 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueezeformer: An Efficient Transformer for Automatic Speech Recognition
Jun 02, 2022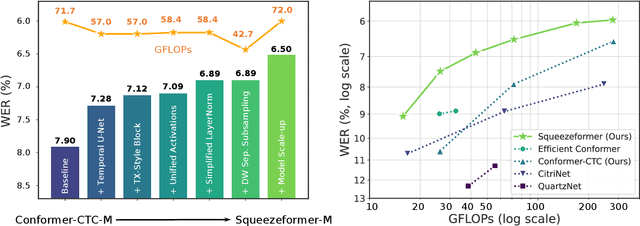
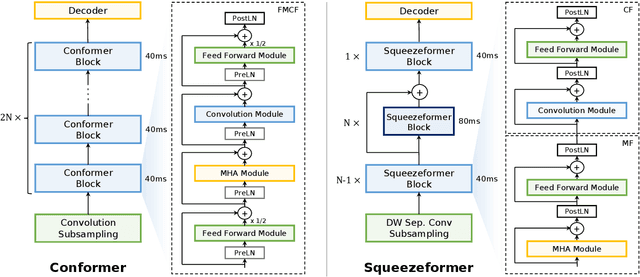
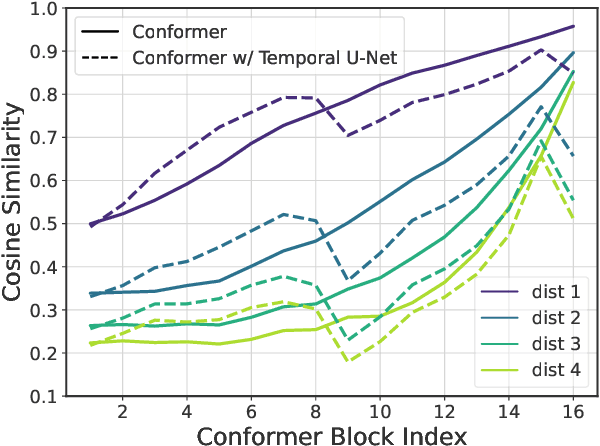
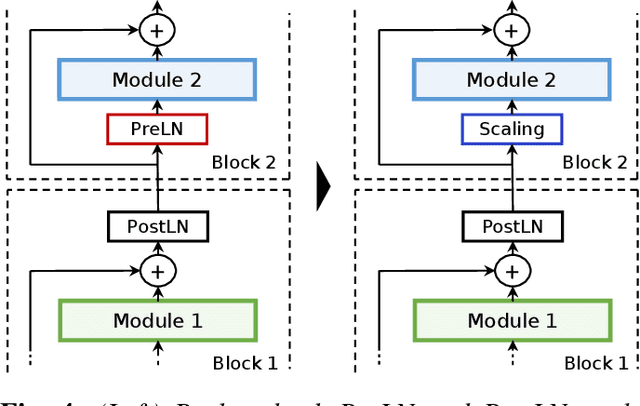
The recently proposed Conformer model has become the de facto backbone model for various downstream speech tasks based on its hybrid attention-convolution architecture that captures both local and global features. However, through a series of systematic studies, we find that the Conformer architecture's design choices are not optimal. After reexamining the design choices for both the macro and micro-architecture of Conformer, we propose the Squeezeformer model, which consistently outperforms the state-of-the-art ASR models under the same training schemes. In particular, for the macro-architecture, Squeezeformer incorporates (i) the Temporal U-Net structure, which reduces the cost of the multi-head attention modules on long sequences, and (ii) a simpler block structure of feed-forward module, followed up by multi-head attention or convolution modules, instead of the Macaron structure proposed in Conformer. Furthermore, for the micro-architecture, Squeezeformer (i) simplifies the activations in the convolutional block, (ii) removes redundant Layer Normalization operations, and (iii) incorporates an efficient depth-wise downsampling layer to efficiently sub-sample the input signal. Squeezeformer achieves state-of-the-art results of 7.5%, 6.5%, and 6.0% word-error-rate on Librispeech test-other without external language models. This is 3.1%, 1.4%, and 0.6% better than Conformer-CTC with the same number of FLOPs. Our code is open-sourced and available online.
