 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Era of Agentic Organization: Learning to Organize with Language Models
Oct 30, 2025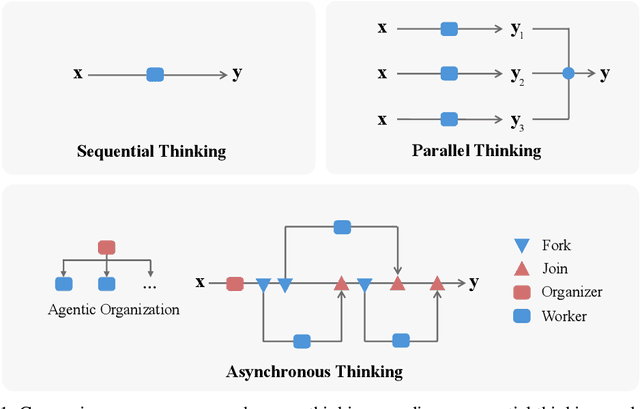

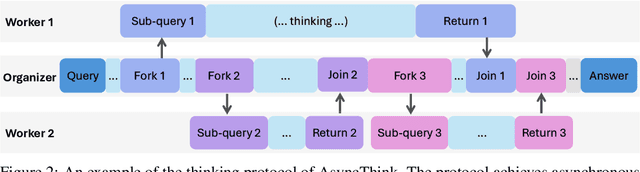
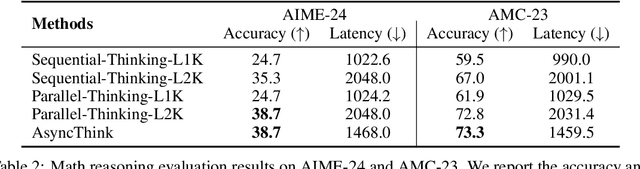
We envision a new era of AI, termed agentic organization, where agents solve complex problems by working collaboratively and concurrently, enabling outcomes beyond individual intelligence. To realize this vision, we introduce asynchronous thinking (AsyncThink) as a new paradigm of reasoning with large language models, which organizes the internal thinking process into concurrently executable structures. Specifically, we propose a thinking protocol where an organizer dynamically assigns sub-queries to workers, merges intermediate knowledge, and produces coherent solutions. More importantly, the thinking structure in this protocol can be further optimized through reinforcement learning. Experiments demonstrate that AsyncThink achieves 28% lower inference latency compared to parallel thinking while improving accuracy on mathematical reasoning. Moreover, AsyncThink generalizes its learned asynchronous thinking capabilities, effectively tackling unseen tasks without additional training.
Towards Stable and Effective Reinforcement Learning for Mixture-of-Experts
Oct 27, 2025Recent advances in reinforcement learning (RL) have substantially improved the training of large-scale language models, leading to significant gains in generation quality and reasoning ability. However, most existing research focuses on dense models, while RL training for Mixture-of-Experts (MoE) architectures remains underexplored. To address the instability commonly observed in MoE training, we propose a novel router-aware approach to optimize importance sampling (IS) weights in off-policy RL. Specifically, we design a rescaling strategy guided by router logits, which effectively reduces gradient variance and mitigates training divergence. Experimental results demonstrate that our method significantly improves both the convergence stability and the final performance of MoE models, highlighting the potential of RL algorithmic innovations tailored to MoE architectures and providing a promising direction for efficient training of large-scale expert models.
Benefits and Pitfalls of Reinforcement Learning for Language Model Planning: A Theoretical Perspective
Sep 26, 2025Recent reinforcement learning (RL) methods have substantially enhanced the planning capabilities of Large Language Models (LLMs), yet the theoretical basis for their effectiveness remains elusive. In this work, we investigate RL's benefits and limitations through a tractable graph-based abstraction, focusing on policy gradient (PG) and Q-learning methods. Our theoretical analyses reveal that supervised fine-tuning (SFT) may introduce co-occurrence-based spurious solutions, whereas RL achieves correct planning primarily through exploration, underscoring exploration's role in enabling better generalization. However, we also show that PG suffers from diversity collapse, where output diversity decreases during training and persists even after perfect accuracy is attained. By contrast, Q-learning provides two key advantages: off-policy learning and diversity preservation at convergence. We further demonstrate that careful reward design is necessary to prevent reward hacking in Q-learning. Finally, applying our framework to the real-world planning benchmark Blocksworld, we confirm that these behaviors manifest in practice.
VibeVoice Technical Report
Aug 26, 2025This report presents VibeVoice, a novel model designed to synthesize long-form speech with multiple speakers by employing next-token diffusion, which is a unified method for modeling continuous data by autoregressively generating latent vectors via diffusion. To enable this, we introduce a novel continuous speech tokenizer that, when compared to the popular Encodec model, improves data compression by 80 times while maintaining comparable performance. The tokenizer effectively preserves audio fidelity while significantly boosting computational efficiency for processing long sequences. Thus, VibeVoice can synthesize long-form speech for up to 90 minutes (in a 64K context window length) with a maximum of 4 speakers, capturing the authentic conversational ``vibe'' and surpassing open-source and proprietary dialogue models.
