 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimMIL: A Universal Weakly Supervised Pre-Training Framework for Multi-Instance Learning in Whole Slide Pathology Images
May 10, 2025Various multi-instance learning (MIL) based approaches have been developed and successfully applied to whole-slide pathological images (WSI). Existing MIL methods emphasize the importance of feature aggregators, but largely neglect the instance-level representation learning. They assume that the availability of a pre-trained feature extractor can be directly utilized or fine-tuned, which is not always the case. This paper proposes to pre-train feature extractor for MIL via a weakly-supervised scheme, i.e., propagating the weak bag-level labels to the corresponding instances for supervised learning. To learn effective features for MIL, we further delve into several key components, including strong data augmentation, a non-linear prediction head and the robust loss function. We conduct experiments on common large-scale WSI datasets and find it achieves better performance than other pre-training schemes (e.g., ImageNet pre-training and self-supervised learning) in different downstream tasks. We further show the compatibility and scalability of the proposed scheme by deploying it in fine-tuning the pathological-specific models and pre-training on merged multiple datasets. To our knowledge, this is the first work focusing on the representation learning for MIL.
From Pixels to Gigapixels: Bridging Local Inductive Bias and Long-Range Dependencies with Pixel-Mamba
Dec 21, 2024



Histopathology plays a critical role in medical diagnostics, with whole slide images (WSIs) offering valuable insights that directly influence clinical decision-making. However, the large size and complexity of WSIs may pose significant challenges for deep learning models, in both computational efficiency and effective representation learning. In this work, we introduce Pixel-Mamba, a novel deep learning architecture designed to efficiently handle gigapixel WSIs. Pixel-Mamba leverages the Mamba module, a state-space model (SSM) with linear memory complexity, and incorporates local inductive biases through progressively expanding tokens, akin to convolutional neural networks. This enables Pixel-Mamba to hierarchically combine both local and global information while efficiently addressing computational challenges. Remarkably, Pixel-Mamba achieves or even surpasses the quantitative performance of state-of-the-art (SOTA) foundation models that were pretrained on millions of WSIs or WSI-text pairs, in a range of tumor staging and survival analysis tasks, {\bf even without requiring any pathology-specific pretraining}. Extensive experiments demonstrate the efficacy of Pixel-Mamba as a powerful and efficient framework for end-to-end WSI analysis.
From Histopathology Images to Cell Clouds: Learning Slide Representations with Hierarchical Cell Transformer
Dec 21, 2024It is clinically crucial and potentially very beneficial to be able to analyze and model directly the spatial distributions of cells in histopathology whole slide images (WSI). However, most existing WSI datasets lack cell-level annotations, owing to the extremely high cost over giga-pixel images. Thus, it remains an open question whether deep learning models can directly and effectively analyze WSIs from the semantic aspect of cell distributions. In this work, we construct a large-scale WSI dataset with more than 5 billion cell-level annotations, termed WSI-Cell5B, and a novel hierarchical Cell Cloud Transformer (CCFormer) to tackle these challenges. WSI-Cell5B is based on 6,998 WSIs of 11 cancers from The Cancer Genome Atlas Program, and all WSIs are annotated per cell by coordinates and types. To the best of our knowledge, WSI-Cell5B is the first WSI-level large-scale dataset integrating cell-level annotations. On the other hand, CCFormer formulates the collection of cells in each WSI as a cell cloud and models cell spatial distribution. Specifically, Neighboring Information Embedding (NIE) is proposed to characterize the distribution of cells within the neighborhood of each cell, and a novel Hierarchical Spatial Perception (HSP) module is proposed to learn the spatial relationship among cells in a bottom-up manner. The clinical analysis indicates that WSI-Cell5B can be used to design clinical evaluation metrics based on counting cells that effectively assess the survival risk of patients. Extensive experiments on survival prediction and cancer staging show that learning from cell spatial distribution alone can already achieve state-of-the-art (SOTA) performance, i.e., CCFormer strongly outperforms other competing methods.
Relational Contrastive Learning and Masked Image Modeling for Scene Text Recognition
Nov 19, 2024