UnrealNAS: Can We Search Neural Architectures with Unreal Data?
May 19, 2022
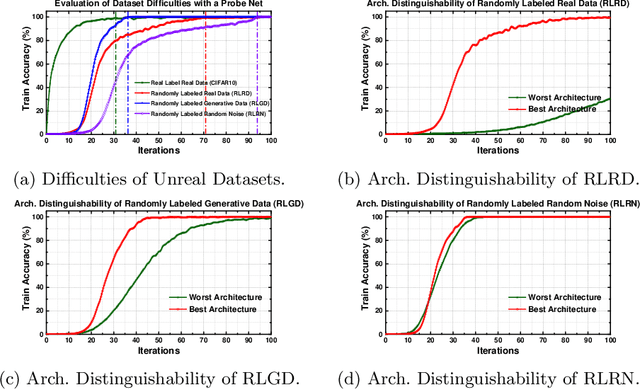
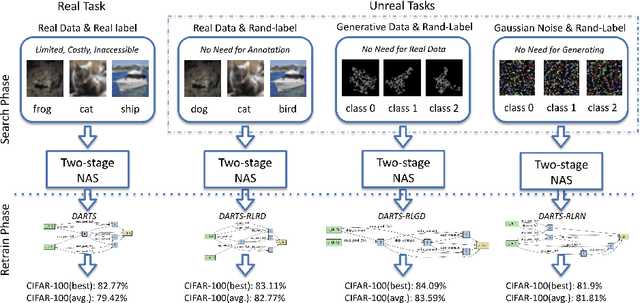
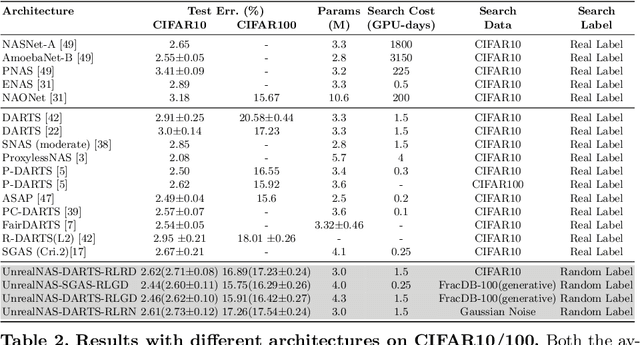
Neural architecture search (NAS) has shown great success in the automatic design of deep neural networks (DNNs). However, the best way to use data to search network architectures is still unclear and under exploration. Previous work has analyzed the necessity of having ground-truth labels in NAS and inspired broad interest. In this work, we take a further step to question whether real data is necessary for NAS to be effective. The answer to this question is important for applications with limited amount of accessible data, and can help people improve NAS by leveraging the extra flexibility of data generation. To explore if NAS needs real data, we construct three types of unreal datasets using: 1) randomly labeled real images; 2) generated images and labels; and 3) generated Gaussian noise with random labels. These datasets facilitate to analyze the generalization and expressivity of the searched architectures. We study the performance of architectures searched on these constructed datasets using popular differentiable NAS methods. Extensive experiments on CIFAR, ImageNet and CheXpert show that the searched architectures can achieve promising results compared with those derived from the conventional NAS pipeline with real labeled data, suggesting the feasibility of performing NAS with unreal data.
