 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Atom Peptide Design via Riemannian-Euclidean Bayesian Flow Networks
Nov 19, 2025



Diffusion and flow matching models have recently emerged as promising approaches for peptide binder design. Despite their progress, these models still face two major challenges. First, categorical sampling of discrete residue types collapses their continuous parameters into onehot assignments, while continuous variables (e.g., atom positions) evolve smoothly throughout the generation process. This mismatch disrupts the update dynamics and results in suboptimal performance. Second, current models assume unimodal distributions for side-chain torsion angles, which conflicts with the inherently multimodal nature of side chain rotameric states and limits prediction accuracy. To address these limitations, we introduce PepBFN, the first Bayesian flow network for full atom peptide design that directly models parameter distributions in fully continuous space. Specifically, PepBFN models discrete residue types by learning their continuous parameter distributions, enabling joint and smooth Bayesian updates with other continuous structural parameters. It further employs a novel Gaussian mixture based Bayesian flow to capture the multimodal side chain rotameric states and a Matrix Fisher based Riemannian flow to directly model residue orientations on the $\mathrm{SO}(3)$ manifold. Together, these parameter distributions are progressively refined via Bayesian updates, yielding smooth and coherent peptide generation. Experiments on side chain packing, reverse folding, and binder design tasks demonstrate the strong potential of PepBFN in computational peptide design.
HPCAgentTester: A Multi-Agent LLM Approach for Enhanced HPC Unit Test Generation
Nov 13, 2025Unit testing in High-Performance Computing (HPC) is critical but challenged by parallelism, complex algorithms, and diverse hardware. Traditional methods often fail to address non-deterministic behavior and synchronization issues in HPC applications. This paper introduces HPCAgentTester, a novel multi-agent Large Language Model (LLM) framework designed to automate and enhance unit test generation for HPC software utilizing OpenMP and MPI. HPCAgentTester employs a unique collaborative workflow where specialized LLM agents (Recipe Agent and Test Agent) iteratively generate and refine test cases through a critique loop. This architecture enables the generation of context-aware unit tests that specifically target parallel execution constructs, complex communication patterns, and hierarchical parallelism. We demonstrate HPCAgentTester's ability to produce compilable and functionally correct tests for OpenMP and MPI primitives, effectively identifying subtle bugs that are often missed by conventional techniques. Our evaluation shows that HPCAgentTester significantly improves test compilation rates and correctness compared to standalone LLMs, offering a more robust and scalable solution for ensuring the reliability of parallel software systems.
Text to Sketch Generation with Multi-Styles
Nov 06, 2025Recent advances in vision-language models have facilitated progress in sketch generation. However, existing specialized methods primarily focus on generic synthesis and lack mechanisms for precise control over sketch styles. In this work, we propose a training-free framework based on diffusion models that enables explicit style guidance via textual prompts and referenced style sketches. Unlike previous style transfer methods that overwrite key and value matrices in self-attention, we incorporate the reference features as auxiliary information with linear smoothing and leverage a style-content guidance mechanism. This design effectively reduces content leakage from reference sketches and enhances synthesis quality, especially in cases with low structural similarity between reference and target sketches. Furthermore, we extend our framework to support controllable multi-style generation by integrating features from multiple reference sketches, coordinated via a joint AdaIN module. Extensive experiments demonstrate that our approach achieves high-quality sketch generation with accurate style alignment and improved flexibility in style control. The official implementation of M3S is available at https://github.com/CMACH508/M3S.
Expertise need not monopolize: Action-Specialized Mixture of Experts for Vision-Language-Action Learning
Oct 16, 2025Vision-Language-Action (VLA) models are experiencing rapid development and demonstrating promising capabilities in robotic manipulation tasks. However, scaling up VLA models presents several critical challenges: (1) Training new VLA models from scratch demands substantial computational resources and extensive datasets. Given the current scarcity of robot data, it becomes particularly valuable to fully leverage well-pretrained VLA model weights during the scaling process. (2) Real-time control requires carefully balancing model capacity with computational efficiency. To address these challenges, We propose AdaMoE, a Mixture-of-Experts (MoE) architecture that inherits pretrained weights from dense VLA models, and scales up the action expert by substituting the feedforward layers into sparsely activated MoE layers. AdaMoE employs a decoupling technique that decouples expert selection from expert weighting through an independent scale adapter working alongside the traditional router. This enables experts to be selected based on task relevance while contributing with independently controlled weights, allowing collaborative expert utilization rather than winner-takes-all dynamics. Our approach demonstrates that expertise need not monopolize. Instead, through collaborative expert utilization, we can achieve superior performance while maintaining computational efficiency. AdaMoE consistently outperforms the baseline model across key benchmarks, delivering performance gains of 1.8% on LIBERO and 9.3% on RoboTwin. Most importantly, a substantial 21.5% improvement in real-world experiments validates its practical effectiveness for robotic manipulation tasks.
