 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Differentiable NAS Framework and Application to Ads CTR Prediction
Oct 25, 2021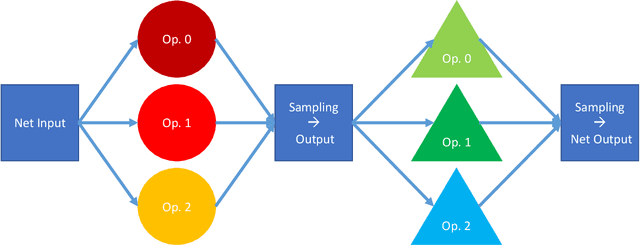
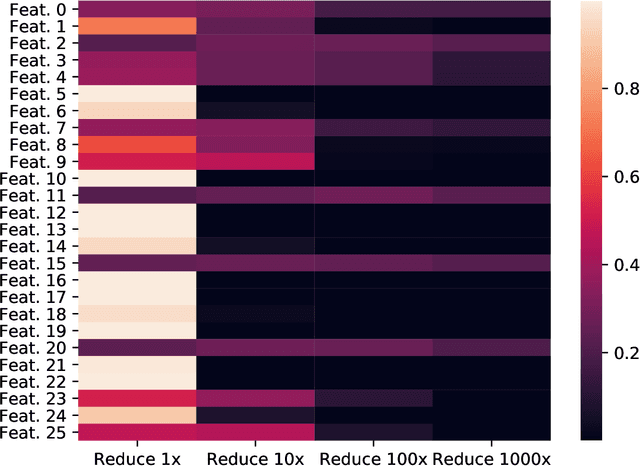
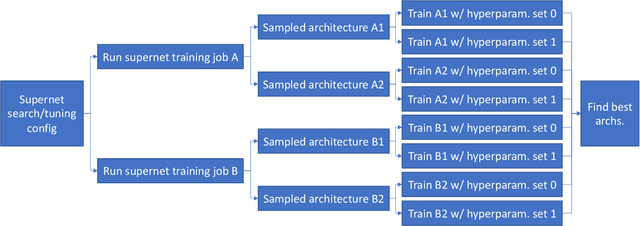
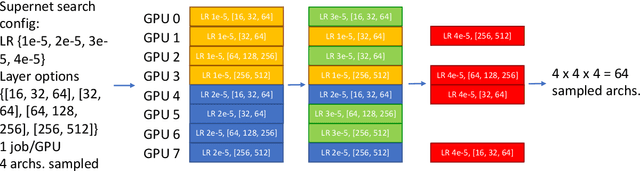
Neural architecture search (NAS) methods aim to automatically find the optimal deep neural network (DNN) architecture as measured by a given objective function, typically some combination of task accuracy and inference efficiency. For many areas, such as computer vision and natural language processing, this is a critical, yet still time consuming process. New NAS methods have recently made progress in improving the efficiency of this process. We implement an extensible and modular framework for Differentiable Neural Architecture Search (DNAS) to help solve this problem. We include an overview of the major components of our codebase and how they interact, as well as a section on implementing extensions to it (including a sample), in order to help users adopt our framework for their applications across different categories of deep learning models. To assess the capabilities of our methodology and implementation, we apply DNAS to the problem of ads click-through rate (CTR) prediction, arguably the highest-value and most worked on AI problem at hyperscalers today. We develop and tailor novel search spaces to a Deep Learning Recommendation Model (DLRM) backbone for CTR prediction, and report state-of-the-art results on the Criteo Kaggle CTR prediction dataset.
Check-N-Run: A Checkpointing System for Training Recommendation Models
Oct 17, 2020
Checkpoints play an important role in training recommendation systems at scale. They are important for many use cases, including failure recovery to ensure rapid training progress, and online training to improve inference prediction accuracy. Checkpoints are typically written to remote, persistent storage. Given the typically large and ever-increasing recommendation model sizes, the checkpoint frequency and effectiveness is often bottlenecked by the storage write bandwidth and capacity, as well as the network bandwidth. We present Check-N-Run, a scalable checkpointing system for training large recommendation models. Check-N-Run uses two primary approaches to address these challenges. First, it applies incremental checkpointing, which tracks and checkpoints the modified part of the model. On top of that, it leverages quantization techniques to significantly reduce the checkpoint size, without degrading training accuracy. These techniques allow Check-N-Run to reduce the required write bandwidth by 6-17x and the required capacity by 2.5-8x on real-world models at Facebook, and thereby significantly improve checkpoint capabilities while reducing the total cost of ownership.
