 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Grasping via Multimodal Large Language Model
Feb 09, 2024



Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
GIR: 3D Gaussian Inverse Rendering for Relightable Scene Factorization
Dec 08, 2023



This paper presents GIR, a 3D Gaussian Inverse Rendering method for relightable scene factorization. Compared to existing methods leveraging discrete meshes or neural implicit fields for inverse rendering, our method utilizes 3D Gaussians to estimate the material properties, illumination, and geometry of an object from multi-view images. Our study is motivated by the evidence showing that 3D Gaussian is a more promising backbone than neural fields in terms of performance, versatility, and efficiency. In this paper, we aim to answer the question: ``How can 3D Gaussian be applied to improve the performance of inverse rendering?'' To address the complexity of estimating normals based on discrete and often in-homogeneous distributed 3D Gaussian representations, we proposed an efficient self-regularization method that facilitates the modeling of surface normals without the need for additional supervision. To reconstruct indirect illumination, we propose an approach that simulates ray tracing. Extensive experiments demonstrate our proposed GIR's superior performance over existing methods across multiple tasks on a variety of widely used datasets in inverse rendering. This substantiates its efficacy and broad applicability, highlighting its potential as an influential tool in relighting and reconstruction. Project page: https://3dgir.github.io
DGNR: Density-Guided Neural Point Rendering of Large Driving Scenes
Nov 28, 2023



Despite the recent success of Neural Radiance Field (NeRF), it is still challenging to render large-scale driving scenes with long trajectories, particularly when the rendering quality and efficiency are in high demand. Existing methods for such scenes usually involve with spatial warping, geometric supervision from zero-shot normal or depth estimation, or scene division strategies, where the synthesized views are often blurry or fail to meet the requirement of efficient rendering. To address the above challenges, this paper presents a novel framework that learns a density space from the scenes to guide the construction of a point-based renderer, dubbed as DGNR (Density-Guided Neural Rendering). In DGNR, geometric priors are no longer needed, which can be intrinsically learned from the density space through volumetric rendering. Specifically, we make use of a differentiable renderer to synthesize images from the neural density features obtained from the learned density space. A density-based fusion module and geometric regularization are proposed to optimize the density space. By conducting experiments on a widely used autonomous driving dataset, we have validated the effectiveness of DGNR in synthesizing photorealistic driving scenes and achieving real-time capable rendering.
Interpretable and Flexible Target-Conditioned Neural Planners For Autonomous Vehicles
Sep 23, 2023Learning-based approaches to autonomous vehicle planners have the potential to scale to many complicated real-world driving scenarios by leveraging huge amounts of driver demonstrations. However, prior work only learns to estimate a single planning trajectory, while there may be multiple acceptable plans in real-world scenarios. To solve the problem, we propose an interpretable neural planner to regress a heatmap, which effectively represents multiple potential goals in the bird's-eye view of an autonomous vehicle. The planner employs an adaptive Gaussian kernel and relaxed hourglass loss to better capture the uncertainty of planning problems. We also use a negative Gaussian kernel to add supervision to the heatmap regression, enabling the model to learn collision avoidance effectively. Our systematic evaluation on the Lyft Open Dataset across a diverse range of real-world driving scenarios shows that our model achieves a safer and more flexible driving performance than prior works.
Digging into Depth Priors for Outdoor Neural Radiance Fields
Aug 08, 2023Neural Radiance Fields (NeRF) have demonstrated impressive performance in vision and graphics tasks, such as novel view synthesis and immersive reality. However, the shape-radiance ambiguity of radiance fields remains a challenge, especially in the sparse viewpoints setting. Recent work resorts to integrating depth priors into outdoor NeRF training to alleviate the issue. However, the criteria for selecting depth priors and the relative merits of different priors have not been thoroughly investigated. Moreover, the relative merits of selecting different approaches to use the depth priors is also an unexplored problem. In this paper, we provide a comprehensive study and evaluation of employing depth priors to outdoor neural radiance fields, covering common depth sensing technologies and most application ways. Specifically, we conduct extensive experiments with two representative NeRF methods equipped with four commonly-used depth priors and different depth usages on two widely used outdoor datasets. Our experimental results reveal several interesting findings that can potentially benefit practitioners and researchers in training their NeRF models with depth priors. Project Page: https://cwchenwang.github.io/outdoor-nerf-depth
MapNeRF: Incorporating Map Priors into Neural Radiance Fields for Driving View Simulation
Aug 06, 2023