Cross-Domain Object Detection with Mean-Teacher Transformer
May 03, 2022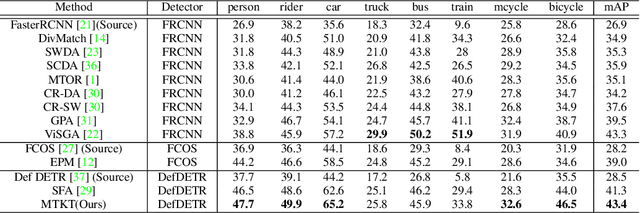
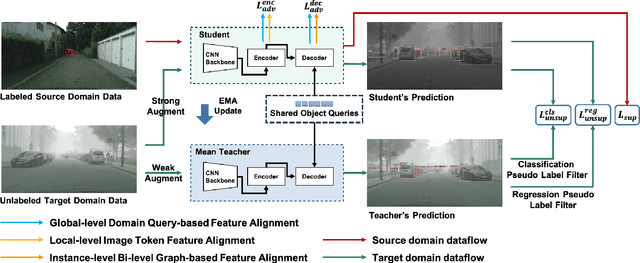
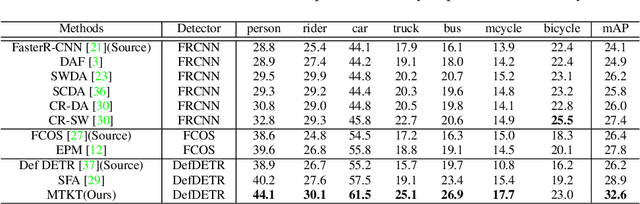
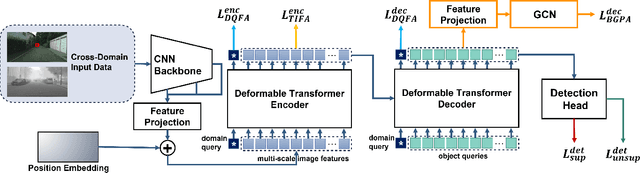
Recently, DEtection TRansformer (DETR), an end-to-end object detection pipeline, has achieved promising performance. However, it requires large-scale labeled data and suffers from domain shift, especially when no labeled data is available in the target domain. To solve this problem, we propose an end-to-end cross-domain detection transformer based on the mean teacher knowledge transfer (MTKT), which transfers knowledge between domains via pseudo labels. To improve the quality of pseudo labels in the target domain, which is a crucial factor for better domain adaptation, we design three levels of source-target feature alignment strategies based on the architecture of the Transformer, including domain query-based feature alignment (DQFA), bi-level-graph-based prototype alignment (BGPA), and token-wise image feature alignment (TIFA). These three levels of feature alignment match the global, local, and instance features between source and target, respectively. With these strategies, more accurate pseudo labels can be obtained, and knowledge can be better transferred from source to target, thus improving the cross-domain capability of the detection transformer. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performance on three domain adaptation scenarios, especially the result of Sim10k to Cityscapes scenario is remarkably improved from 52.6 mAP to 57.9 mAP. Code will be released.
PreTraM: Self-Supervised Pre-training via Connecting Trajectory and Map
Apr 21, 2022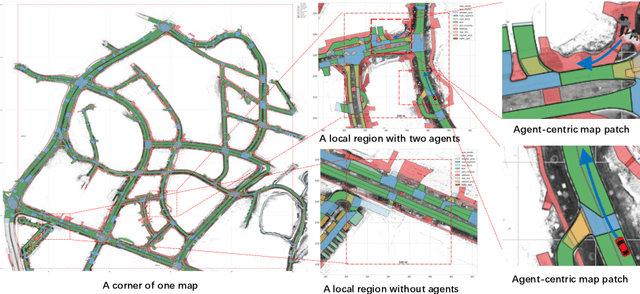
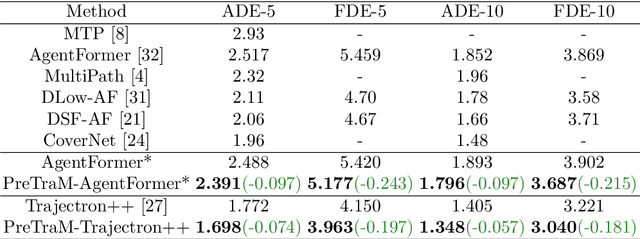
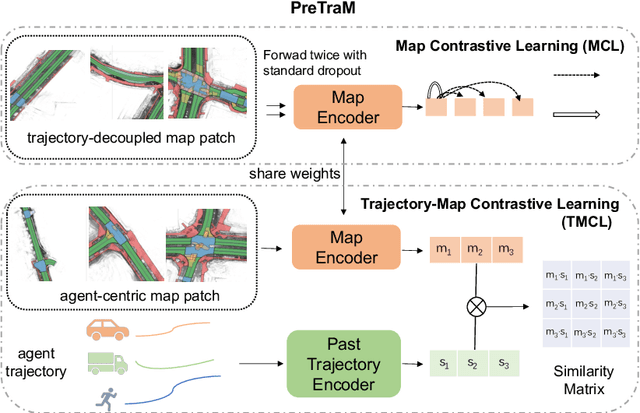

Deep learning has recently achieved significant progress in trajectory forecasting. However, the scarcity of trajectory data inhibits the data-hungry deep-learning models from learning good representations. While mature representation learning methods exist in computer vision and natural language processing, these pre-training methods require large-scale data. It is hard to replicate these approaches in trajectory forecasting due to the lack of adequate trajectory data (e.g., 34K samples in the nuScenes dataset). To work around the scarcity of trajectory data, we resort to another data modality