 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the "Video" in Video-Language Understanding
Jun 03, 2022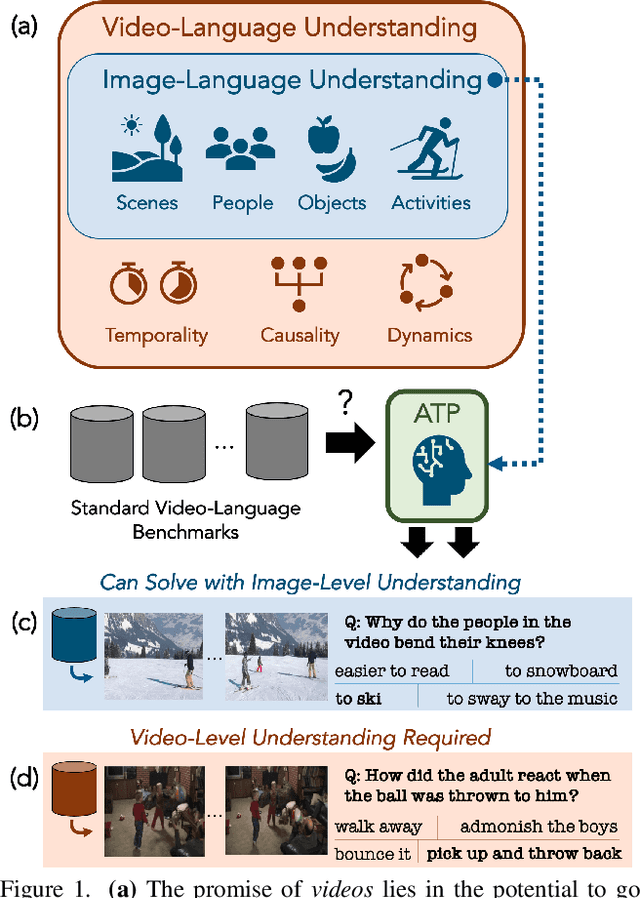


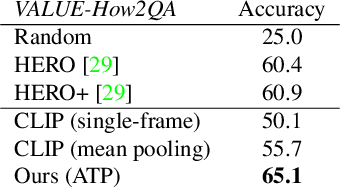
What makes a video task uniquely suited for videos, beyond what can be understood from a single image? Building on recent progress in self-supervised image-language models, we revisit this question in the context of video and language tasks. We propose the atemporal probe (ATP), a new model for video-language analysis which provides a stronger bound on the baseline accuracy of multimodal models constrained by image-level understanding. By applying this model to standard discriminative video and language tasks, such as video question answering and text-to-video retrieval, we characterize the limitations and potential of current video-language benchmarks. We find that understanding of event temporality is often not necessary to achieve strong or state-of-the-art performance, even compared with recent large-scale video-language models and in contexts intended to benchmark deeper video-level understanding. We also demonstrate how ATP can improve both video-language dataset and model design. We describe a technique for leveraging ATP to better disentangle dataset subsets with a higher concentration of temporally challenging data, improving benchmarking efficacy for causal and temporal understanding. Further, we show that effectively integrating ATP into full video-level temporal models can improve efficiency and state-of-the-art accuracy.
