 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr-DCI: Scaling Direct Corpus Interaction via Dynamic Workspace Expansion
Jun 12, 2026Agentic search over large corpora relies on retriever-mediated interfaces (e.g., BM25 or ColBERT) for scalable candidate discovery. While effective at ranking relevant documents, these interfaces expose evidence only as ranked results or bounded document views, limiting agents' ability to reorganize material and verify constraints across documents. Direct Corpus Interaction (DCI) addresses this limitation by exposing shell-executable corpus operations for flexible search, filtering, comparison, and verification. However, full-corpus terminal commands become slow and unstable as the corpus grows, degrading performance and efficiency. We introduce DR-DCI, a retriever-steered DCI framework that treats retrieval as an agent-callable action for expanding a local workspace. Rather than operating directly over the full corpus, the agent dynamically pulls relevant documents into an evolving workspace and conducts DCI operations within it. This design combines retriever-level recall with DCI-style precision: retrieval keeps exploration scalable, while DCI preserves the local operations needed for effective evidence resolution. Experiments show that DR-DCI is both effective and efficient across scales. On Browsecomp-Plus, DR-DCI reaches 71.2\% accuracy, improving over raw DCI and ablated variants by up to 8.3 points while reducing tool usage, wall time, and estimated cost. With workspace-preserving context reset, accuracy further improves to 73.3\%. In corpus-scaling experiments, DR-DCI remains effective from 100K to 10M documents, whereas raw DCI becomes unstable and BM25 performs substantially worse. DR-DCI also scales to a 20M-scale file-per-document Wiki-18 QA setting, achieving an average score of 63.0 across six benchmarks and outperforming retrieval-based and trained search-agent baselines. Ablation analysis further shows that ranked previews and inter-document DCI are key to performance.
Reasoning for Mobile User Experience with Multimodal LLMs: Task, Benchmark, and Approach
Jun 11, 2026User experience (UX) centered on usability, perceived consistency, and functional clarity is fundamental to real-world user interfaces (UI). The application of multimodal large language models (MLLMs) in the field of user interfaces is evolving rapidly, such as visual element grounding, graphical user interface (GUI) agents, and design-to-code generation. However, research efforts on evaluating UX based on UI screenshots are still immature. To address this, we propose UXBench, a novel multimodal benchmark consisting of 2,000 VQA data samples designed to assess MLLMs' ability to perform UI-based reasoning. UXBench includes 8 tasks based on real-world UI screenshots that require fine-grained diagnosis of UX issues across layout relationships, visual hierarchy, and content consistency. Our extensive evaluation of mainstream MLLMs shows that they remain fundamentally limited in their capacity for UI-based reasoning. The results underscore the need for further advancements in this area. To bridge this gap, we propose UI-UX, an MLLM based on Qwen3-VL-4B-Thinking foundation model and enhanced via reinforcement learning with two key innovations: a reward routing mechanism that dynamically balances perceptual understanding and logical reasoning during inference, and an asymmetric transition reward that suppresses redundant or insufficient reasoning steps. Experiments demonstrate that UI-UX achieves state-of-the-art (SOTA) performance on UXBench, attaining an accuracy of 0.7963 -- surpassing Claude-4.5-Sonnet's 0.6550 -- while exhibiting strong generalization across diverse UI tasks and maintaining low inference latency.
SWE-QA-Pro: A Representative Benchmark and Scalable Training Recipe for Repository-Level Code Understanding
Mar 17, 2026Agentic repository-level code understanding is essential for automating complex software engineering tasks, yet the field lacks reliable benchmarks. Existing evaluations often overlook the long tail topics and rely on popular repositories where Large Language Models (LLMs) can cheat via memorized knowledge. To address this, we introduce SWE-QA-Pro, a benchmark constructed from diverse, long-tail repositories with executable environments. We enforce topical balance via issue-driven clustering to cover under-represented task types and apply a rigorous difficulty calibration process: questions solvable by direct-answer baselines are filtered out. This results in a dataset where agentic workflows significantly outperform direct answering (e.g., a ~13-point gap for Claude Sonnet 4.5), confirming the necessity of agentic codebase exploration. Furthermore, to tackle the scarcity of training data for such complex behaviors, we propose a scalable synthetic data pipeline that powers a two-stage training recipe: Supervised Fine-Tuning (SFT) followed by Reinforcement Learning from AI Feedback (RLAIF). This approach allows small open models to learn efficient tool usage and reasoning. Empirically, a Qwen3-8B model trained with our recipe surpasses GPT-4o by 2.3 points on SWE-QA-Pro and substantially narrows the gap to state-of-the-art proprietary models, demonstrating both the validity of our evaluation and the effectiveness of our agentic training workflow.