closely related to trajectories-HD-maps, which is abundantly provided in existing datasets. In this paper, we propose PreTraM, a self-supervised pre-training scheme via connecting trajectories and maps for trajectory forecasting. Specifically, PreTraM consists of two parts: 1) Trajectory-Map Contrastive Learning, where we project trajectories and maps to a shared embedding space with cross-modal contrastive learning, and 2) Map Contrastive Learning, where we enhance map representation with contrastive learning on large quantities of HD-maps. On top of popular baselines such as AgentFormer and Trajectron++, PreTraM boosts their performance by 5.5% and 6.9% relatively in FDE-10 on the challenging nuScenes dataset. We show that PreTraM improves data efficiency and scales well with model size.
K-LITE: Learning Transferable Visual Models with External Knowledge
Apr 20, 2022
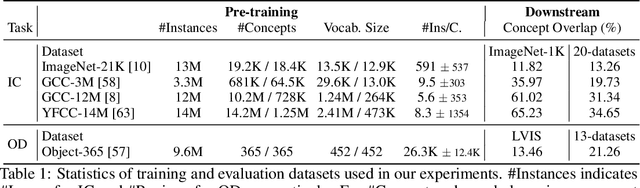
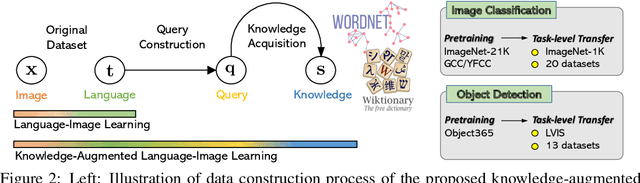
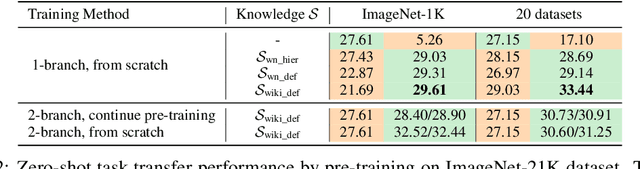
Recent state-of-the-art computer vision systems are trained from natural language supervision, ranging from simple object category names to descriptive captions. This free form of supervision ensures high generality and usability of the learned visual models, based on extensive heuristics on data collection to cover as many visual concepts as possible. Alternatively, learning with external knowledge about images is a promising way which leverages a much more structured source of supervision. In this paper, we propose K-LITE (Knowledge-augmented Language-Image Training and Evaluation), a simple strategy to leverage external knowledge to build transferable visual systems: In training, it enriches entities in natural language with WordNet and Wiktionary knowledge, leading to an efficient and scalable approach to learning image representations that can understand both visual concepts and their knowledge; In evaluation, the natural language is also augmented with external knowledge and then used to reference learned visual concepts (or describe new ones) to enable zero-shot and few-shot transfer of the pre-trained models. We study the performance of K-LITE on two important computer vision problems, image classification and object detection, benchmarking on 20 and 13 different existing datasets, respectively. The proposed knowledge-augmented models show significant improvement in transfer learning performance over existing methods.