Context-aware methods have achieved remarkable advancements in supervised scene text recognition by leveraging semantic priors from words. Considering the heterogeneity of text and background in STR, we propose that such contextual priors can be reinterpreted as the relations between textual elements, serving as effective self-supervised labels for representation learning. However, textual relations are restricted to the finite size of the dataset due to lexical dependencies, which causes over-fitting problem, thus compromising the representation quality. To address this, our work introduces a unified framework of Relational Contrastive Learning and Masked Image Modeling for STR (RCMSTR), which explicitly models the enriched textual relations. For the RCL branch, we first introduce the relational rearrangement module to cultivate new relations on the fly. Based on this, we further conduct relational contrastive learning to model the intra- and inter-hierarchical relations for frames, sub-words and words. On the other hand, MIM can naturally boost the context information via masking, where we find that the block masking strategy is more effective for STR. For the effective integration of RCL and MIM, we also introduce a novel decoupling design aimed at mitigating the impact of masked images on contrastive learning. Additionally, to enhance the compatibility of MIM with CNNs, we propose the adoption of sparse convolutions and directly sharing the weights with dense convolutions in training. The proposed RCMSTR demonstrates superior performance in various evaluation protocols for different STR-related downstream tasks, outperforming the existing state-of-the-art self-supervised STR techniques. Ablation studies and qualitative experimental results further validate the effectiveness of our method. The code and pre-trained models will be available at https://github.com/ThunderVVV/RCMSTR .
Background Clustering Pre-training for Few-shot Segmentation
Dec 06, 2023



Recent few-shot segmentation (FSS) methods introduce an extra pre-training stage before meta-training to obtain a stronger backbone, which has become a standard step in few-shot learning. Despite the effectiveness, current pre-training scheme suffers from the merged background problem: only base classes are labelled as foregrounds, making it hard to distinguish between novel classes and actual background. In this paper, we propose a new pre-training scheme for FSS via decoupling the novel classes from background, called Background Clustering Pre-Training (BCPT). Specifically, we adopt online clustering to the pixel embeddings of merged background to explore the underlying semantic structures, bridging the gap between pre-training and adaptation to novel classes. Given the clustering results, we further propose the background mining loss and leverage base classes to guide the clustering process, improving the quality and stability of clustering results. Experiments on PASCAL-5i and COCO-20i show that BCPT yields advanced performance. Code will be available.
Context-Aware Prompt Tuning for Vision-Language Model with Dual-Alignment
Sep 08, 2023



Large-scale vision-language models (VLMs), e.g., CLIP, learn broad visual concepts from tedious training data, showing superb generalization ability. Amount of prompt learning methods have been proposed to efficiently adapt the VLMs to downstream tasks with only a few training samples. We introduce a novel method to improve the prompt learning of vision-language models by incorporating pre-trained large language models (LLMs), called Dual-Aligned Prompt Tuning (DuAl-PT). Learnable prompts, like CoOp, implicitly model the context through end-to-end training, which are difficult to control and interpret. While explicit context descriptions generated by LLMs, like GPT-3, can be directly used for zero-shot classification, such prompts are overly relying on LLMs and still underexplored in few-shot domains. With DuAl-PT, we propose to learn more context-aware prompts, benefiting from both explicit and implicit context modeling. To achieve this, we introduce a pre-trained LLM to generate context descriptions, and we encourage the prompts to learn from the LLM's knowledge by alignment, as well as the alignment between prompts and local image features. Empirically, DuAl-PT achieves superior performance on 11 downstream datasets on few-shot recognition and base-to-new generalization. Hopefully, DuAl-PT can serve as a strong baseline. Code will be available.
Relational Contrastive Learning for Scene Text Recognition
Aug 01, 2023Context-aware methods achieved great success in supervised scene text recognition via incorporating semantic priors from words. We argue that such prior contextual information can be interpreted as the relations of textual primitives due to the heterogeneous text and background, which can provide effective self-supervised labels for representation learning. However, textual relations are restricted to the finite size of dataset due to lexical dependencies, which causes the problem of over-fitting and compromises representation robustness. To this end, we propose to enrich the textual relations via rearrangement, hierarchy and interaction, and design a unified framework called RCLSTR: Relational Contrastive Learning for Scene Text Recognition. Based on causality, we theoretically explain that three modules suppress the bias caused by the contextual prior and thus guarantee representation robustness. Experiments on representation quality show that our method outperforms state-of-the-art self-supervised STR methods. Code is available at https://github.com/ThunderVVV/RCLSTR.
SLPD: Slide-level Prototypical Distillation for WSIs
Jul 20, 2023Improving the feature representation ability is the foundation of many whole slide pathological image (WSIs) tasks. Recent works have achieved great success in pathological-specific self-supervised learning (SSL). However, most of them only focus on learning patch-level representations, thus there is still a gap between pretext and slide-level downstream tasks, e.g., subtyping, grading and staging. Aiming towards slide-level representations, we propose Slide-Level Prototypical Distillation (SLPD) to explore intra- and inter-slide semantic structures for context modeling on WSIs. Specifically, we iteratively perform intra-slide clustering for the regions (4096x4096 patches) within each WSI to yield the prototypes and encourage the region representations to be closer to the assigned prototypes. By representing each slide with its prototypes, we further select similar slides by the set distance of prototypes and assign the regions by cross-slide prototypes for distillation. SLPD achieves state-of-the-art results on multiple slide-level benchmarks and demonstrates that representation learning of semantic structures of slides can make a suitable proxy task for WSI analysis. Code will be available at https://github.com/Carboxy/SLPD.
Interventional Bag Multi-Instance Learning On Whole-Slide Pathological Images
Mar 13, 2023



