 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining the Down-Sampling Scheme of U-Net for Precision Biomedical Image Segmentation
Feb 23, 2026U-Net architectures have been instrumental in advancing biomedical image segmentation (BIS) but often struggle with capturing long-range information. One reason is the conventional down-sampling techniques that prioritize computational efficiency at the expense of information retention. This paper introduces a simple but effective strategy, we call it Stair Pooling, which moderates the pace of down-sampling and reduces information loss by leveraging a sequence of concatenated small and narrow pooling operations in varied orientations. Specifically, our method modifies the reduction in dimensionality within each 2D pooling step from $\frac{1}{4}$ to $\frac{1}{2}$. This approach can also be adapted for 3D pooling to preserve even more information. Such preservation aids the U-Net in more effectively reconstructing spatial details during the up-sampling phase, thereby enhancing its ability to capture long-range information and improving segmentation accuracy. Extensive experiments on three BIS benchmarks demonstrate that the proposed Stair Pooling can increase both 2D and 3D U-Net performance by an average of 3.8\% in Dice scores. Moreover, we leverage the transfer entropy to select the optimal down-sampling paths and quantitatively show how the proposed Stair Pooling reduces the information loss.
SecRepoBench: Benchmarking LLMs for Secure Code Generation in Real-World Repositories
Apr 29, 2025



This paper introduces SecRepoBench, a benchmark to evaluate LLMs on secure code generation in real-world repositories. SecRepoBench has 318 code generation tasks in 27 C/C++ repositories, covering 15 CWEs. We evaluate 19 state-of-the-art LLMs using our benchmark and find that the models struggle with generating correct and secure code. In addition, the performance of LLMs to generate self-contained programs as measured by prior benchmarks do not translate to comparative performance at generating secure and correct code at the repository level in SecRepoBench. We show that the state-of-the-art prompt engineering techniques become less effective when applied to the repository level secure code generation problem. We conduct extensive experiments, including an agentic technique to generate secure code, to demonstrate that our benchmark is currently the most difficult secure coding benchmark, compared to previous state-of-the-art benchmarks. Finally, our comprehensive analysis provides insights into potential directions for enhancing the ability of LLMs to generate correct and secure code in real-world repositories.
Why Are Web AI Agents More Vulnerable Than Standalone LLMs? A Security Analysis
Feb 27, 2025



Recent advancements in Web AI agents have demonstrated remarkable capabilities in addressing complex web navigation tasks. However, emerging research shows that these agents exhibit greater vulnerability compared to standalone Large Language Models (LLMs), despite both being built upon the same safety-aligned models. This discrepancy is particularly concerning given the greater flexibility of Web AI Agent compared to standalone LLMs, which may expose them to a wider range of adversarial user inputs. To build a scaffold that addresses these concerns, this study investigates the underlying factors that contribute to the increased vulnerability of Web AI agents. Notably, this disparity stems from the multifaceted differences between Web AI agents and standalone LLMs, as well as the complex signals - nuances that simple evaluation metrics, such as success rate, often fail to capture. To tackle these challenges, we propose a component-level analysis and a more granular, systematic evaluation framework. Through this fine-grained investigation, we identify three critical factors that amplify the vulnerability of Web AI agents; (1) embedding user goals into the system prompt, (2) multi-step action generation, and (3) observational capabilities. Our findings highlights the pressing need to enhance security and robustness in AI agent design and provide actionable insights for targeted defense strategies.