Staged Training for Transformer Language Models
Mar 11, 2022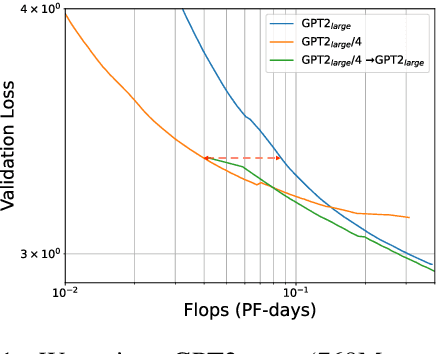
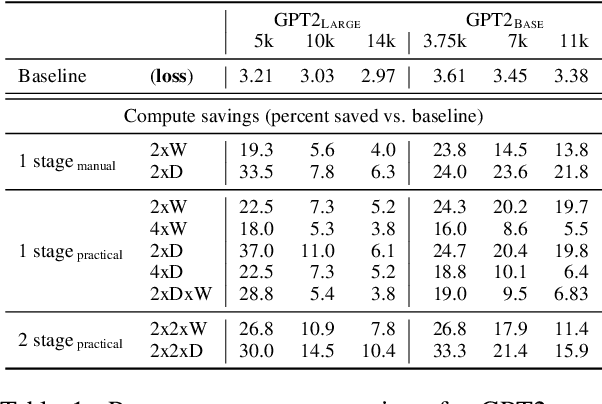
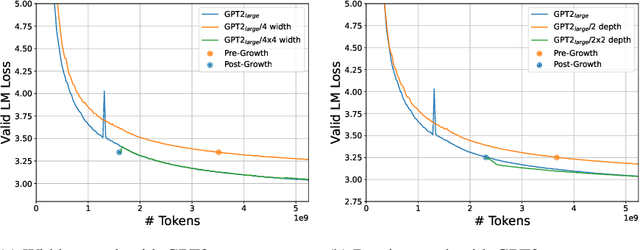
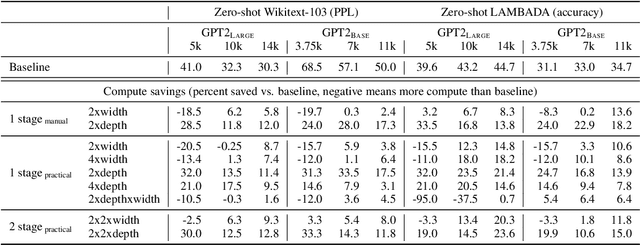
The current standard approach to scaling transformer language models trains each model size from a different random initialization. As an alternative, we consider a staged training setup that begins with a small model and incrementally increases the amount of compute used for training by applying a "growth operator" to increase the model depth and width. By initializing each stage with the output of the previous one, the training process effectively re-uses the compute from prior stages and becomes more efficient. Our growth operators each take as input the entire training state (including model parameters, optimizer state, learning rate schedule, etc.) and output a new training state from which training continues. We identify two important properties of these growth operators, namely that they preserve both the loss and the "training dynamics" after applying the operator. While the loss-preserving property has been discussed previously, to the best of our knowledge this work is the first to identify the importance of preserving the training dynamics (the rate of decrease of the loss during training). To find the optimal schedule for stages, we use the scaling laws from (Kaplan et al., 2020) to find a precise schedule that gives the most compute saving by starting a new stage when training efficiency starts decreasing. We empirically validate our growth operators and staged training for autoregressive language models, showing up to 22% compute savings compared to a strong baseline trained from scratch. Our code is available at https://github.com/allenai/staged-training.