Generalizable Task Planning through Representation Pretraining
May 16, 2022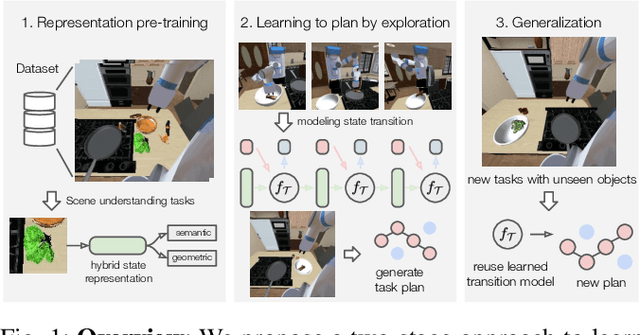
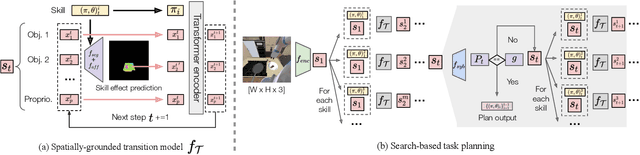
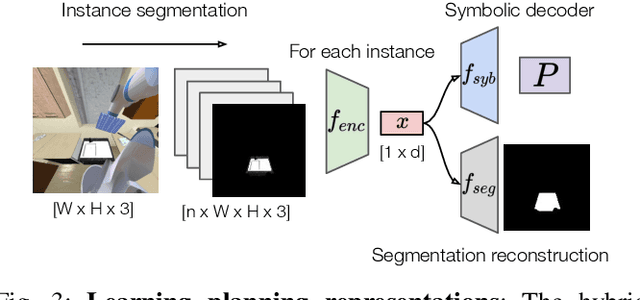
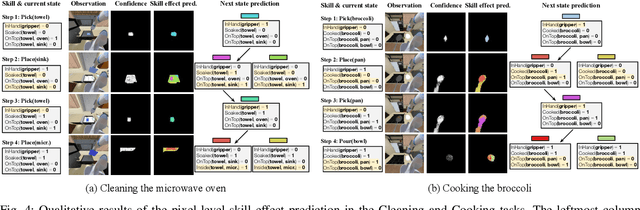
The ability to plan for multi-step manipulation tasks in unseen situations is crucial for future home robots. But collecting sufficient experience data for end-to-end learning is often infeasible in the real world, as deploying robots in many environments can be prohibitively expensive. On the other hand, large-scale scene understanding datasets contain diverse and rich semantic and geometric information. But how to leverage such information for manipulation remains an open problem. In this paper, we propose a learning-to-plan method that can generalize to new object instances by leveraging object-level representations extracted from a synthetic scene understanding dataset. We evaluate our method with a suite of challenging multi-step manipulation tasks inspired by household activities and show that our model achieves measurably better success rate than state-of-the-art end-to-end approaches. Additional information can be found at https://sites.google.com/view/gentp
ObjectFolder 2.0: A Multisensory Object Dataset for Sim2Real Transfer
Apr 05, 2022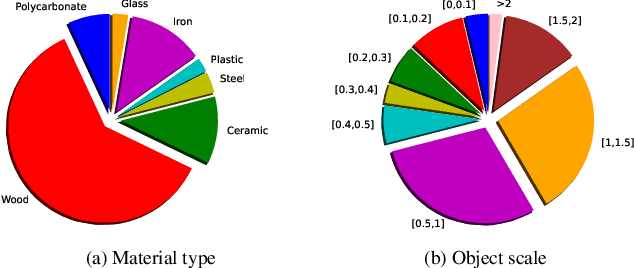
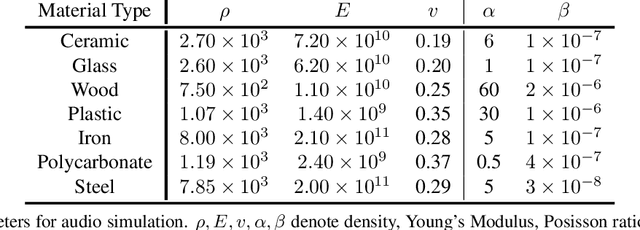


Objects play a crucial role in our everyday activities. Though multisensory object-centric learning has shown great potential lately, the modeling of objects in prior work is rather unrealistic. ObjectFolder 1.0 is a recent dataset that introduces 100 virtualized objects with visual, acoustic, and tactile sensory data. However, the dataset is small in scale and the multisensory data is of limited quality, hampering generalization to real-world scenarios. We present ObjectFolder 2.0, a large-scale, multisensory dataset of common household objects in the form of implicit neural representations that significantly enhances ObjectFolder 1.0 in three aspects. First, our dataset is 10 times larger in the amount of objects and orders of magnitude faster in rendering time. Second, we significantly improve the multisensory rendering quality for all three modalities. Third, we show that models learned from virtual objects in our dataset successfully transfer to their real-world counterparts in three challenging tasks: object scale estimation, contact localization, and shape reconstruction. ObjectFolder 2.0 offers a new path and testbed for multisensory learning in computer vision and robotics. The dataset is available at https://github.com/rhgao/ObjectFolder.
