 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Gigapixels: Bridging Local Inductive Bias and Long-Range Dependencies with Pixel-Mamba
Dec 21, 2024



Histopathology plays a critical role in medical diagnostics, with whole slide images (WSIs) offering valuable insights that directly influence clinical decision-making. However, the large size and complexity of WSIs may pose significant challenges for deep learning models, in both computational efficiency and effective representation learning. In this work, we introduce Pixel-Mamba, a novel deep learning architecture designed to efficiently handle gigapixel WSIs. Pixel-Mamba leverages the Mamba module, a state-space model (SSM) with linear memory complexity, and incorporates local inductive biases through progressively expanding tokens, akin to convolutional neural networks. This enables Pixel-Mamba to hierarchically combine both local and global information while efficiently addressing computational challenges. Remarkably, Pixel-Mamba achieves or even surpasses the quantitative performance of state-of-the-art (SOTA) foundation models that were pretrained on millions of WSIs or WSI-text pairs, in a range of tumor staging and survival analysis tasks, {\bf even without requiring any pathology-specific pretraining}. Extensive experiments demonstrate the efficacy of Pixel-Mamba as a powerful and efficient framework for end-to-end WSI analysis.
From Histopathology Images to Cell Clouds: Learning Slide Representations with Hierarchical Cell Transformer
Dec 21, 2024It is clinically crucial and potentially very beneficial to be able to analyze and model directly the spatial distributions of cells in histopathology whole slide images (WSI). However, most existing WSI datasets lack cell-level annotations, owing to the extremely high cost over giga-pixel images. Thus, it remains an open question whether deep learning models can directly and effectively analyze WSIs from the semantic aspect of cell distributions. In this work, we construct a large-scale WSI dataset with more than 5 billion cell-level annotations, termed WSI-Cell5B, and a novel hierarchical Cell Cloud Transformer (CCFormer) to tackle these challenges. WSI-Cell5B is based on 6,998 WSIs of 11 cancers from The Cancer Genome Atlas Program, and all WSIs are annotated per cell by coordinates and types. To the best of our knowledge, WSI-Cell5B is the first WSI-level large-scale dataset integrating cell-level annotations. On the other hand, CCFormer formulates the collection of cells in each WSI as a cell cloud and models cell spatial distribution. Specifically, Neighboring Information Embedding (NIE) is proposed to characterize the distribution of cells within the neighborhood of each cell, and a novel Hierarchical Spatial Perception (HSP) module is proposed to learn the spatial relationship among cells in a bottom-up manner. The clinical analysis indicates that WSI-Cell5B can be used to design clinical evaluation metrics based on counting cells that effectively assess the survival risk of patients. Extensive experiments on survival prediction and cancer staging show that learning from cell spatial distribution alone can already achieve state-of-the-art (SOTA) performance, i.e., CCFormer strongly outperforms other competing methods.
Leveraging Semantic Asymmetry for Precise Gross Tumor Volume Segmentation of Nasopharyngeal Carcinoma in Planning CT
Nov 27, 2024



In the radiation therapy of nasopharyngeal carcinoma (NPC), clinicians typically delineate the gross tumor volume (GTV) using non-contrast planning computed tomography to ensure accurate radiation dose delivery. However, the low contrast between tumors and adjacent normal tissues necessitates that radiation oncologists manually delineate the tumors, often relying on diagnostic MRI for guidance. % In this study, we propose a novel approach to directly segment NPC gross tumors on non-contrast planning CT images, circumventing potential registration errors when aligning MRI or MRI-derived tumor masks to planning CT. To address the low contrast issues between tumors and adjacent normal structures in planning CT, we introduce a 3D Semantic Asymmetry Tumor segmentation (SATs) method. Specifically, we posit that a healthy nasopharyngeal region is characteristically bilaterally symmetric, whereas the emergence of nasopharyngeal carcinoma disrupts this symmetry. Then, we propose a Siamese contrastive learning segmentation framework that minimizes the voxel-wise distance between original and flipped areas without tumor and encourages a larger distance between original and flipped areas with tumor. Thus, our approach enhances the sensitivity of features to semantic asymmetries. % Extensive experiments demonstrate that the proposed SATs achieves the leading NPC GTV segmentation performance in both internal and external testing, \emph{e.g.}, with at least 2\% absolute Dice score improvement and 12\% average distance error reduction when compared to other state-of-the-art methods in the external testing.
A Joint Representation Using Continuous and Discrete Features for Cardiovascular Diseases Risk Prediction on Chest CT Scans
Oct 24, 2024