LGE-Guided Cross-Modality Contrastive Learning for Gadolinium-Free Cardiomyopathy Screening in Cine CMR
Aug 23, 2025Cardiomyopathy, a principal contributor to heart failure and sudden cardiac mortality, demands precise early screening. Cardiac Magnetic Resonance (CMR), recognized as the diagnostic 'gold standard' through multiparametric protocols, holds the potential to serve as an accurate screening tool. However, its reliance on gadolinium contrast and labor-intensive interpretation hinders population-scale deployment. We propose CC-CMR, a Contrastive Learning and Cross-Modal alignment framework for gadolinium-free cardiomyopathy screening using cine CMR sequences. By aligning the latent spaces of cine CMR and Late Gadolinium Enhancement (LGE) sequences, our model encodes fibrosis-specific pathology into cine CMR embeddings. A Feature Interaction Module concurrently optimizes diagnostic precision and cross-modal feature congruence, augmented by an uncertainty-guided adaptive training mechanism that dynamically calibrates task-specific objectives to ensure model generalizability. Evaluated on multi-center data from 231 subjects, CC-CMR achieves accuracy of 0.943 (95% CI: 0.886-0.986), outperforming state-of-the-art cine-CMR-only models by 4.3% while eliminating gadolinium dependency, demonstrating its clinical viability for wide range of populations and healthcare environments.
DEPTH: Hallucination-Free Relation Extraction via Dependency-Aware Sentence Simplification and Two-tiered Hierarchical Refinement
Aug 20, 2025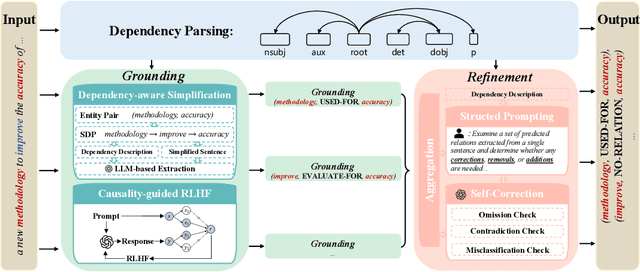

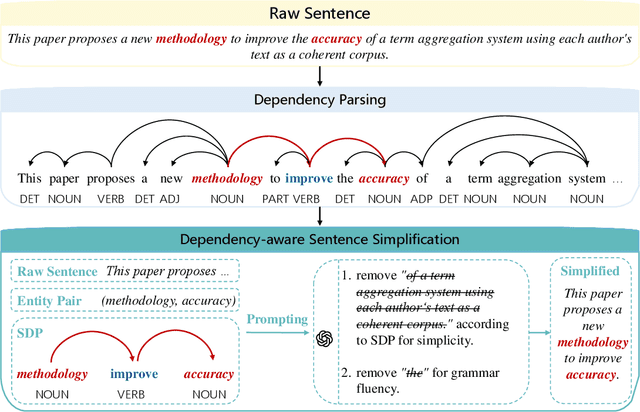

Relation extraction enables the construction of structured knowledge for many downstream applications. While large language models (LLMs) have shown great promise in this domain, most existing methods concentrate on relation classification, which predicts the semantic relation type between a related entity pair. However, we observe that LLMs often struggle to reliably determine whether a relation exists, especially in cases involving complex sentence structures or intricate semantics, which leads to spurious predictions. Such hallucinations can introduce noisy edges in knowledge graphs, compromising the integrity of structured knowledge and downstream reliability. To address these challenges, we propose DEPTH, a framework that integrates Dependency-aware sEntence simPlification and Two-tiered Hierarchical refinement into the relation extraction pipeline. Given a sentence and its candidate entity pairs, DEPTH operates in two stages: (1) the Grounding module extracts relations for each pair by leveraging their shortest dependency path, distilling the sentence into a minimal yet coherent relational context that reduces syntactic noise while preserving key semantics; (2) the Refinement