MetaMorph: Learning Universal Controllers with Transformers
Mar 22, 2022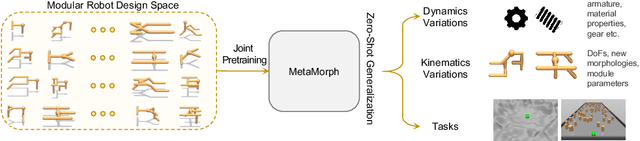
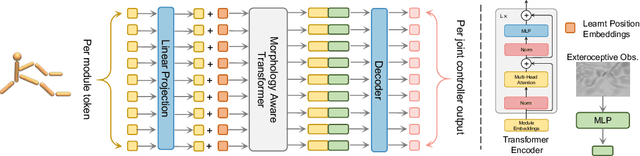
Multiple domains like vision, natural language, and audio are witnessing tremendous progress by leveraging Transformers for large scale pre-training followed by task specific fine tuning. In contrast, in robotics we primarily train a single robot for a single task. However, modular robot systems now allow for the flexible combination of general-purpose building blocks into task optimized morphologies. However, given the exponentially large number of possible robot morphologies, training a controller for each new design is impractical. In this work, we propose MetaMorph, a Transformer based approach to learn a universal controller over a modular robot design space. MetaMorph is based on the insight that robot morphology is just another modality on which we can condition the output of a Transformer. Through extensive experiments we demonstrate that large scale pre-training on a variety of robot morphologies results in policies with combinatorial generalization capabilities, including zero shot generalization to unseen robot morphologies. We further demonstrate that our pre-trained policy can be used for sample-efficient transfer to completely new robot morphologies and tasks.
Error-Aware Imitation Learning from Teleoperation Data for Mobile Manipulation
Dec 09, 2021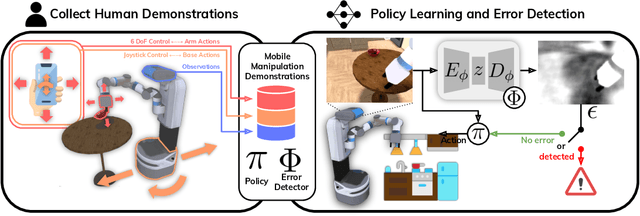
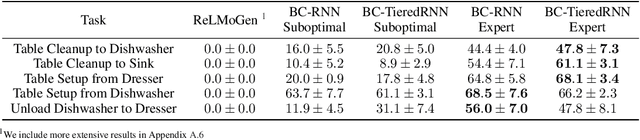

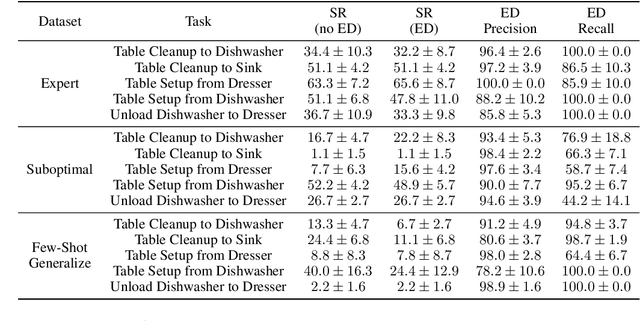
In mobile manipulation (MM), robots can both navigate within and interact with their environment and are thus able to complete many more tasks than robots only capable of navigation or manipulation. In this work, we explore how to apply imitation learning (IL) to learn continuous visuo-motor policies for MM tasks. Much prior work has shown that IL can train visuo-motor policies for either manipulation or navigation domains, but few works have applied IL to the MM domain. Doing this is challenging for two reasons: on the data side, current interfaces make collecting high-quality human demonstrations difficult, and on the learning side, policies trained on limited data can suffer from covariate shift when deployed. To address these problems, we first propose Mobile Manipulation RoboTurk (MoMaRT), a novel teleoperation framework allowing simultaneous navigation and manipulation of mobile manipulators, and collect a first-of-its-kind large scale dataset in a realistic simulated kitchen setting. We then propose a learned error detection system to address the covariate shift by detecting when an agent is in a potential failure state. We train performant IL policies and error detectors from this data, and achieve over 45% task success rate and 85% error detection success rate across multiple multi-stage tasks when trained on expert data. Codebase, datasets, visualization, and more available at https://sites.google.com/view/il-for-mm/home.