Simulating camera sensors is a crucial task in autonomous driving. Although neural radiance fields are exceptional at synthesizing photorealistic views in driving simulations, they still fail to generate extrapolated views. This paper proposes to incorporate map priors into neural radiance fields to synthesize out-of-trajectory driving views with semantic road consistency. The key insight is that map information can be utilized as a prior to guiding the training of the radiance fields with uncertainty. Specifically, we utilize the coarse ground surface as uncertain information to supervise the density field and warp depth with uncertainty from unknown camera poses to ensure multi-view consistency. Experimental results demonstrate that our approach can produce semantic consistency in deviated views for vehicle camera simulation. The supplementary video can be viewed at https://youtu.be/jEQWr-Rfh3A.
Digging Into Uncertainty-based Pseudo-label for Robust Stereo Matching
Jul 31, 2023



Due to the domain differences and unbalanced disparity distribution across multiple datasets, current stereo matching approaches are commonly limited to a specific dataset and generalize poorly to others. Such domain shift issue is usually addressed by substantial adaptation on costly target-domain ground-truth data, which cannot be easily obtained in practical settings. In this paper, we propose to dig into uncertainty estimation for robust stereo matching. Specifically, to balance the disparity distribution, we employ a pixel-level uncertainty estimation to adaptively adjust the next stage disparity searching space, in this way driving the network progressively prune out the space of unlikely correspondences. Then, to solve the limited ground truth data, an uncertainty-based pseudo-label is proposed to adapt the pre-trained model to the new domain, where pixel-level and area-level uncertainty estimation are proposed to filter out the high-uncertainty pixels of predicted disparity maps and generate sparse while reliable pseudo-labels to align the domain gap. Experimentally, our method shows strong cross-domain, adapt, and joint generalization and obtains \textbf{1st} place on the stereo task of Robust Vision Challenge 2020. Additionally, our uncertainty-based pseudo-labels can be extended to train monocular depth estimation networks in an unsupervised way and even achieves comparable performance with the supervised methods. The code will be available at https://github.com/gallenszl/UCFNet.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
GRAINS: Proximity Sensing of Objects in Granular Materials
Jul 18, 2023

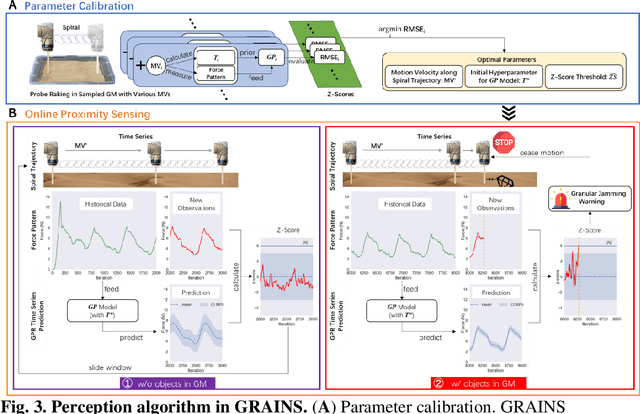

Proximity sensing detects an object's presence without contact. However, research has rarely explored proximity sensing in granular materials (GM) due to GM's lack of visual and complex properties. In this paper, we propose a granular-material-embedded autonomous proximity sensing system (GRAINS) based on three granular phenomena (fluidization, jamming, and failure wedge zone). GRAINS can automatically sense buried objects beneath GM in real-time manner (at least ~20 hertz) and perceive them 0.5 ~ 7 centimeters ahead in different granules without the use of vision or touch. We introduce a new spiral trajectory for the probe raking in GM, combining linear and circular motions, inspired by a common granular fluidization technique. Based on the observation of force-raising when granular jamming occurs in the failure wedge zone in front of the probe during its raking, we employ Gaussian process regression to constantly learn and predict the force patterns and detect the force anomaly resulting from granular jamming to identify the proximity sensing of buried objects. Finally, we apply GRAINS to a Bayesian-optimization-algorithm-guided exploration strategy to successfully localize underground objects and outline their distribution using proximity sensing without contact or digging. This work offers a simple yet reliable method with potential for safe operation in building habitation infrastructure on an alien planet without human intervention.
Boosting Feedback Efficiency of Interactive Reinforcement Learning by Adaptive Learning from Scores
Jul 11, 2023Interactive reinforcement learning has shown promise in learning complex robotic tasks. However, the process can be human-intensive due to the requirement of large amount of interactive feedback. This paper presents a new method that uses scores provided by humans, instead of pairwise preferences, to improve the feedback efficiency of interactive reinforcement learning. Our key insight is that scores can yield significantly more data than pairwise preferences. Specifically, we require a teacher to interactively score the full trajectories of an agent to train a behavioral policy in a sparse reward environment. To avoid unstable scores given by human negatively impact the training process, we propose an adaptive learning scheme. This enables the learning paradigm to be insensitive to imperfect or unreliable scores. We extensively evaluate our method on robotic locomotion and manipulation tasks. The results show that the proposed method can efficiently learn near-optimal policies by adaptive learning from scores, while requiring less feedback compared to pairwise preference learning methods. The source codes are publicly available at https://github.com/SSKKai/Interactive-Scoring-IRL.