Cardiovascular diseases (CVD) remain a leading health concern and contribute significantly to global mortality rates. While clinical advancements have led to a decline in CVD mortality, accurately identifying individuals who could benefit from preventive interventions remains an unsolved challenge in preventive cardiology. Current CVD risk prediction models, recommended by guidelines, are based on limited traditional risk factors or use CT imaging to acquire quantitative biomarkers, and still have limitations in predictive accuracy and applicability. On the other hand, end-to-end trained CVD risk prediction methods leveraging deep learning on CT images often fail to provide transparent and explainable decision grounds for assisting physicians. In this work, we proposed a novel joint representation that integrates discrete quantitative biomarkers and continuous deep features extracted from chest CT scans. Our approach initiated with a deep CVD risk classification model by capturing comprehensive continuous deep learning features while jointly obtaining currently clinical-established quantitative biomarkers via segmentation models. In the feature joint representation stage, we use an instance-wise feature-gated mechanism to align the continuous and discrete features, followed by a soft instance-wise feature interaction mechanism fostering independent and effective feature interaction for the final CVD risk prediction. Our method substantially improves CVD risk predictive performance and offers individual contribution analysis of each biomarker, which is important in assisting physicians' decision-making processes. We validated our method on a public chest low-dose CT dataset and a private external chest standard-dose CT patient cohort of 17,207 CT volumes from 6,393 unique subjects, and demonstrated superior predictive performance, achieving AUCs of 0.875 and 0.843, respectively.
Low-Rank Continual Pyramid Vision Transformer: Incrementally Segment Whole-Body Organs in CT with Light-Weighted Adaptation
Oct 07, 2024Deep segmentation networks achieve high performance when trained on specific datasets. However, in clinical practice, it is often desirable that pretrained segmentation models can be dynamically extended to enable segmenting new organs without access to previous training datasets or without training from scratch. This would ensure a much more efficient model development and deployment paradigm accounting for the patient privacy and data storage issues. This clinically preferred process can be viewed as a continual semantic segmentation (CSS) problem. Previous CSS works would either experience catastrophic forgetting or lead to unaffordable memory costs as models expand. In this work, we propose a new continual whole-body organ segmentation model with light-weighted low-rank adaptation (LoRA). We first train and freeze a pyramid vision transformer (PVT) base segmentation model on the initial task, then continually add light-weighted trainable LoRA parameters to the frozen model for each new learning task. Through a holistically exploration of the architecture modification, we identify three most important layers (i.e., patch-embedding, multi-head attention and feed forward layers) that are critical in adapting to the new segmentation tasks, while retaining the majority of the pretrained parameters fixed. Our proposed model continually segments new organs without catastrophic forgetting and meanwhile maintaining a low parameter increasing rate. Continually trained and tested on four datasets covering different body parts of a total of 121 organs, results show that our model achieves high segmentation accuracy, closely reaching the PVT and nnUNet upper bounds, and significantly outperforms other regularization-based CSS methods. When comparing to the leading architecture-based CSS method, our model has a substantial lower parameter increasing rate while achieving comparable performance.
End-to-end Multi-source Visual Prompt Tuning for Survival Analysis in Whole Slide Images
Sep 05, 2024