A Study of BFLOAT16 for Deep Learning Training
Jun 13, 2019
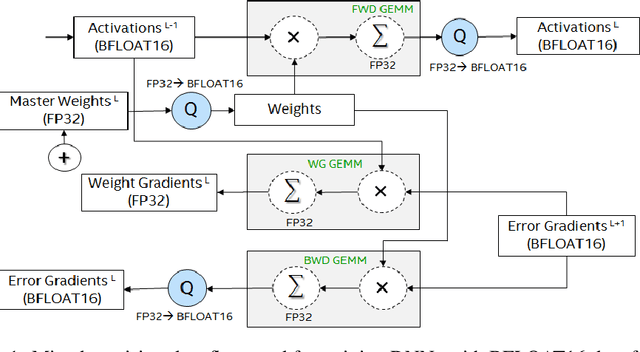
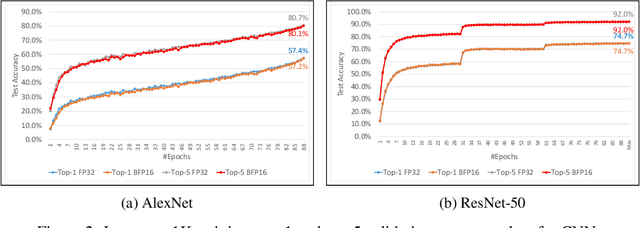

This paper presents the first comprehensive empirical study demonstrating the efficacy of the Brain Floating Point (BFLOAT16) half-precision format for Deep Learning training across image classification, speech recognition, language modeling, generative networks and industrial recommendation systems. BFLOAT16 is attractive for Deep Learning training for two reasons: the range of values it can represent is the same as that of IEEE 754 floating-point format (FP32) and conversion to/from FP32 is simple. Maintaining the same range as FP32 is important to ensure that no hyper-parameter tuning is required for convergence; e.g., IEEE 754 compliant half-precision floating point (FP16) requires hyper-parameter tuning. In this paper, we discuss the flow of tensors and various key operations in mixed precision training, and delve into details of operations, such as the rounding modes for converting FP32 tensors to BFLOAT16. We have implemented a method to emulate BFLOAT16 operations in Tensorflow, Caffe2, IntelCaffe, and Neon for our experiments. Our results show that deep learning training using BFLOAT16 tensors achieves the same state-of-the-art (SOTA) results across domains as FP32 tensors in the same number of iterations and with no changes to hyper-parameters.
Deep Learning Recommendation Model for Personalization and Recommendation Systems
May 31, 2019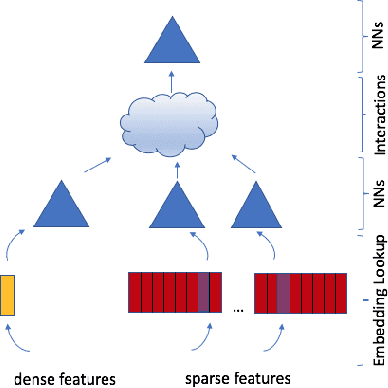

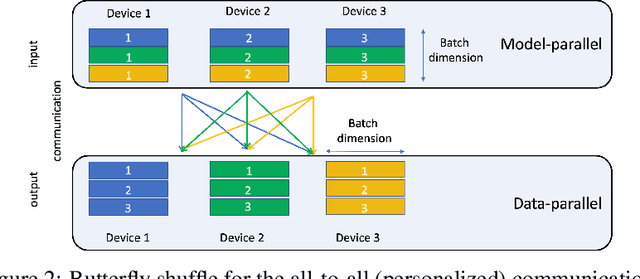
With the advent of deep learning, neural network-based recommendation models have emerged as an important tool for tackling personalization and recommendation tasks. These networks differ significantly from other deep learning networks due to their need to handle categorical features and are not well studied or understood. In this paper, we develop a state-of-the-art deep learning recommendation model (DLRM) and provide its implementation in both PyTorch and Caffe2 frameworks. In addition, we design a specialized parallelization scheme utilizing model parallelism on the embedding tables to mitigate memory constraints while exploiting data parallelism to scale-out compute from the fully-connected layers. We compare DLRM against existing recommendation models and characterize its performance on the Big Basin AI platform, demonstrating its usefulness as a benchmark for future algorithmic experimentation and system co-design.