ST-NeRP: Spatial-Temporal Neural Representation Learning with Prior Embedding for Patient-specific Imaging Study
Oct 25, 2024



During and after a course of therapy, imaging is routinely used to monitor the disease progression and assess the treatment responses. Despite of its significance, reliably capturing and predicting the spatial-temporal anatomic changes from a sequence of patient-specific image series presents a considerable challenge. Thus, the development of a computational framework becomes highly desirable for a multitude of practical applications. In this context, we propose a strategy of Spatial-Temporal Neural Representation learning with Prior embedding (ST-NeRP) for patient-specific imaging study. Our strategy involves leveraging an Implicit Neural Representation (INR) network to encode the image at the reference time point into a prior embedding. Subsequently, a spatial-temporally continuous deformation function is learned through another INR network. This network is trained using the whole patient-specific image sequence, enabling the prediction of deformation fields at various target time points. The efficacy of the ST-NeRP model is demonstrated through its application to diverse sequential image series, including 4D CT and longitudinal CT datasets within thoracic and abdominal imaging. The proposed ST-NeRP model exhibits substantial potential in enabling the monitoring of anatomical changes within a patient throughout the therapeutic journey.
Multi-sensor Learning Enables Information Transfer across Different Sensory Data and Augments Multi-modality Imaging
Sep 28, 2024Multi-modality imaging is widely used in clinical practice and biomedical research to gain a comprehensive understanding of an imaging subject. Currently, multi-modality imaging is accomplished by post hoc fusion of independently reconstructed images under the guidance of mutual information or spatially registered hardware, which limits the accuracy and utility of multi-modality imaging. Here, we investigate a data-driven multi-modality imaging (DMI) strategy for synergetic imaging of CT and MRI. We reveal two distinct types of features in multi-modality imaging, namely intra- and inter-modality features, and present a multi-sensor learning (MSL) framework to utilize the crossover inter-modality features for augmented multi-modality imaging. The MSL imaging approach breaks down the boundaries of traditional imaging modalities and allows for optimal hybridization of CT and MRI, which maximizes the use of sensory data. We showcase the effectiveness of our DMI strategy through synergetic CT-MRI brain imaging. The principle of DMI is quite general and holds enormous potential for various DMI applications across disciplines.
Automated radiotherapy treatment planning guided by GPT-4Vision
Jun 21, 2024



Radiotherapy treatment planning is a time-consuming and potentially subjective process that requires the iterative adjustment of model parameters to balance multiple conflicting objectives. Recent advancements in large foundation models offer promising avenues for addressing the challenges in planning and clinical decision-making. This study introduces GPT-RadPlan, a fully automated treatment planning framework that harnesses prior radiation oncology knowledge encoded in multi-modal large language models, such as GPT-4Vision (GPT-4V) from OpenAI. GPT-RadPlan is made aware of planning protocols as context and acts as an expert human planner, capable of guiding a treatment planning process. Via in-context learning, we incorporate clinical protocols for various disease sites as prompts to enable GPT-4V to acquire treatment planning domain knowledge. The resulting GPT-RadPlan agent is integrated into our in-house inverse treatment planning system through an API. The efficacy of the automated planning system is showcased using multiple prostate and head & neck cancer cases, where we compared GPT-RadPlan results to clinical plans. In all cases, GPT-RadPlan either outperformed or matched the clinical plans, demonstrating superior target coverage and organ-at-risk sparing. Consistently satisfying the dosimetric objectives in the clinical protocol, GPT-RadPlan represents the first multimodal large language model agent that mimics the behaviors of human planners in radiation oncology clinics, achieving remarkable results in automating the treatment planning process without the need for additional training.
Constrained Decoding for Secure Code Generation
Apr 30, 2024Code Large Language Models (Code LLMs) have been increasingly used by developers to boost productivity, but they often generate vulnerable code. Thus, there is an urgent need to ensure that code generated by Code LLMs is correct and secure. Previous research has primarily focused on generating secure code, overlooking the fact that secure code also needs to be correct. This oversight can lead to a false sense of security. Currently, the community lacks a method to measure actual progress in this area, and we need solutions that address both security and correctness of code generation. This paper introduces a new benchmark, CodeGuard+, along with two new metrics, secure-pass@k and secure@$k_{\text{pass}}$, to measure Code LLMs' ability to generate both secure and correct code. Using our new evaluation methods, we show that the state-of-the-art defense technique, prefix tuning, may not be as strong as previously believed, since it generates secure code but sacrifices functional correctness. We also demonstrate that different decoding methods significantly affect the security of Code LLMs. Furthermore, we explore a new defense direction: constrained decoding for secure code generation. We propose new constrained decoding techniques to generate code that satisfies security and correctness constraints simultaneously. Our results reveal that constrained decoding is more effective than prefix tuning to improve the security of Code LLMs, without requiring a specialized training dataset. Moreover, constrained decoding can be used together with prefix tuning to further improve the security of Code LLMs.