module aggregates all local predictions and revises them based on a holistic understanding of the sentence, correcting omissions and inconsistencies. We further introduce a causality-driven reward model that mitigates reward hacking by disentangling spurious correlations, enabling robust fine-tuning via reinforcement learning with human feedback. Experiments on six benchmarks demonstrate that DEPTH reduces the average hallucination rate to 7.0\% while achieving a 17.2\% improvement in average F1 score over state-of-the-art baselines.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025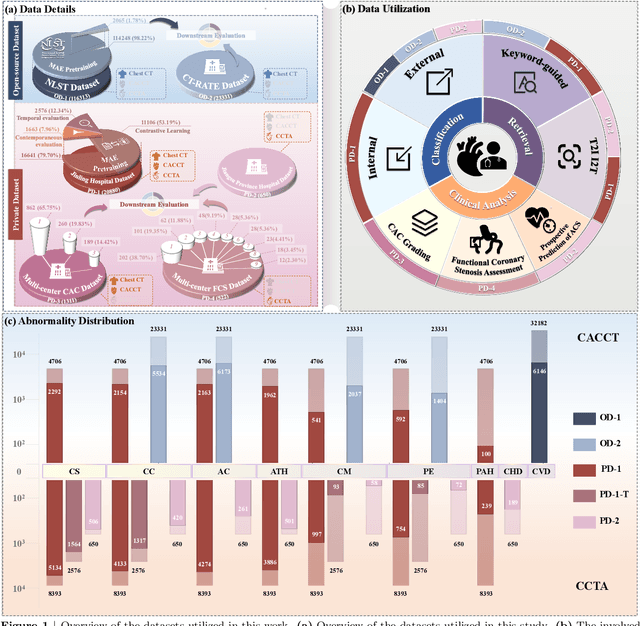
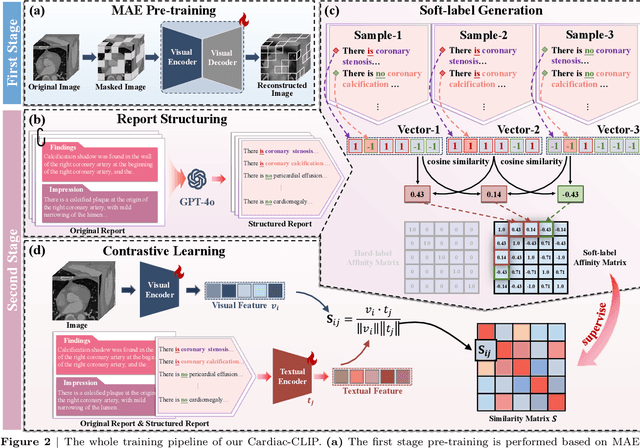
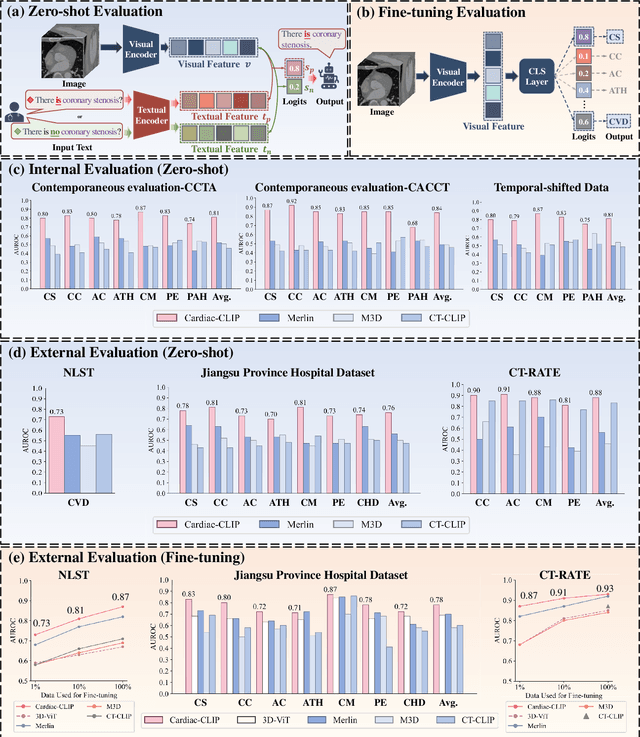
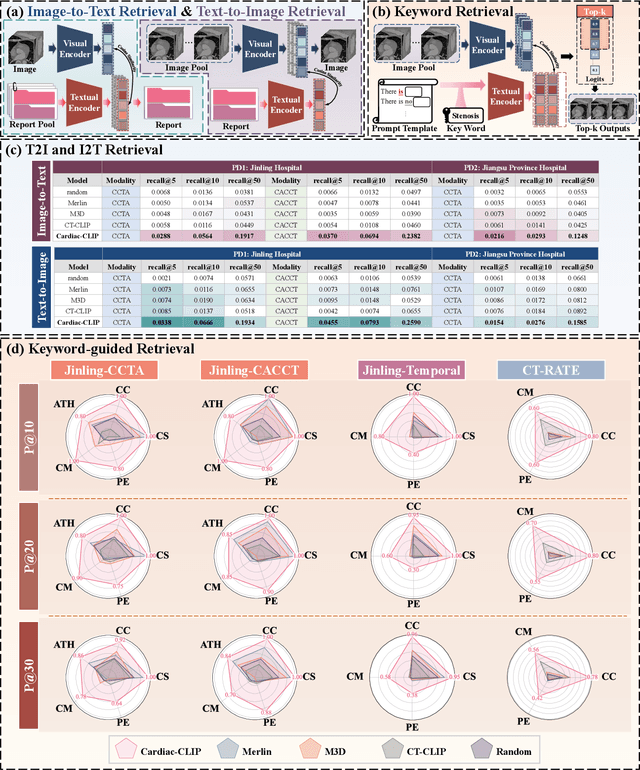
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
Synthesis by Design: Controlled Data Generation via Structural Guidance
Jun 09, 2025Mathematical reasoning remains challenging for LLMs due to complex logic and the need for precise computation. Existing methods enhance LLM reasoning by synthesizing datasets through problem rephrasing, but face issues with generation quality and problem complexity. To address this, we propose to extract structural information with generated problem-solving code from mathematical reasoning and guide data generation with structured solutions. Applied to MATH and GSM8K, our approach produces 39K problems with labeled intermediate steps and a 6.1K-problem benchmark of higher difficulty. Results on our benchmark show that model performance declines as reasoning length increases. Additionally, we conducted fine-tuning experiments using the proposed training data on a range of LLMs, and the results validate the effectiveness of our dataset. We hope the proposed method and dataset will contribute to future research in enhancing LLM reasoning capabilities.
Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable
May 20, 2025Existing detectors are often trained on biased datasets, leading to the possibility of overfitting on non-causal image attributes that are spuriously correlated with real/synthetic labels. While these biased features enhance performance on the training data, they result in substantial performance degradation when applied to unbiased datasets. One common solution is to perform dataset alignment through generative reconstruction, matching the semantic content between real and synthetic images. However, we revisit this approach and show that pixel-level alignment alone is insufficient. The reconstructed images still suffer from frequency-level misalignment, which can perpetuate spurious correlations. To illustrate, we observe that reconstruction models tend to restore the high-frequency details lost in real images (possibly due to JPEG compression), inadvertently creating a frequency-level