Survival analysis using pathology images poses a considerable challenge, as it requires the localization of relevant information from the multitude of tiles within whole slide images (WSIs). Current methods typically resort to a two-stage approach, where a pre-trained network extracts features from tiles, which are then used by survival models. This process, however, does not optimize the survival models in an end-to-end manner, and the pre-extracted features may not be ideally suited for survival prediction. To address this limitation, we present a novel end-to-end Visual Prompt Tuning framework for survival analysis, named VPTSurv. VPTSurv refines feature embeddings through an efficient encoder-decoder framework. The encoder remains fixed while the framework introduces tunable visual prompts and adaptors, thus permitting end-to-end training specifically for survival prediction by optimizing only the lightweight adaptors and the decoder. Moreover, the versatile VPTSurv framework accommodates multi-source information as prompts, thereby enriching the survival model. VPTSurv achieves substantial increases of 8.7% and 12.5% in the C-index on two immunohistochemical pathology image datasets. These significant improvements highlight the transformative potential of the end-to-end VPT framework over traditional two-stage methods.
From Yes-Men to Truth-Tellers: Addressing Sycophancy in Large Language Models with Pinpoint Tuning
Sep 03, 2024



Large Language Models (LLMs) tend to prioritize adherence to user prompts over providing veracious responses, leading to the sycophancy issue. When challenged by users, LLMs tend to admit mistakes and provide inaccurate responses even if they initially provided the correct answer. Recent works propose to employ supervised fine-tuning (SFT) to mitigate the sycophancy issue, while it typically leads to the degeneration of LLMs' general capability. To address the challenge, we propose a novel supervised pinpoint tuning (SPT), where the region-of-interest modules are tuned for a given objective. Specifically, SPT first reveals and verifies a small percentage (<5%) of the basic modules, which significantly affect a particular behavior of LLMs. i.e., sycophancy. Subsequently, SPT merely fine-tunes these identified modules while freezing the rest. To verify the effectiveness of the proposed SPT, we conduct comprehensive experiments, demonstrating that SPT significantly mitigates the sycophancy issue of LLMs (even better than SFT). Moreover, SPT introduces limited or even no side effects on the general capability of LLMs. Our results shed light on how to precisely, effectively, and efficiently explain and improve the targeted ability of LLMs.
LIDIA: Precise Liver Tumor Diagnosis on Multi-Phase Contrast-Enhanced CT via Iterative Fusion and Asymmetric Contrastive Learning
Jul 18, 2024



The early detection and precise diagnosis of liver tumors are tasks of critical clinical value, yet they pose significant challenges due to the high heterogeneity and variability of liver tumors. In this work, a precise LIver tumor DIAgnosis network on multi-phase contrast-enhance CT, named LIDIA, is proposed for real-world scenario. To fully utilize all available phases in contrast-enhanced CT, LIDIA first employs the iterative fusion module to aggregate variable numbers of image phases, thereby capturing the features of lesions at different phases for better tumor diagnosis. To effectively mitigate the high heterogeneity problem of liver tumors, LIDIA incorporates asymmetric contrastive learning to enhance the discriminability between different classes. To evaluate our method, we constructed a large-scale dataset comprising 1,921 patients and 8,138 lesions. LIDIA has achieved an average AUC of 93.6% across eight different types of lesions, demonstrating its effectiveness. Besides, LIDIA also demonstrated strong generalizability with an average AUC of 89.3% when tested on an external cohort of 828 patients.
Improved Esophageal Varices Assessment from Non-Contrast CT Scans
Jul 18, 2024