Vulnerability Detection with Code Language Models: How Far Are We?
Mar 27, 2024



In the context of the rising interest in code language models (code LMs) and vulnerability detection, we study the effectiveness of code LMs for detecting vulnerabilities. Our analysis reveals significant shortcomings in existing vulnerability datasets, including poor data quality, low label accuracy, and high duplication rates, leading to unreliable model performance in realistic vulnerability detection scenarios. Additionally, the evaluation methods used with these datasets are not representative of real-world vulnerability detection. To address these challenges, we introduce PrimeVul, a new dataset for training and evaluating code LMs for vulnerability detection. PrimeVul incorporates a novel set of data labeling techniques that achieve comparable label accuracy to human-verified benchmarks while significantly expanding the dataset. It also implements a rigorous data de-duplication and chronological data splitting strategy to mitigate data leakage issues, alongside introducing more realistic evaluation metrics and settings. This comprehensive approach aims to provide a more accurate assessment of code LMs' performance in real-world conditions. Evaluating code LMs on PrimeVul reveals that existing benchmarks significantly overestimate the performance of these models. For instance, a state-of-the-art 7B model scored 68.26% F1 on BigVul but only 3.09% F1 on PrimeVul. Attempts to improve performance through advanced training techniques and larger models like GPT-3.5 and GPT-4 were unsuccessful, with results akin to random guessing in the most stringent settings. These findings underscore the considerable gap between current capabilities and the practical requirements for deploying code LMs in security roles, highlighting the need for more innovative research in this domain.
2L3: Lifting Imperfect Generated 2D Images into Accurate 3D
Jan 29, 2024Reconstructing 3D objects from a single image is an intriguing but challenging problem. One promising solution is to utilize multi-view (MV) 3D reconstruction to fuse generated MV images into consistent 3D objects. However, the generated images usually suffer from inconsistent lighting, misaligned geometry, and sparse views, leading to poor reconstruction quality. To cope with these problems, we present a novel 3D reconstruction framework that leverages intrinsic decomposition guidance, transient-mono prior guidance, and view augmentation to cope with the three issues, respectively. Specifically, we first leverage to decouple the shading information from the generated images to reduce the impact of inconsistent lighting; then, we introduce mono prior with view-dependent transient encoding to enhance the reconstructed normal; and finally, we design a view augmentation fusion strategy that minimizes pixel-level loss in generated sparse views and semantic loss in augmented random views, resulting in view-consistent geometry and detailed textures. Our approach, therefore, enables the integration of a pre-trained MV image generator and a neural network-based volumetric signed distance function (SDF) representation for a single image to 3D object reconstruction. We evaluate our framework on various datasets and demonstrate its superior performance in both quantitative and qualitative assessments, signifying a significant advancement in 3D object reconstruction. Compared with the latest state-of-the-art method Syncdreamer~\cite{liu2023syncdreamer}, we reduce the Chamfer Distance error by about 36\% and improve PSNR by about 30\% .
DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection
Apr 01, 2023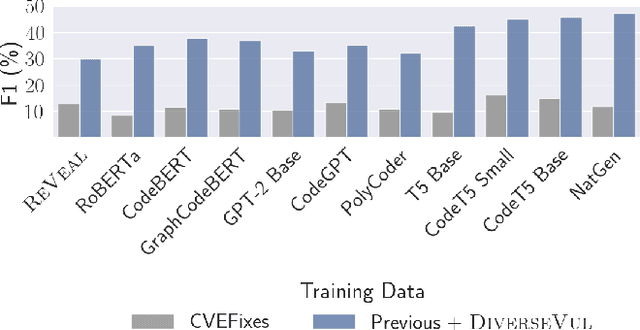
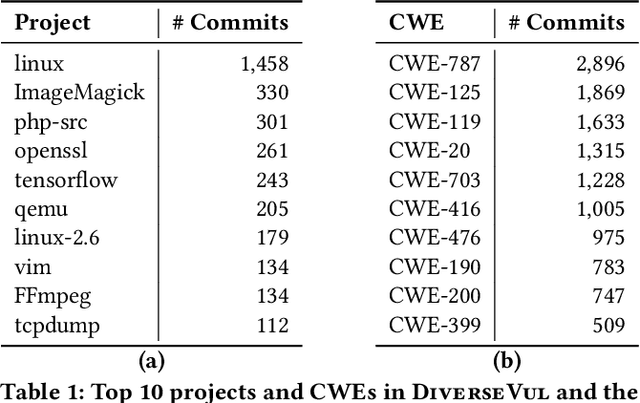
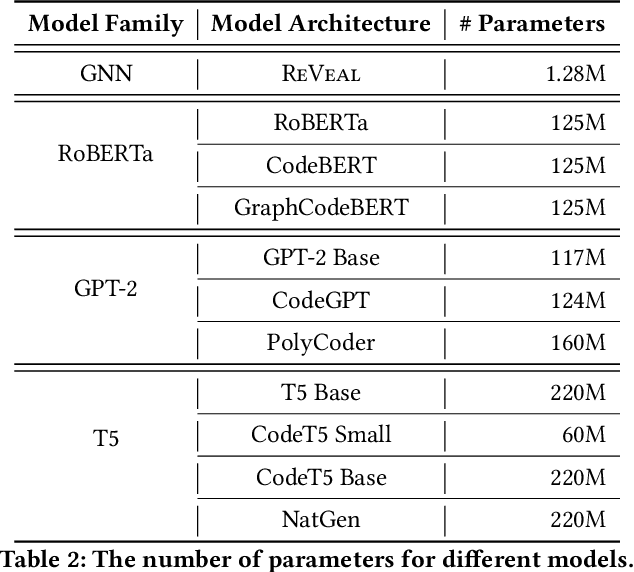
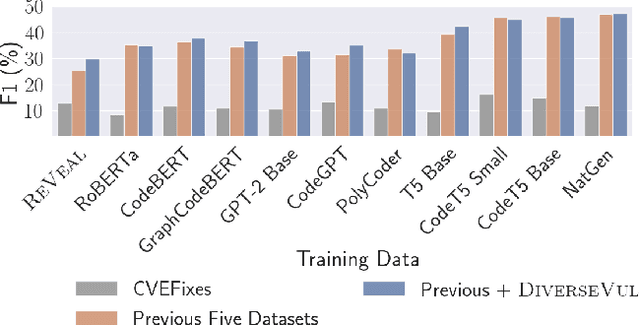
We propose and release a new vulnerable source code dataset. We curate the dataset by crawling security issue websites, extracting vulnerability-fixing commits and source codes from the corresponding projects. Our new dataset contains 150 CWEs, 26,635 vulnerable functions, and 352,606 non-vulnerable functions extracted from 7,861 commits. Our dataset covers 305 more projects than all previous datasets combined. We show that increasing the diversity and volume of training data improves the performance of deep learning models for vulnerability detection. Combining our new dataset with previous datasets, we present an analysis of the challenges and promising research directions of using deep learning for detecting software vulnerabilities. We study 11 model architectures belonging to 4 families. Our results show that deep learning is still not ready for vulnerability detection, due to high false positive rate, low F1 score, and difficulty of detecting hard CWEs. In particular, we demonstrate an important generalization challenge for the deployment of deep learning-based models. However, we also identify hopeful future research directions. We demonstrate that large language models (LLMs) are the future for vulnerability detection, outperforming Graph Neural Networks (GNNs) with manual feature engineering. Moreover, developing source code specific pre-training objectives is a promising research direction to improve the vulnerability detection performance.