Visual Intelligence through Human Interaction
Nov 12, 2021Over the last decade, Computer Vision, the branch of Artificial Intelligence aimed at understanding the visual world, has evolved from simply recognizing objects in images to describing pictures, answering questions about images, aiding robots maneuver around physical spaces and even generating novel visual content. As these tasks and applications have modernized, so too has the reliance on more data, either for model training or for evaluation. In this chapter, we demonstrate that novel interaction strategies can enable new forms of data collection and evaluation for Computer Vision. First, we present a crowdsourcing interface for speeding up paid data collection by an order of magnitude, feeding the data-hungry nature of modern vision models. Second, we explore a method to increase volunteer contributions using automated social interventions. Third, we develop a system to ensure human evaluation of generative vision models are reliable, affordable and grounded in psychophysics theory. We conclude with future opportunities for Human-Computer Interaction to aid Computer Vision.
Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks
Sep 21, 2021
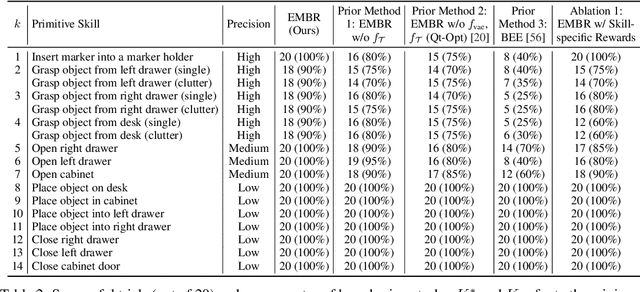
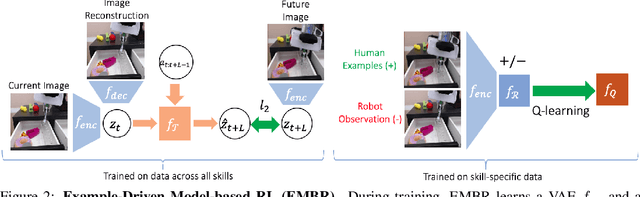

In this paper, we study the problem of learning a repertoire of low-level skills from raw images that can be sequenced to complete long-horizon visuomotor tasks. Reinforcement learning (RL) is a promising approach for acquiring short-horizon skills autonomously. However, the focus of RL algorithms has largely been on the success of those individual skills, more so than learning and grounding a large repertoire of skills that can be sequenced to complete extended multi-stage tasks. The latter demands robustness and persistence, as errors in skills can compound over time, and may require the robot to have a number of primitive skills in its repertoire, rather than just one. To this end, we introduce EMBR, a model-based RL method for learning primitive skills that are suitable for completing long-horizon visuomotor tasks. EMBR learns and plans using a learned model, critic, and success classifier, where the success classifier serves both as a reward function for RL and as a grounding mechanism to continuously detect if the robot should retry a skill when unsuccessful or under perturbations. Further, the learned model is task-agnostic and trained using data from all skills, enabling the robot to efficiently learn a number of distinct primitives. These visuomotor primitive skills and their associated pre- and post-conditions can then be directly combined with off-the-shelf symbolic planners to complete long-horizon tasks. On a Franka Emika robot arm, we find that EMBR enables the robot to complete three long-horizon visuomotor tasks at 85% success rate, such as organizing an office desk, a file cabinet, and drawers, which require sequencing up to 12 skills, involve 14 unique learned primitives, and demand generalization to novel objects.
