 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoose What to Observe: Task-Aware Semantic-Geometric Representations for Visuomotor Policy
Mar 09, 2026Visuomotor policies learned from demonstrations often overfit to nuisance visual factors in raw RGB observations, resulting in brittle behavior under appearance shifts such as background changes and object recoloring. We propose a task-aware observation interface that canonicalizes visual input into a shared representation, improving robustness to out-of-distribution (OOD) appearance changes without modifying or fine-tuning the policy. Given an RGB image and an open-vocabulary specification of task-relevant entities, we use SAM3 to segment the target object and robot/gripper. We construct an L0 observation by repainting segmented entities with predefined semantic colors on a constant background. For tasks requiring stronger geometric cues, we further inject monocular depth from Depth Anything 3 into the segmented regions via depth-guided overwrite, yielding a unified semantic--geometric observation (L1) that remains a standard 3-channel, image-like input. We evaluate on RoboMimic (Lift), ManiSkill YCB grasping under clutter, four RLBench tasks under controlled appearance shifts, and two real-world Franka tasks (ReachX and CloseCabinet). Across benchmarks and policy backbones (Flow Matching Policy and SmolVLA), our interface preserves in-distribution performance while substantially improving robustness under OOD visual shifts.
UNCLE-Grasp: Uncertainty-Aware Grasping of Leaf-Occluded Strawberries
Jan 20, 2026Robotic strawberry harvesting is challenging under partial occlusion, where leaves induce significant geometric uncertainty and make grasp decisions based on a single deterministic shape estimate unreliable. From a single partial observation, multiple incompatible 3D completions may be plausible, causing grasps that appear feasible on one completion to fail on another. We propose an uncertainty-aware grasping pipeline for partially occluded strawberries that explicitly models completion uncertainty arising from both occlusion and learned shape reconstruction. Our approach uses point cloud completion with Monte Carlo dropout to sample multiple shape hypotheses, generates candidate grasps for each completion, and evaluates grasp feasibility using physically grounded force-closure-based metrics. Rather than selecting a grasp based on a single estimate, we aggregate feasibility across completions and apply a conservative lower confidence bound (LCB) criterion to decide whether a grasp should be attempted or safely abstained. We evaluate the proposed method in simulation and on a physical robot across increasing levels of synthetic and real leaf occlusion. Results show that uncertainty-aware decision making enables reliable abstention from high-risk grasp attempts under severe occlusion while maintaining robust grasp execution when geometric confidence is sufficient, outperforming deterministic baselines in both simulated and physical robot experiments.
LAVQA: A Latency-Aware Visual Question Answering Framework for Shared Autonomy in Self-Driving Vehicles
Nov 14, 2025When uncertainty is high, self-driving vehicles may halt for safety and benefit from the access to remote human operators who can provide high-level guidance. This paradigm, known as {shared autonomy}, enables autonomous vehicle and remote human operators to jointly formulate appropriate responses. To address critical decision timing with variable latency due to wireless network delays and human response time, we present LAVQA, a latency-aware shared autonomy framework that integrates Visual Question Answering (VQA) and spatiotemporal risk visualization. LAVQA augments visual queries with Latency-Induced COllision Map (LICOM), a dynamically evolving map that represents both temporal latency and spatial uncertainty. It enables remote operator to observe as the vehicle safety regions vary over time in the presence of dynamic obstacles and delayed responses. Closed-loop simulations in CARLA, the de-facto standard for autonomous vehicle simulator, suggest that that LAVQA can reduce collision rates by over 8x compared to latency-agnostic baselines.
Orientation Learning and Adaptation towards Simultaneous Incorporation of Multiple Local Constraints
Oct 09, 2025Orientation learning plays a pivotal role in many tasks. However, the rotation group SO(3) is a Riemannian manifold. As a result, the distortion caused by non-Euclidean geometric nature introduces difficulties to the incorporation of local constraints, especially for the simultaneous incorporation of multiple local constraints. To address this issue, we propose the Angle-Axis Space-based orientation representation method to solve several orientation learning problems, including orientation adaptation and minimization of angular acceleration. Specifically, we propose a weighted average mechanism in SO(3) based on the angle-axis representation method. Our main idea is to generate multiple trajectories by considering different local constraints at different basepoints. Then these multiple trajectories are fused to generate a smooth trajectory by our proposed weighted average mechanism, achieving the goal to incorporate multiple local constraints simultaneously. Compared with existing solution, ours can address the distortion issue and make the off-theshelf Euclidean learning algorithm be re-applicable in non-Euclidean space. Simulation and Experimental evaluations validate that our solution can not only adapt orientations towards arbitrary desired via-points and cope with angular acceleration constraints, but also incorporate multiple local constraints simultaneously to achieve extra benefits, e.g., achieving smaller acceleration costs.