Differentiable NAS Framework and Application to Ads CTR Prediction
Oct 25, 2021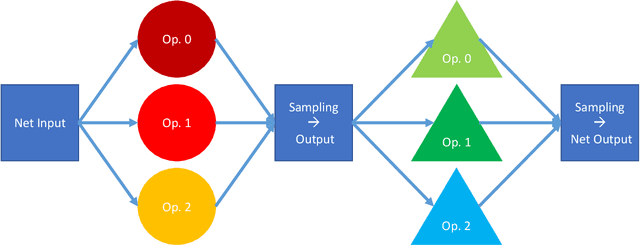
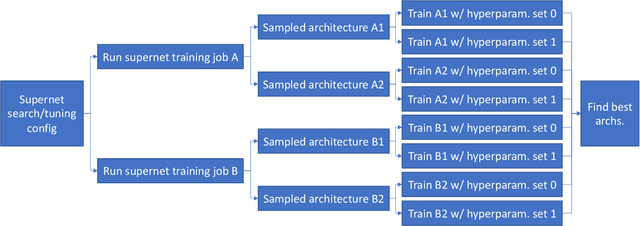
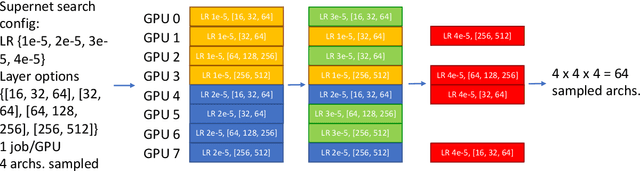
Neural architecture search (NAS) methods aim to automatically find the optimal deep neural network (DNN) architecture as measured by a given objective function, typically some combination of task accuracy and inference efficiency. For many areas, such as computer vision and natural language processing, this is a critical, yet still time consuming process. New NAS methods have recently made progress in improving the efficiency of this process. We implement an extensible and modular framework for Differentiable Neural Architecture Search (DNAS) to help solve this problem. We include an overview of the major components of our codebase and how they interact, as well as a section on implementing extensions to it (including a sample), in order to help users adopt our framework for their applications across different categories of deep learning models. To assess the capabilities of our methodology and implementation, we apply DNAS to the problem of ads click-through rate (CTR) prediction, arguably the highest-value and most worked on AI problem at hyperscalers today. We develop and tailor novel search spaces to a Deep Learning Recommendation Model (DLRM) backbone for CTR prediction, and report state-of-the-art results on the Criteo Kaggle CTR prediction dataset.
Multi-source Few-shot Domain Adaptation
Sep 25, 2021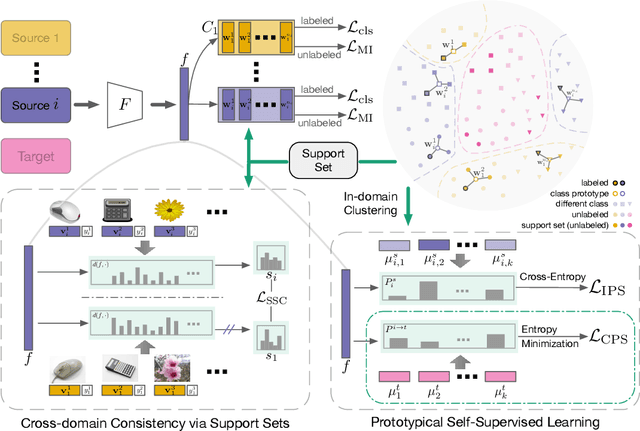
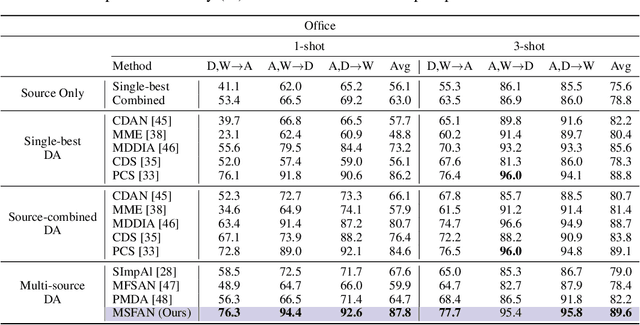
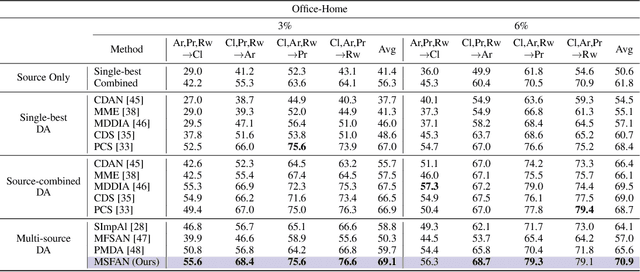

Multi-source Domain Adaptation (MDA) aims to transfer predictive models from multiple, fully-labeled source domains to an unlabeled target domain. However, in many applications, relevant labeled source datasets may not be available, and collecting source labels can be as expensive as labeling the target data itself. In this paper, we investigate Multi-source Few-shot Domain Adaptation (MFDA): a new domain adaptation scenario with limited multi-source