 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
May 22, 2025While reinforcement learning (RL) has demonstrated remarkable success in enhancing large language models (LLMs), it has primarily focused on single-turn tasks such as solving math problems. Training effective web agents for multi-turn interactions remains challenging due to the complexity of long-horizon decision-making across dynamic web interfaces. In this work, we present WebAgent-R1, a simple yet effective end-to-end multi-turn RL framework for training web agents. It learns directly from online interactions with web environments by asynchronously generating diverse trajectories, entirely guided by binary rewards depending on task success. Experiments on the WebArena-Lite benchmark demonstrate the effectiveness of WebAgent-R1, boosting the task success rate of Qwen-2.5-3B from 6.1% to 33.9% and Llama-3.1-8B from 8.5% to 44.8%, significantly outperforming existing state-of-the-art methods and strong proprietary models such as OpenAI o3. In-depth analyses reveal the effectiveness of the thinking-based prompting strategy and test-time scaling through increased interactions for web tasks. We further investigate different RL initialization policies by introducing two variants, namely WebAgent-R1-Zero and WebAgent-R1-CoT, which highlight the importance of the warm-up training stage (i.e., behavior cloning) and provide insights on incorporating long chain-of-thought (CoT) reasoning in web agents.
Open World Classification with Adaptive Negative Samples
Mar 09, 2023



Open world classification is a task in natural language processing with key practical relevance and impact. Since the open or {\em unknown} category data only manifests in the inference phase, finding a model with a suitable decision boundary accommodating for the identification of known classes and discrimination of the open category is challenging. The performance of existing models is limited by the lack of effective open category data during the training stage or the lack of a good mechanism to learn appropriate decision boundaries. We propose an approach based on \underline{a}daptive \underline{n}egative \underline{s}amples (ANS) designed to generate effective synthetic open category samples in the training stage and without requiring any prior knowledge or external datasets. Empirically, we find a significant advantage in using auxiliary one-versus-rest binary classifiers, which effectively utilize the generated negative samples and avoid the complex threshold-seeking stage in previous works. Extensive experiments on three benchmark datasets show that ANS achieves significant improvements over state-of-the-art methods.
Ranking-Enhanced Unsupervised Sentence Representation Learning
Sep 21, 2022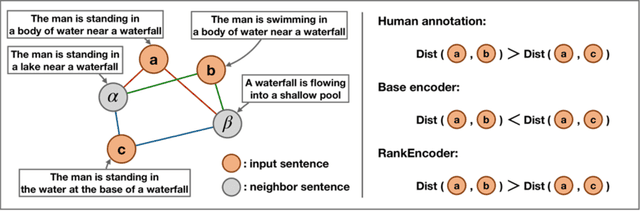
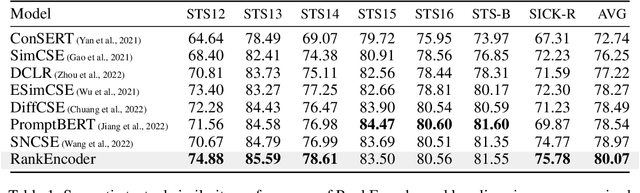
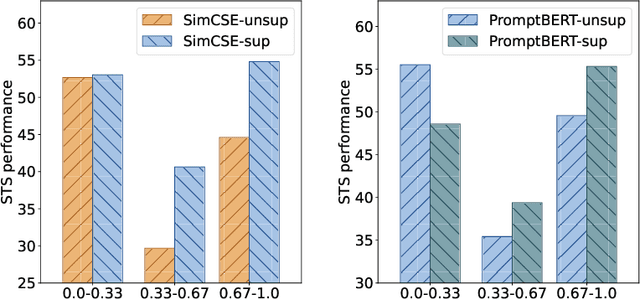
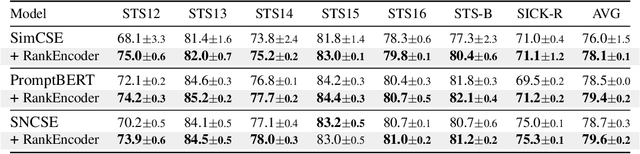
Previous unsupervised sentence embedding studies have focused on data augmentation methods such as dropout masking and rule-based sentence transformation methods. However, these approaches have a limitation of controlling the fine-grained semantics of augmented views of a sentence. This results in inadequate supervision signals for capturing a semantic similarity of similar sentences. In this work, we found that using neighbor sentences enables capturing a more accurate semantic similarity between similar sentences. Based on this finding, we propose RankEncoder, which uses relations between an input sentence and sentences in a corpus for training unsupervised sentence encoders. We evaluate RankEncoder from three perspectives: 1) the semantic textual similarity performance, 2) the efficacy on similar sentence pairs, and 3) the universality of RankEncoder. Experimental results show that RankEncoder achieves 80.07% Spearman's correlation, a 1.1% absolute improvement compared to the previous state-of-the-art performance. The improvement is even more significant, a 1.73% improvement, on similar sentence pairs. Also, we demonstrate that RankEncoder is universally applicable to existing unsupervised sentence encoders.