Esophageal varices (EV), a serious health concern resulting from portal hypertension, are traditionally diagnosed through invasive endoscopic procedures. Despite non-contrast computed tomography (NC-CT) imaging being a less expensive and non-invasive imaging modality, it has yet to gain full acceptance as a primary clinical diagnostic tool for EV evaluation. To overcome existing diagnostic challenges, we present the Multi-Organ-cOhesion-Network (MOON), a novel framework enhancing the analysis of critical organ features in NC-CT scans for effective assessment of EV. Drawing inspiration from the thorough assessment practices of radiologists, MOON establishes a cohesive multiorgan analysis model that unifies the imaging features of the related organs of EV, namely esophagus, liver, and spleen. This integration significantly increases the diagnostic accuracy for EV. We have compiled an extensive NC-CT dataset of 1,255 patients diagnosed with EV, spanning three grades of severity. Each case is corroborated by endoscopic diagnostic results. The efficacy of MOON has been substantiated through a validation process involving multi-fold cross-validation on 1,010 cases and an independent test on 245 cases, exhibiting superior diagnostic performance compared to methods focusing solely on the esophagus (for classifying severe grade: AUC of 0.864 versus 0.803, and for moderate to severe grades: AUC of 0.832 versus 0.793). To our knowledge, MOON is the first work to incorporate a synchronized multi-organ NC-CT analysis for EV assessment, providing a more acceptable and minimally invasive alternative for patients compared to traditional endoscopy.
Cross-Phase Mutual Learning Framework for Pulmonary Embolism Identification on Non-Contrast CT Scans
Jul 16, 2024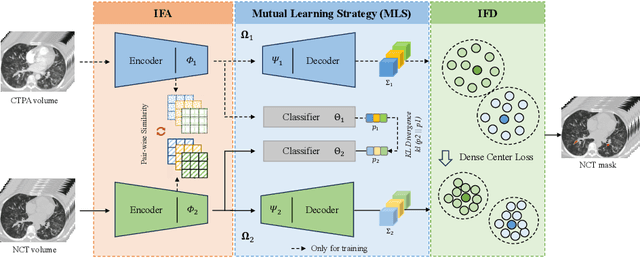

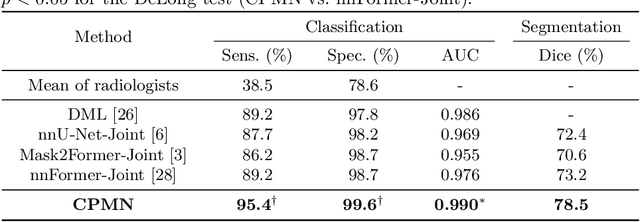
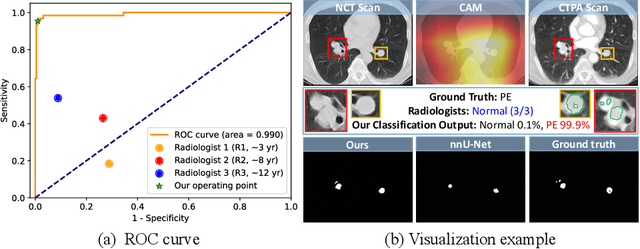
Pulmonary embolism (PE) is a life-threatening condition where rapid and accurate diagnosis is imperative yet difficult due to predominantly atypical symptomatology. Computed tomography pulmonary angiography (CTPA) is acknowledged as the gold standard imaging tool in clinics, yet it can be contraindicated for emergency department (ED) patients and represents an onerous procedure, thus necessitating PE identification through non-contrast CT (NCT) scans. In this work, we explore the feasibility of applying a deep-learning approach to NCT scans for PE identification. We propose a novel Cross-Phase Mutual learNing framework (CPMN) that fosters knowledge transfer from CTPA to NCT, while concurrently conducting embolism segmentation and abnormality classification in a multi-task manner. The proposed CPMN leverages the Inter-Feature Alignment (IFA) strategy that enhances spatial contiguity and mutual learning between the dual-pathway network, while the Intra-Feature Discrepancy (IFD) strategy can facilitate precise segmentation of PE against complex backgrounds for single-pathway networks. For a comprehensive assessment of the proposed approach, a large-scale dual-phase dataset containing 334 PE patients and 1,105 normal subjects has been established. Experimental results demonstrate that CPMN achieves the leading identification performance, which is 95.4\% and 99.6\% in patient-level sensitivity and specificity on NCT scans, indicating the potential of our approach as an economical, accessible, and precise tool for PE identification in clinical practice.