 31, 2023The abundance of instructional videos and their narrations over the Internet offers an exciting avenue for understanding procedural activities. In this work, we propose to learn video representation that encodes both action steps and their temporal ordering, based on a large-scale dataset of web instructional videos and their narrations, without using human annotations. Our method jointly learns a video representation to encode individual step concepts, and a deep probabilistic model to capture both temporal dependencies and immense individual variations in the step ordering. We empirically demonstrate that learning temporal ordering not only enables new capabilities for procedure reasoning, but also reinforces the recognition of individual steps. Our model significantly advances the state-of-the-art results on step classification (+2.8% / +3.3% on COIN / EPIC-Kitchens) and step forecasting (+7.4% on COIN). Moreover, our model attains promising results in zero-shot inference for step classification and forecasting, as well as in predicting diverse and plausible steps for incomplete procedures. Our code is available at https://github.com/facebookresearch/ProcedureVRL.
Learning and Verification of Task Structure in Instructional Videos
Mar 23, 2023



Given the enormous number of instructional videos available online, learning a diverse array of multi-step task models from videos is an appealing goal. We introduce a new pre-trained video model, VideoTaskformer, focused on representing the semantics and structure of instructional videos. We pre-train VideoTaskformer using a simple and effective objective: predicting weakly supervised textual labels for steps that are randomly masked out from an instructional video (masked step modeling). Compared to prior work which learns step representations locally, our approach involves learning them globally, leveraging video of the entire surrounding task as context. From these learned representations, we can verify if an unseen video correctly executes a given task, as well as forecast which steps are likely to be taken after a given step. We introduce two new benchmarks for detecting mistakes in instructional videos, to verify if there is an anomalous step and if steps are executed in the right order. We also introduce a long-term forecasting benchmark, where the goal is to predict long-range future steps from a given step. Our method outperforms previous baselines on these tasks, and we believe the tasks will be a valuable way for the community to measure the quality of step representations. Additionally, we evaluate VideoTaskformer on 3 existing benchmarks -- procedural activity recognition, step classification, and step forecasting -- and demonstrate on each that our method outperforms existing baselines and achieves new state-of-the-art performance.
FAME-ViL: Multi-Tasking Vision-Language Model for Heterogeneous Fashion Tasks
Mar 04, 2023In the fashion domain, there exists a variety of vision-and-language (V+L) tasks, including cross-modal retrieval, text-guided image retrieval, multi-modal classification, and image captioning. They differ drastically in each individual input/output format and dataset size. It has been common to design a task-specific model and fine-tune it independently from a pre-trained V+L model (e.g., CLIP). This results in parameter inefficiency and inability to exploit inter-task relatedness. To address such issues, we propose a novel FAshion-focused Multi-task Efficient learning method for Vision-and-Language tasks (FAME-ViL) in this work. Compared with existing approaches, FAME-ViL applies a single model for multiple heterogeneous fashion tasks, therefore being much more parameter-efficient. It is enabled by two novel components: (1) a task-versatile architecture with cross-attention adapters and task-specific adapters integrated into a unified V+L model, and (2) a stable and effective multi-task training strategy that supports learning from heterogeneous data and prevents negative transfer. Extensive experiments on four fashion tasks show that our FAME-ViL can save 61.5% of parameters over alternatives, while significantly outperforming the conventional independently trained single-task models. Code is available at https://github.com/BrandonHanx/FAME-ViL.
RoPAWS: Robust Semi-supervised Representation Learning from Uncurated Data
Feb 28, 2023



Semi-supervised learning aims to train a model using limited labels. State-of-the-art semi-supervised methods for image classification such as PAWS rely on self-supervised representations learned with large-scale unlabeled but curated data. However, PAWS is often less effective when using real-world unlabeled data that is uncurated, e.g., contains out-of-class data. We propose RoPAWS, a robust extension of PAWS that can work with real-world unlabeled data. We first reinterpret PAWS as a generative classifier that models densities using kernel density estimation. From this probabilistic perspective, we calibrate its prediction based on the densities of labeled and unlabeled data, which leads to a simple closed-form solution from the Bayes' rule. We demonstrate that RoPAWS significantly improves PAWS for uncurated Semi-iNat by +5.3% and curated ImageNet by +0.4%.