Beyond Single-shot Writing: Deep Research Agents are Unreliable at Multi-turn Report Revision
Jan 19, 2026Existing benchmarks for Deep Research Agents (DRAs) treat report generation as a single-shot writing task, which fundamentally diverges from how human researchers iteratively draft and revise reports via self-reflection or peer feedback. Whether DRAs can reliably revise reports with user feedback remains unexplored. We introduce Mr Dre, an evaluation suite that establishes multi-turn report revision as a new evaluation axis for DRAs. Mr Dre consists of (1) a unified long-form report evaluation protocol spanning comprehensiveness, factuality, and presentation, and (2) a human-verified feedback simulation pipeline for multi-turn revision. Our analysis of five diverse DRAs reveals a critical limitation: while agents can address most user feedback, they also regress on 16-27% of previously covered content and citation quality. Over multiple revision turns, even the best-performing agents leave significant headroom, as they continue to disrupt content outside the feedback's scope and fail to preserve earlier edits. We further show that these issues are not easily resolvable through inference-time fixes such as prompt engineering and a dedicated sub-agent for report revision.
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Apr 03, 2025The task of issue resolving is to modify a codebase to generate a patch that addresses a given issue. However, existing benchmarks, such as SWE-bench, focus almost exclusively on Python, making them insufficient for evaluating Large Language Models (LLMs) across diverse software ecosystems. To address this, we introduce a multilingual issue-resolving benchmark, called Multi-SWE-bench, covering Java, TypeScript, JavaScript, Go, Rust, C, and C++. It includes a total of 1,632 high-quality instances, which were carefully annotated from 2,456 candidates by 68 expert annotators, ensuring that the benchmark can provide an accurate and reliable evaluation. Based on Multi-SWE-bench, we evaluate a series of state-of-the-art models using three representative methods (Agentless, SWE-agent, and OpenHands) and present a comprehensive analysis with key empirical insights. In addition, we launch a Multi-SWE-RL open-source community, aimed at building large-scale reinforcement learning (RL) training datasets for issue-resolving tasks. As an initial contribution, we release a set of 4,723 well-structured instances spanning seven programming languages, laying a solid foundation for RL research in this domain. More importantly, we open-source our entire data production pipeline, along with detailed tutorials, encouraging the open-source community to continuously contribute and expand the dataset. We envision our Multi-SWE-bench and the ever-growing Multi-SWE-RL community as catalysts for advancing RL toward its full potential, bringing us one step closer to the dawn of AGI.
ICE-GRT: Instruction Context Enhancement by Generative Reinforcement based Transformers
Jan 04, 2024The emergence of Large Language Models (LLMs) such as ChatGPT and LLaMA encounter limitations in domain-specific tasks, with these models often lacking depth and accuracy in specialized areas, and exhibiting a decrease in general capabilities when fine-tuned, particularly analysis ability in small sized models. To address these gaps, we introduce ICE-GRT, utilizing Reinforcement Learning from Human Feedback (RLHF) grounded in Proximal Policy Optimization (PPO), demonstrating remarkable ability in in-domain scenarios without compromising general task performance. Our exploration of ICE-GRT highlights its understanding and reasoning ability to not only generate robust answers but also to provide detailed analyses of the reasons behind the answer. This capability marks a significant progression beyond the scope of Supervised Fine-Tuning models. The success of ICE-GRT is dependent on several crucial factors, including Appropriate Data, Reward Size Scaling, KL-Control, Advantage Normalization, etc. The ICE-GRT model exhibits state-of-the-art performance in domain-specific tasks and across 12 general Language tasks against equivalent size and even larger size LLMs, highlighting the effectiveness of our approach. We provide a comprehensive analysis of the ICE-GRT, underscoring the significant advancements it brings to the field of LLM.
GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond
Oct 10, 2023With the rapid advancement of large language models (LLMs), there is a pressing need for a comprehensive evaluation suite to assess their capabilities and limitations. Existing LLM leaderboards often reference scores reported in other papers without consistent settings and prompts, which may inadvertently encourage cherry-picking favored settings and prompts for better results. In this work, we introduce GPT-Fathom, an open-source and reproducible LLM evaluation suite built on top of OpenAI Evals. We systematically evaluate 10+ leading LLMs as well as OpenAI's legacy models on 20+ curated benchmarks across 7 capability categories, all under aligned settings. Our retrospective study on OpenAI's earlier models offers valuable insights into the evolutionary path from GPT-3 to GPT-4. Currently, the community is eager to know how GPT-3 progressively improves to GPT-4, including technical details like whether adding code data improves LLM's reasoning capability, which aspects of LLM capability can be improved by SFT and RLHF, how much is the alignment tax, etc. Our analysis sheds light on many of these questions, aiming to improve the transparency of advanced LLMs.
GNN is a Counter? Revisiting GNN for Question Answering
Oct 07, 2021

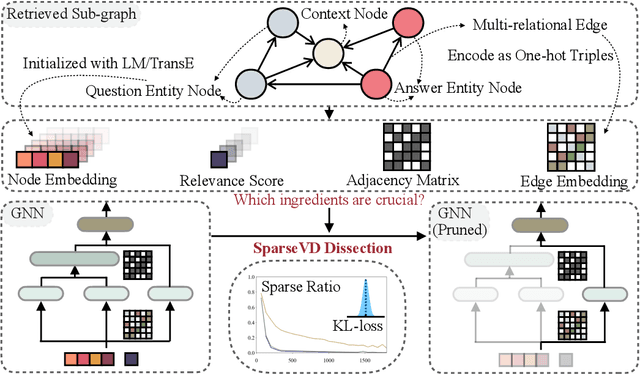
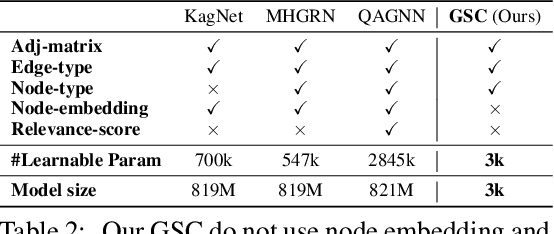
Question Answering (QA) has been a long-standing research topic in AI and NLP fields, and a wealth of studies have been conducted to attempt to equip QA systems with human-level reasoning capability. To approximate the complicated human reasoning process, state-of-the-art QA systems commonly use pre-trained language models (LMs) to access knowledge encoded in LMs together with elaborately designed modules based on Graph Neural Networks (GNNs) to perform reasoning over knowledge graphs (KGs). However, many problems remain open regarding the reasoning functionality of these GNN-based modules. Can these GNN-based modules really perform a complex reasoning process? Are they under- or over-complicated for QA? To open the black box of GNN and investigate these problems, we dissect state-of-the-art GNN modules for QA and analyze their reasoning capability. We discover that even a very simple graph neural counter can outperform all the existing GNN modules on CommonsenseQA and OpenBookQA, two popular QA benchmark datasets which heavily rely on knowledge-aware reasoning. Our work reveals that existing knowledge-aware GNN modules may only carry out some simple reasoning such as counting. It remains a challenging open problem to build comprehensive reasoning modules for knowledge-powered QA.