ObjectFolder: A Dataset of Objects with Implicit Visual, Auditory, and Tactile Representations
Sep 18, 2021
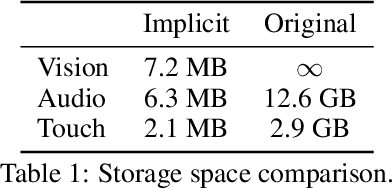

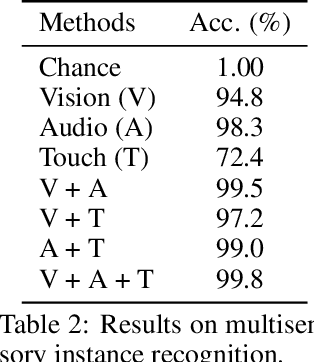
Multisensory object-centric perception, reasoning, and interaction have been a key research topic in recent years. However, the progress in these directions is limited by the small set of objects available -- synthetic objects are not realistic enough and are mostly centered around geometry, while real object datasets such as YCB are often practically challenging and unstable to acquire due to international shipping, inventory, and financial cost. We present ObjectFolder, a dataset of 100 virtualized objects that addresses both challenges with two key innovations. First, ObjectFolder encodes the visual, auditory, and tactile sensory data for all objects, enabling a number of multisensory object recognition tasks, beyond existing datasets that focus purely on object geometry. Second, ObjectFolder employs a uniform, object-centric, and implicit representation for each object's visual textures, acoustic simulations, and tactile readings, making the dataset flexible to use and easy to share. We demonstrate the usefulness of our dataset as a testbed for multisensory perception and control by evaluating it on a variety of benchmark tasks, including instance recognition, cross-sensory retrieval, 3D reconstruction, and robotic grasping.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Co-GAIL: Learning Diverse Strategies for Human-Robot Collaboration
Aug 13, 2021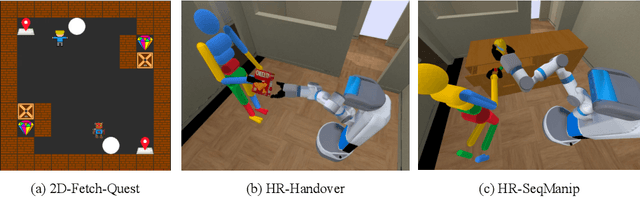
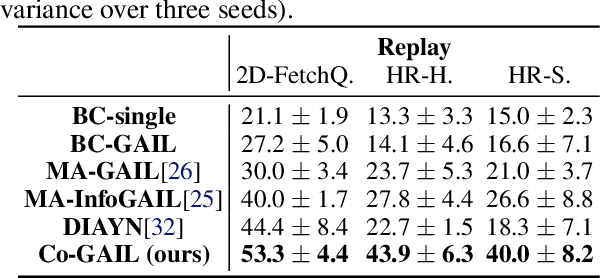
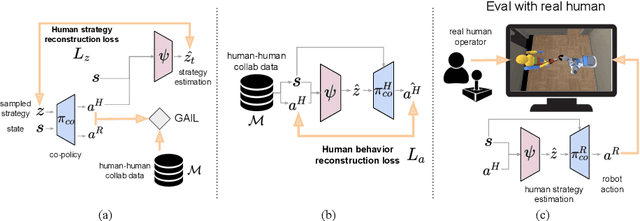
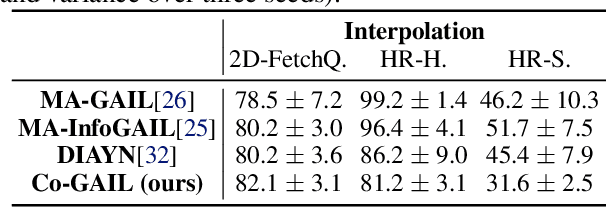
We present a method for learning a human-robot collaboration policy from human-human collaboration demonstrations. An effective robot assistant must learn to handle diverse human behaviors shown in the demonstrations and be robust when the humans adjust their strategies during online task execution. Our method co-optimizes a human policy and a robot policy in an interactive learning process: the human policy learns to generate diverse and plausible collaborative behaviors from demonstrations while the robot policy learns to assist by estimating the unobserved latent strategy of its human collaborator. Across a 2D strategy game, a human-robot handover task, and a multi-step collaborative manipulation task, our method outperforms the alternatives in both simulated evaluations and when executing the tasks with a real human operator in-the-loop. Supplementary materials and videos at https://sites.google.com/view/co-gail-web/home