An End-to-end Approach for Handling Unknown Slot Values in Dialogue State Tracking
May 03, 2018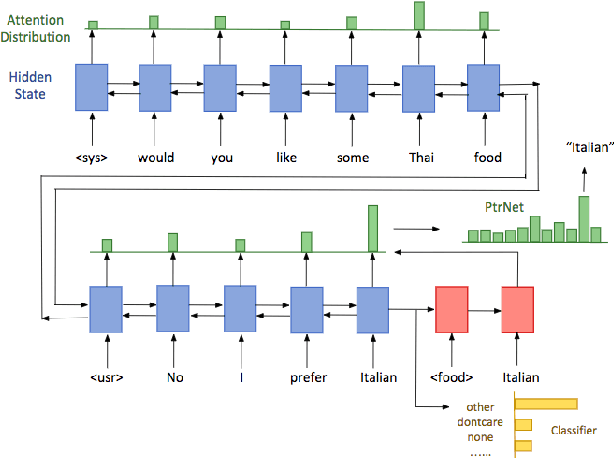
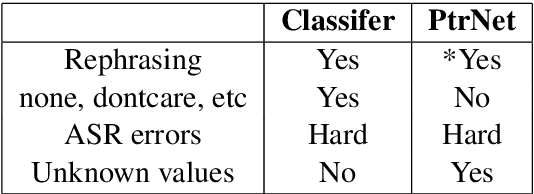
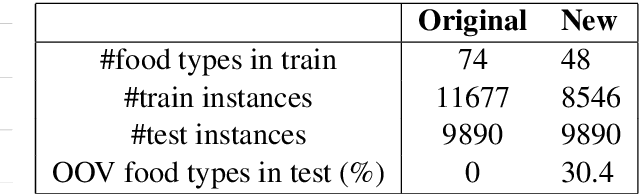
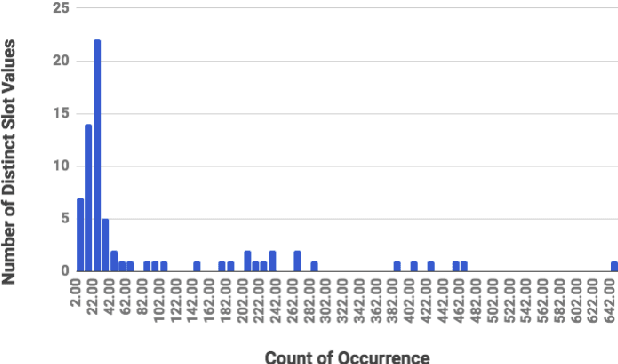
We highlight a practical yet rarely discussed problem in dialogue state tracking (DST), namely handling unknown slot values. Previous approaches generally assume predefined candidate lists and thus are not designed to output unknown values, especially when the spoken language understanding (SLU) module is absent as in many end-to-end (E2E) systems. We describe in this paper an E2E architecture based on the pointer network (PtrNet) that can effectively extract unknown slot values while still obtains state-of-the-art accuracy on the standard DSTC2 benchmark. We also provide extensive empirical evidence to show that tracking unknown values can be challenging and our approach can bring significant improvement with the help of an effective feature dropout technique.