Multi-instance learning (MIL) is an effective paradigm for whole-slide pathological images (WSIs) classification to handle the gigapixel resolution and slide-level label. Prevailing MIL methods primarily focus on improving the feature extractor and aggregator. However, one deficiency of these methods is that the bag contextual prior may trick the model into capturing spurious correlations between bags and labels. This deficiency is a confounder that limits the performance of existing MIL methods. In this paper, we propose a novel scheme, Interventional Bag Multi-Instance Learning (IBMIL), to achieve deconfounded bag-level prediction. Unlike traditional likelihood-based strategies, the proposed scheme is based on the backdoor adjustment to achieve the interventional training, thus is capable of suppressing the bias caused by the bag contextual prior. Note that the principle of IBMIL is orthogonal to existing bag MIL methods. Therefore, IBMIL is able to bring consistent performance boosting to existing schemes, achieving new state-of-the-art performance. Code is available at https://github.com/HHHedo/IBMIL.
Interventional Multi-Instance Learning with Deconfounded Instance-Level Prediction
Apr 22, 2022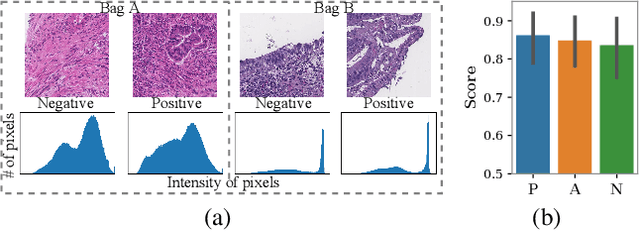
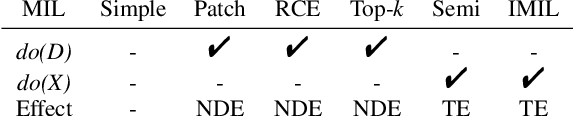
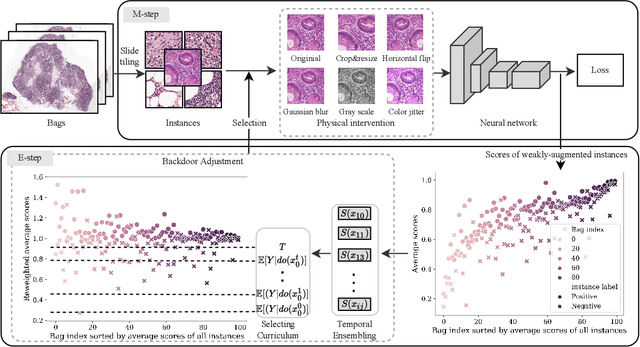
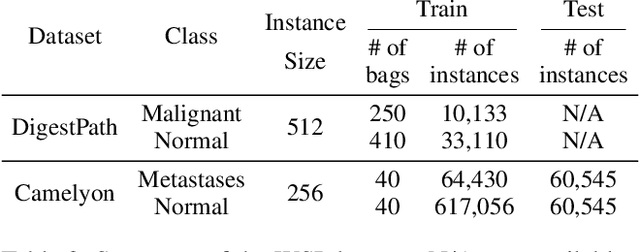
When applying multi-instance learning (MIL) to make predictions for bags of instances, the prediction accuracy of an instance often depends on not only the instance itself but also its context in the corresponding bag. From the viewpoint of causal inference, such bag contextual prior works as a confounder and may result in model robustness and interpretability issues. Focusing on this problem, we propose a novel interventional multi-instance learning (IMIL) framework to achieve deconfounded instance-level prediction. Unlike traditional likelihood-based strategies, we design an Expectation-Maximization (EM) algorithm based on causal intervention, providing a robust instance selection in the training phase and suppressing the bias caused by the bag contextual prior. Experiments on pathological image analysis demonstrate that our IMIL method substantially reduces false positives and outperforms state-of-the-art MIL methods.