Bandana: Using Non-volatile Memory for Storing Deep Learning Models
Nov 15, 2018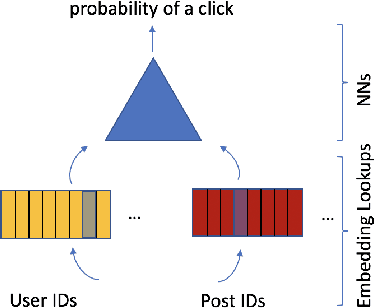
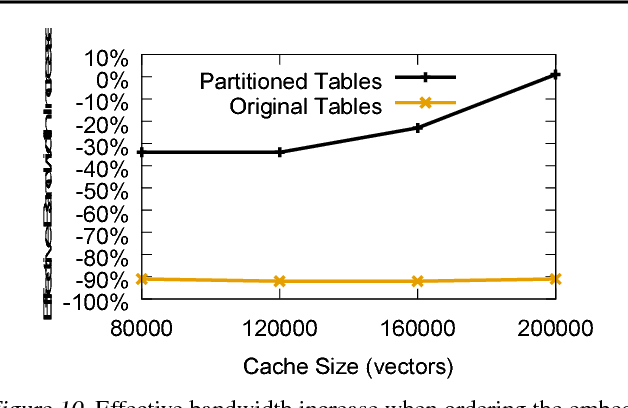
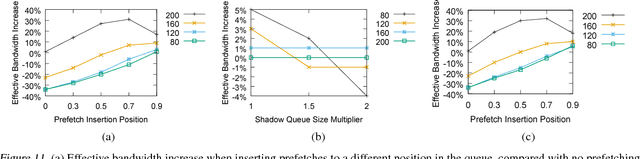
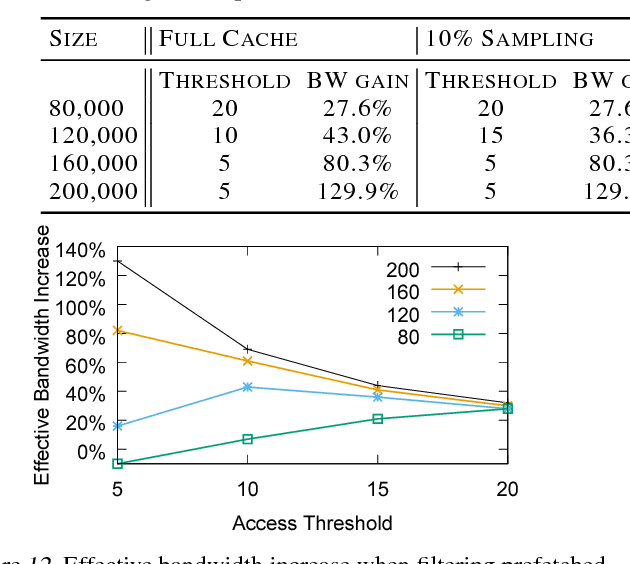
Typical large-scale recommender systems use deep learning models that are stored on a large amount of DRAM. These models often rely on embeddings, which consume most of the required memory. We present Bandana, a storage system that reduces the DRAM footprint of embeddings, by using Non-volatile Memory (NVM) as the primary storage medium, with a small amount of DRAM as cache. The main challenge in storing embeddings on NVM is its limited read bandwidth compared to DRAM. Bandana uses two primary techniques to address this limitation: first, it stores embedding vectors that are likely to be read together in the same physical location, using hypergraph partitioning, and second, it decides the number of embedding vectors to cache in DRAM by simulating dozens of small caches. These techniques allow Bandana to increase the effective read bandwidth of NVM by 2-3x and thereby significantly reduce the total cost of ownership.