Data Efficacy for Language Model Training
Jun 26, 2025Data is fundamental to the training of language models (LM). Recent research has been dedicated to data efficiency, which aims to maximize performance by selecting a minimal or optimal subset of training data. Techniques such as data filtering, sampling, and selection play a crucial role in this area. To complement it, we define Data Efficacy, which focuses on maximizing performance by optimizing the organization of training data and remains relatively underexplored. This work introduces a general paradigm, DELT, for considering data efficacy in LM training, which highlights the significance of training data organization. DELT comprises three components: Data Scoring, Data Selection, and Data Ordering. Among these components, we design Learnability-Quality Scoring (LQS), as a new instance of Data Scoring, which considers both the learnability and quality of each data sample from the gradient consistency perspective. We also devise Folding Ordering (FO), as a novel instance of Data Ordering, which addresses issues such as model forgetting and data distribution bias. Comprehensive experiments validate the data efficacy in LM training, which demonstrates the following: Firstly, various instances of the proposed DELT enhance LM performance to varying degrees without increasing the data scale and model size. Secondly, among these instances, the combination of our proposed LQS for data scoring and Folding for data ordering achieves the most significant improvement. Lastly, data efficacy can be achieved together with data efficiency by applying data selection. Therefore, we believe that data efficacy is a promising foundational area in LM training.
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
Reinforcement Pre-Training
Jun 09, 2025



In this work, we introduce Reinforcement Pre-Training (RPT) as a new scaling paradigm for large language models and reinforcement learning (RL). Specifically, we reframe next-token prediction as a reasoning task trained using RL, where it receives verifiable rewards for correctly predicting the next token for a given context. RPT offers a scalable method to leverage vast amounts of text data for general-purpose RL, rather than relying on domain-specific annotated answers. By incentivizing the capability of next-token reasoning, RPT significantly improves the language modeling accuracy of predicting the next tokens. Moreover, RPT provides a strong pre-trained foundation for further reinforcement fine-tuning. The scaling curves show that increased training compute consistently improves the next-token prediction accuracy. The results position RPT as an effective and promising scaling paradigm to advance language model pre-training.
Rectified Sparse Attention
Jun 05, 2025Efficient long-sequence generation is a critical challenge for Large Language Models. While recent sparse decoding methods improve efficiency, they suffer from KV cache misalignment, where approximation errors accumulate and degrade generation quality. In this work, we propose Rectified Sparse Attention (ReSA), a simple yet effective method that combines block-sparse attention with periodic dense rectification. By refreshing the KV cache at fixed intervals using a dense forward pass, ReSA bounds error accumulation and preserves alignment with the pretraining distribution. Experiments across math reasoning, language modeling, and retrieval tasks demonstrate that ReSA achieves near-lossless generation quality with significantly improved efficiency. Notably, ReSA delivers up to 2.42$\times$ end-to-end speedup under decoding at 256K sequence length, making it a practical solution for scalable long-context inference. Code is available at https://aka.ms/ReSA-LM.
On-Policy RL with Optimal Reward Baseline
May 29, 2025Reinforcement learning algorithms are fundamental to align large language models with human preferences and to enhance their reasoning capabilities. However, current reinforcement learning algorithms often suffer from training instability due to loose on-policy constraints and computational inefficiency due to auxiliary models. In this work, we propose On-Policy RL with Optimal reward baseline (OPO), a novel and simplified reinforcement learning algorithm designed to address these challenges. OPO emphasizes the importance of exact on-policy training, which empirically stabilizes the training process and enhances exploration. Moreover, OPO introduces the optimal reward baseline that theoretically minimizes gradient variance. We evaluate OPO on mathematical reasoning benchmarks. The results demonstrate its superior performance and training stability without additional models or regularization terms. Furthermore, OPO achieves lower policy shifts and higher output entropy, encouraging more diverse and less repetitive responses. These results highlight OPO as a promising direction for stable and effective reinforcement learning in large language model alignment and reasoning tasks. The implementation is provided at https://github.com/microsoft/LMOps/tree/main/opo.
From Large AI Models to Agentic AI: A Tutorial on Future Intelligent Communications
May 28, 2025With the advent of 6G communications, intelligent communication systems face multiple challenges, including constrained perception and response capabilities, limited scalability, and low adaptability in dynamic environments. This tutorial provides a systematic introduction to the principles, design, and applications of Large Artificial Intelligence Models (LAMs) and Agentic AI technologies in intelligent communication systems, aiming to offer researchers a comprehensive overview of cutting-edge technologies and practical guidance. First, we outline the background of 6G communications, review the technological evolution from LAMs to Agentic AI, and clarify the tutorial's motivation and main contributions. Subsequently, we present a comprehensive review of the key components required for constructing LAMs. We further categorize LAMs and analyze their applicability, covering Large Language Models (LLMs), Large Vision Models (LVMs), Large Multimodal Models (LMMs), Large Reasoning Models (LRMs), and lightweight LAMs. Next, we propose a LAM-centric design paradigm tailored for communications, encompassing dataset construction and both internal and external learning approaches. Building upon this, we develop an LAM-based Agentic AI system for intelligent communications, clarifying its core components such as planners, knowledge bases, tools, and memory modules, as well as its interaction mechanisms. We also introduce a multi-agent framework with data retrieval, collaborative planning, and reflective evaluation for 6G. Subsequently, we provide a detailed overview of the applications of LAMs and Agentic AI in communication scenarios. Finally, we summarize the research challenges and future directions in current studies, aiming to support the development of efficient, secure, and sustainable next-generation intelligent communication systems.