 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Dataset Generation for Zero-Shot Stereo Matching
Apr 23, 2025Synthetic datasets are a crucial ingredient for training stereo matching networks, but the question of what makes a stereo dataset effective remains largely unexplored. We investigate the design space of synthetic datasets by varying the parameters of a procedural dataset generator, and report the effects on zero-shot stereo matching performance using standard benchmarks. We collect the best settings to produce Infinigen-Stereo, a procedural generator specifically optimized for zero-shot stereo datasets. Models trained only on data from our system outperform robust baselines trained on a combination of existing synthetic datasets and have stronger zero-shot stereo matching performance than public checkpoints from prior works. We open source our system at https://github.com/princeton-vl/InfinigenStereo to enable further research on procedural stereo datasets.
Learnings from Scaling Visual Tokenizers for Reconstruction and Generation
Jan 16, 2025



Visual tokenization via auto-encoding empowers state-of-the-art image and video generative models by compressing pixels into a latent space. Although scaling Transformer-based generators has been central to recent advances, the tokenizer component itself is rarely scaled, leaving open questions about how auto-encoder design choices influence both its objective of reconstruction and downstream generative performance. Our work aims to conduct an exploration of scaling in auto-encoders to fill in this blank. To facilitate this exploration, we replace the typical convolutional backbone with an enhanced Vision Transformer architecture for Tokenization (ViTok). We train ViTok on large-scale image and video datasets far exceeding ImageNet-1K, removing data constraints on tokenizer scaling. We first study how scaling the auto-encoder bottleneck affects both reconstruction and generation -- and find that while it is highly correlated with reconstruction, its relationship with generation is more complex. We next explored the effect of separately scaling the auto-encoders' encoder and decoder on reconstruction and generation performance. Crucially, we find that scaling the encoder yields minimal gains for either reconstruction or generation, while scaling the decoder boosts reconstruction but the benefits for generation are mixed. Building on our exploration, we design ViTok as a lightweight auto-encoder that achieves competitive performance with state-of-the-art auto-encoders on ImageNet-1K and COCO reconstruction tasks (256p and 512p) while outperforming existing auto-encoders on 16-frame 128p video reconstruction for UCF-101, all with 2-5x fewer FLOPs. When integrated with Diffusion Transformers, ViTok demonstrates competitive performance on image generation for ImageNet-1K and sets new state-of-the-art benchmarks for class-conditional video generation on UCF-101.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation
Jun 17, 2024



We introduce Infinigen Indoors, a Blender-based procedural generator of photorealistic indoor scenes. It builds upon the existing Infinigen system, which focuses on natural scenes, but expands its coverage to indoor scenes by introducing a diverse library of procedural indoor assets, including furniture, architecture elements, appliances, and other day-to-day objects. It also introduces a constraint-based arrangement system, which consists of a domain-specific language for expressing diverse constraints on scene composition, and a solver that generates scene compositions that maximally satisfy the constraints. We provide an export tool that allows the generated 3D objects and scenes to be directly used for training embodied agents in real-time simulators such as Omniverse and Unreal. Infinigen Indoors is open-sourced under the BSD license. Please visit https://infinigen.org for code and videos.
Whole-body Humanoid Robot Locomotion with Human Reference
Mar 01, 2024



Recently, humanoid robots have made significant advances in their ability to perform challenging tasks due to the deployment of Reinforcement Learning (RL), however, the inherent complexity of humanoid robots, including the difficulty of designing complicated reward functions and training entire sophisticated systems, still poses a notable challenge. To conquer these challenges, after many iterations and in-depth investigations, we have meticulously developed a full-size humanoid robot, "Adam", whose innovative structural design greatly improves the efficiency and effectiveness of the imitation learning process. In addition, we have developed a novel imitation learning framework based on an adversarial motion prior, which applies not only to Adam but also to humanoid robots in general. Using the framework, Adam can exhibit unprecedented human-like characteristics in locomotion tasks. Our experimental results demonstrate that the proposed framework enables Adam to achieve human-comparable performance in complex locomotion tasks, marking the first time that human locomotion data has been used for imitation learning in a full-size humanoid robot.
Animated Stickers: Bringing Stickers to Life with Video Diffusion
Feb 08, 2024



We introduce animated stickers, a video diffusion model which generates an animation conditioned on a text prompt and static sticker image. Our model is built on top of the state-of-the-art Emu text-to-image model, with the addition of temporal layers to model motion. Due to the domain gap, i.e. differences in visual and motion style, a model which performed well on generating natural videos can no longer generate vivid videos when applied to stickers. To bridge this gap, we employ a two-stage finetuning pipeline: first with weakly in-domain data, followed by human-in-the-loop (HITL) strategy which we term ensemble-of-teachers. It distills the best qualities of multiple teachers into a smaller student model. We show that this strategy allows us to specifically target improvements to motion quality while maintaining the style from the static image. With inference optimizations, our model is able to generate an eight-frame video with high-quality, interesting, and relevant motion in under one second.
Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression
Nov 17, 2023



We introduce Style Tailoring, a recipe to finetune Latent Diffusion Models (LDMs) in a distinct domain with high visual quality, prompt alignment and scene diversity. We choose sticker image generation as the target domain, as the images significantly differ from photorealistic samples typically generated by large-scale LDMs. We start with a competent text-to-image model, like Emu, and show that relying on prompt engineering with a photorealistic model to generate stickers leads to poor prompt alignment and scene diversity. To overcome these drawbacks, we first finetune Emu on millions of sticker-like images collected using weak supervision to elicit diversity. Next, we curate human-in-the-loop (HITL) Alignment and Style datasets from model generations, and finetune to improve prompt alignment and style alignment respectively. Sequential finetuning on these datasets poses a tradeoff between better style alignment and prompt alignment gains. To address this tradeoff, we propose a novel fine-tuning method called Style Tailoring, which jointly fits the content and style distribution and achieves best tradeoff. Evaluation results show our method improves visual quality by 14%, prompt alignment by 16.2% and scene diversity by 15.3%, compared to prompt engineering the base Emu model for stickers generation.
A Tour of Visualization Techniques for Computer Vision Datasets
Apr 19, 2022
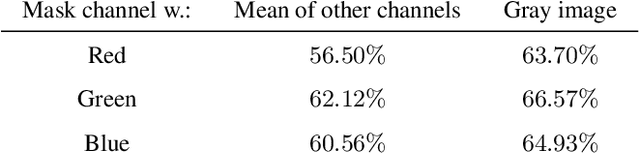

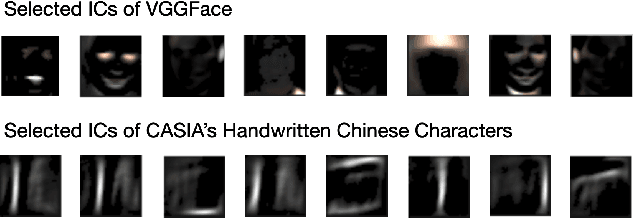
We survey a number of data visualization techniques for analyzing Computer Vision (CV) datasets. These techniques help us understand properties and latent patterns in such data, by applying dataset-level analysis. We present various examples of how such analysis helps predict the potential impact of the dataset properties on CV models and informs appropriate mitigation of their shortcomings. Finally, we explore avenues for further visualization techniques of different modalities of CV datasets as well as ones that are tailored to support specific CV tasks and analysis needs.