 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAM: Large-scale Video Continual Learning with Bootstrapped Compression
Aug 07, 2025Continual learning (CL) promises to allow neural networks to learn from continuous streams of inputs, instead of IID (independent and identically distributed) sampling, which requires random access to a full dataset. This would allow for much smaller storage requirements and self-sufficiency of deployed systems that cope with natural distribution shifts, similarly to biological learning. We focus on video CL employing a rehearsal-based approach, which reinforces past samples from a memory buffer. We posit that part of the reason why practical video CL is challenging is the high memory requirements of video, further exacerbated by long-videos and continual streams, which are at odds with the common rehearsal-buffer size constraints. To address this, we propose to use compressed vision, i.e. store video codes (embeddings) instead of raw inputs, and train a video classifier by IID sampling from this rolling buffer. Training a video compressor online (so not depending on any pre-trained networks) means that it is also subject to catastrophic forgetting. We propose a scheme to deal with this forgetting by refreshing video codes, which requires careful decompression with a previous version of the network and recompression with a new one. We name our method Continually Refreshed Amodal Memory (CRAM). We expand current video CL benchmarks to large-scale settings, namely EpicKitchens-100 and Kinetics-700, storing thousands of relatively long videos in under 2 GB, and demonstrate empirically that our video CL method outperforms prior art with a significantly reduced memory footprint.
ObjectFolder: A Dataset of Objects with Implicit Visual, Auditory, and Tactile Representations
Sep 18, 2021
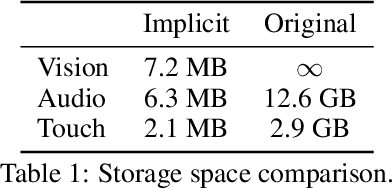

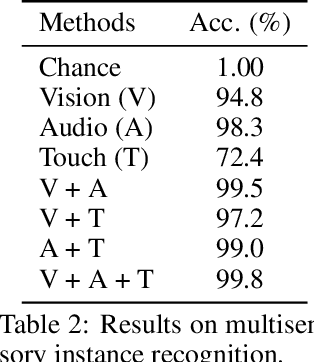
Multisensory object-centric perception, reasoning, and interaction have been a key research topic in recent years. However, the progress in these directions is limited by the small set of objects available -- synthetic objects are not realistic enough and are mostly centered around geometry, while real object datasets such as YCB are often practically challenging and unstable to acquire due to international shipping, inventory, and financial cost. We present ObjectFolder, a dataset of 100 virtualized objects that addresses both challenges with two key innovations. First, ObjectFolder encodes the visual, auditory, and tactile sensory data for all objects, enabling a number of multisensory object recognition tasks, beyond existing datasets that focus purely on object geometry. Second, ObjectFolder employs a uniform, object-centric, and implicit representation for each object's visual textures, acoustic simulations, and tactile readings, making the dataset flexible to use and easy to share. We demonstrate the usefulness of our dataset as a testbed for multisensory perception and control by evaluating it on a variety of benchmark tasks, including instance recognition, cross-sensory retrieval, 3D reconstruction, and robotic grasping.