Speeding up Computational Morphogenesis with Online Neural Synthetic Gradients
Apr 27, 2021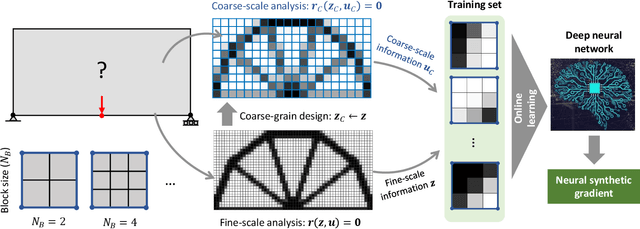
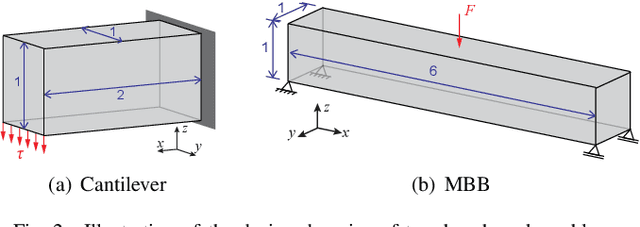
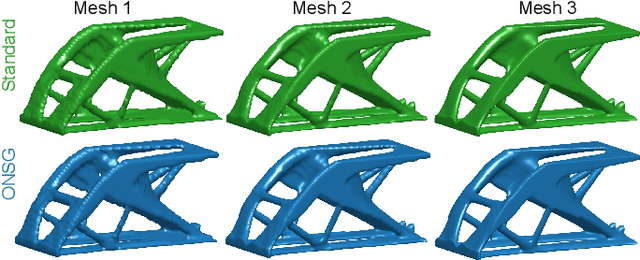
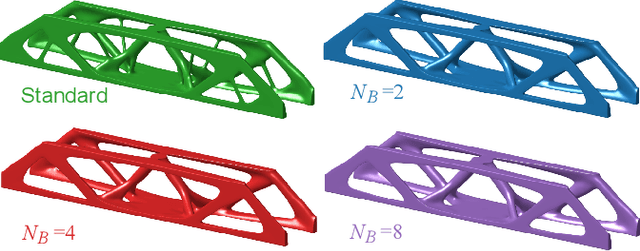
A wide range of modern science and engineering applications are formulated as optimization problems with a system of partial differential equations (PDEs) as constraints. These PDE-constrained optimization problems are typically solved in a standard discretize-then-optimize approach. In many industry applications that require high-resolution solutions, the discretized constraints can easily have millions or even billions of variables, making it very slow for the standard iterative optimizer to solve the exact gradients. In this work, we propose a general framework to speed up PDE-constrained optimization using online neural synthetic gradients (ONSG) with a novel two-scale optimization scheme. We successfully apply our ONSG framework to computational morphogenesis, a representative and challenging class of PDE-constrained optimization problems. Extensive experiments have demonstrated that our method can significantly speed up computational morphogenesis (also known as topology optimization), and meanwhile maintain the quality of final solution compared to the standard optimizer. On a large-scale 3D optimal design problem with around 1,400,000 design variables, our method achieves up to 7.5x speedup while producing optimized designs with comparable objectives.
DDRQA: Dynamic Document Reranking for Open-domain Multi-hop Question Answering
Sep 16, 2020
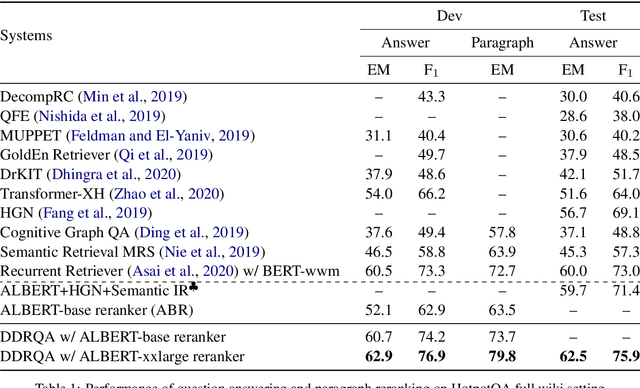
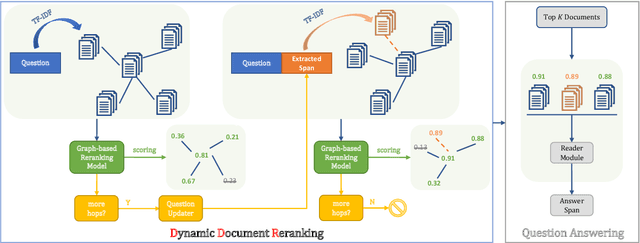
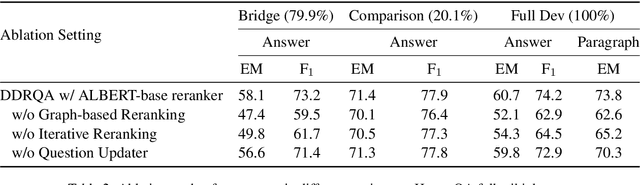
Open-domain multi-hop question answering (QA) requires to retrieve multiple supporting documents, some of which have little lexical overlap with the question and can only be located by iterative document retrieval. However, multi-step document retrieval often incurs more relevant but non-supporting documents, which dampens the downstream noise-sensitive reader module for answer extraction. To address this challenge, we propose Dynamic Document Reranking (DDR) to iteratively retrieve, rerank and filter documents, and adaptively determine when to stop the retrieval process. DDR employs an entity-linked document graph for multi-document interaction, which boosts up the retrieval performance. Experiments on HotpotQA full wiki setting show that our method achieves more than 7 points higher reranking performance over the previous best retrieval model, and also achieves state-of-the-art question answering performance on the official leaderboard.