labels and unlabeled target data. As we show, existing methods often fail to learn discriminative features for both source and target domains in the MFDA setting. Therefore, we propose a novel framework, termed Multi-Source Few-shot Adaptation Network (MSFAN), which can be trained end-to-end in a non-adversarial manner. MSFAN operates by first using a type of prototypical, multi-domain, self-supervised learning to learn features that are not only domain-invariant but also class-discriminative. Second, MSFAN uses a small, labeled support set to enforce feature consistency and domain invariance across domains. Finally, prototypes from multiple sources are leveraged to learn better classifiers. Compared with state-of-the-art MDA methods, MSFAN improves the mean classification accuracy over different domain pairs on MFDA by 20.2%, 9.4%, and 16.2% on Office, Office-Home, and DomainNet, respectively.
What's Hidden in a One-layer Randomly Weighted Transformer?
Sep 08, 2021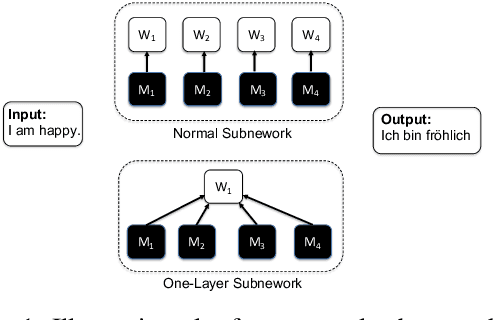
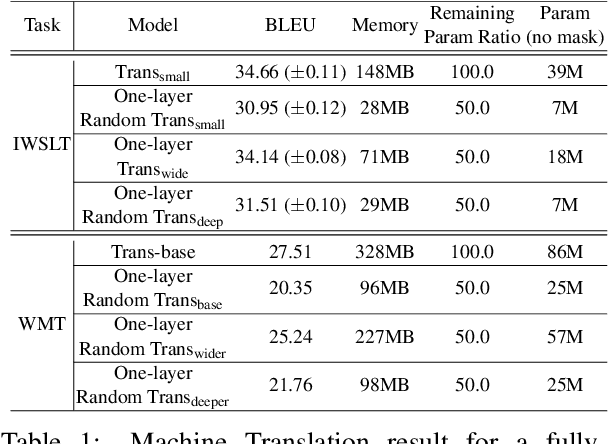
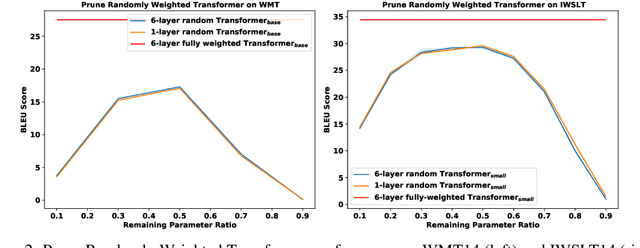
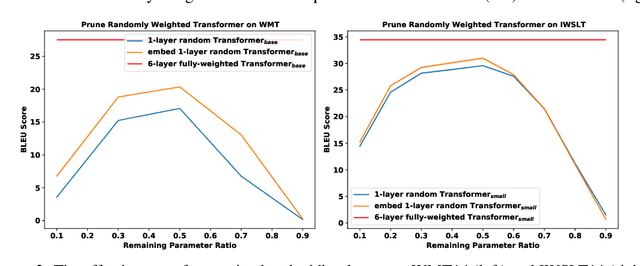
We demonstrate that, hidden within one-layer randomly weighted neural networks, there exist subnetworks that can achieve impressive performance, without ever modifying the weight initializations, on machine translation tasks. To find subnetworks for one-layer randomly weighted neural networks, we apply different binary masks to the same weight matrix to generate different layers. Hidden within a one-layer randomly weighted Transformer, we find that subnetworks that can achieve 29.45/17.29 BLEU on IWSLT14/WMT14. Using a fixed pre-trained embedding layer, the previously found subnetworks are smaller than, but can match 98%/92% (34.14/25.24 BLEU) of the performance of, a trained Transformer small/base on IWSLT14/WMT14. Furthermore, we demonstrate the effectiveness of larger and deeper transformers in this setting, as well as the impact of different initialization methods. We released the source code at https://github.com/sIncerass/one_layer_lottery_ticket.