misalignment, where synthetic images appear to have richer high-frequency content than real ones. This misalignment leads to models associating high-frequency features with synthetic labels, further reinforcing biased cues. To resolve this, we propose Dual Data Alignment (DDA), which aligns both the pixel and frequency domains. Moreover, we introduce two new test sets: DDA-COCO, containing DDA-aligned synthetic images for testing detector performance on the most aligned dataset, and EvalGEN, featuring the latest generative models for assessing detectors under new generative architectures such as visual auto-regressive generators. Finally, our extensive evaluations demonstrate that a detector trained exclusively on DDA-aligned MSCOCO could improve across 8 diverse benchmarks by a non-trivial margin, showing a +7.2% on in-the-wild benchmarks, highlighting the improved generalizability of unbiased detectors.
Intelligent4DSE: Optimizing High-Level Synthesis Design Space Exploration with Graph Neural Networks and Large Language Models
Apr 28, 2025High-level synthesis (HLS) design space exploration (DSE) is an optimization process in electronic design automation (EDA) that systematically explores high-level design configurations to achieve Pareto-optimal hardware implementations balancing performance, area, and power (PPA). To optimize this process, HLS prediction tasks often employ message-passing neural networks (MPNNs), leveraging complex architectures to achieve high accuracy. These predictors serve as evaluators in the DSE process, effectively bypassing the time-consuming estimations traditionally required by HLS tools. However, existing models often prioritize structural complexity and minimization of training loss, overlooking task-specific characteristics. Additionally, while evolutionary algorithms are widely used in DSE, they typically require extensive domain-specific knowledge to design effective crossover and mutation operators. To address these limitations, we propose CoGNNs-LLMEA, a framework that integrates a graph neural network with task-adaptive message passing and a large language model-enhanced evolutionary algorithm. As a predictive model, CoGNNs directly leverages intermediate representations generated from source code after compiler front-end processing, enabling prediction of quality of results (QoR) without invoking HLS tools. Due to its strong adaptability to tasks, CoGNNs can be tuned to predict post-HLS and post-implementation outcomes, effectively bridging the gap between high-level abstractions and physical implementation characteristics. CoGNNs achieves state-of-the-art prediction accuracy in post-HLS QoR prediction, reducing mean prediction errors by 2.8$\times$ for latency and 3.4$\times$ for resource utilization compared to baseline models.