Emotion Recognition from Multiple Modalities: Fundamentals and Methodologies
Aug 18, 2021
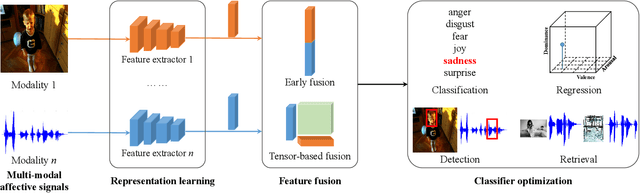
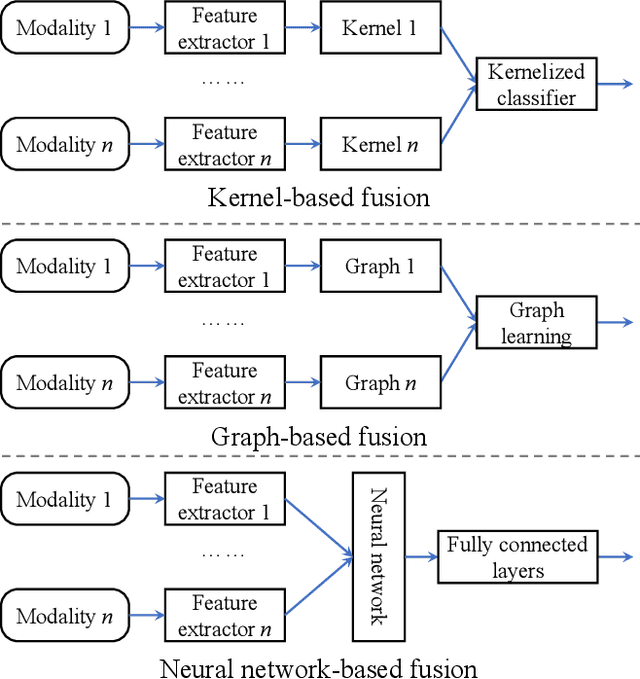
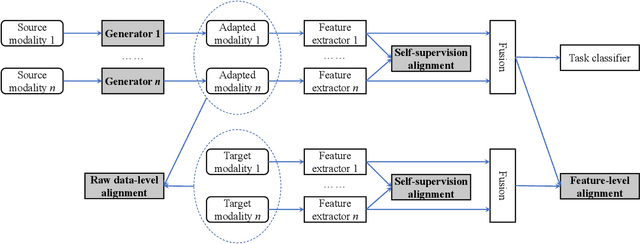
Humans are emotional creatures. Multiple modalities are often involved when we express emotions, whether we do so explicitly (e.g., facial expression, speech) or implicitly (e.g., text, image). Enabling machines to have emotional intelligence, i.e., recognizing, interpreting, processing, and simulating emotions, is becoming increasingly important. In this tutorial, we discuss several key aspects of multi-modal emotion recognition (MER). We begin with a brief introduction on widely used emotion representation models and affective modalities. We then summarize existing emotion annotation strategies and corresponding computational tasks, followed by the description of main challenges in MER. Furthermore, we present some representative approaches on representation learning of each affective modality, feature fusion of different affective modalities, classifier optimization for MER, and domain adaptation for MER. Finally, we outline several real-world applications and discuss some future directions.