Imagination at Inference: Synthesizing In-Hand Views for Robust Visuomotor Policy Inference
Sep 19, 2025Visual observations from different viewpoints can significantly influence the performance of visuomotor policies in robotic manipulation. Among these, egocentric (in-hand) views often provide crucial information for precise control. However, in some applications, equipping robots with dedicated in-hand cameras may pose challenges due to hardware constraints, system complexity, and cost. In this work, we propose to endow robots with imaginative perception - enabling them to 'imagine' in-hand observations from agent views at inference time. We achieve this via novel view synthesis (NVS), leveraging a fine-tuned diffusion model conditioned on the relative pose between the agent and in-hand views cameras. Specifically, we apply LoRA-based fine-tuning to adapt a pretrained NVS model (ZeroNVS) to the robotic manipulation domain. We evaluate our approach on both simulation benchmarks (RoboMimic and MimicGen) and real-world experiments using a Unitree Z1 robotic arm for a strawberry picking task. Results show that synthesized in-hand views significantly enhance policy inference, effectively recovering the performance drop caused by the absence of real in-hand cameras. Our method offers a scalable and hardware-light solution for deploying robust visuomotor policies, highlighting the potential of imaginative visual reasoning in embodied agents.
GeoAware-VLA: Implicit Geometry Aware Vision-Language-Action Model
Sep 17, 2025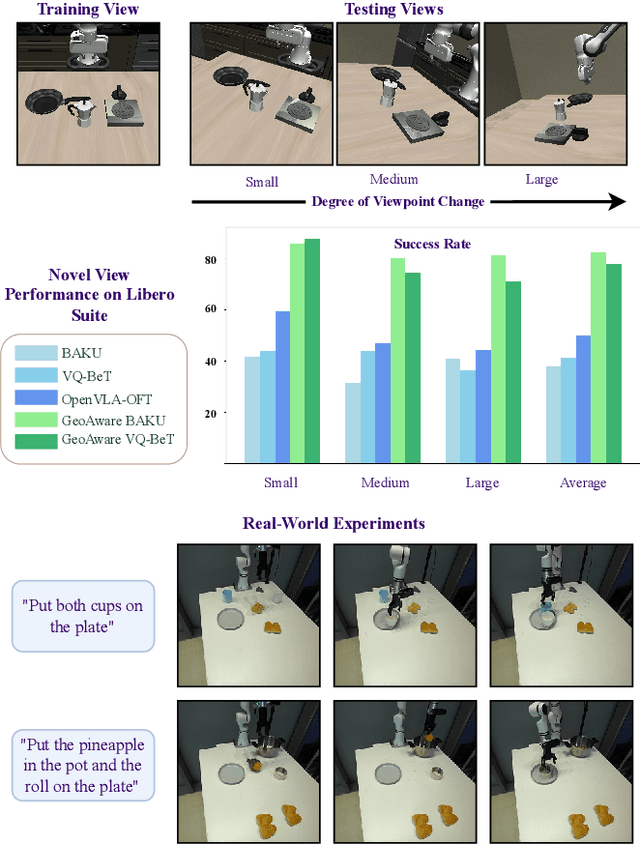
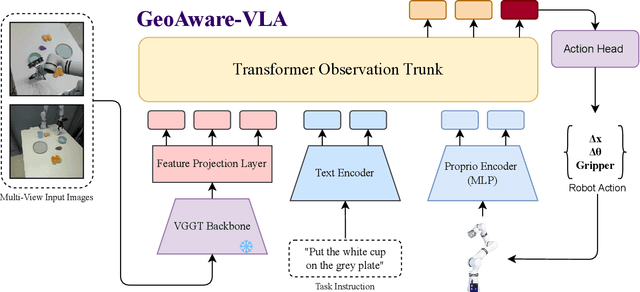
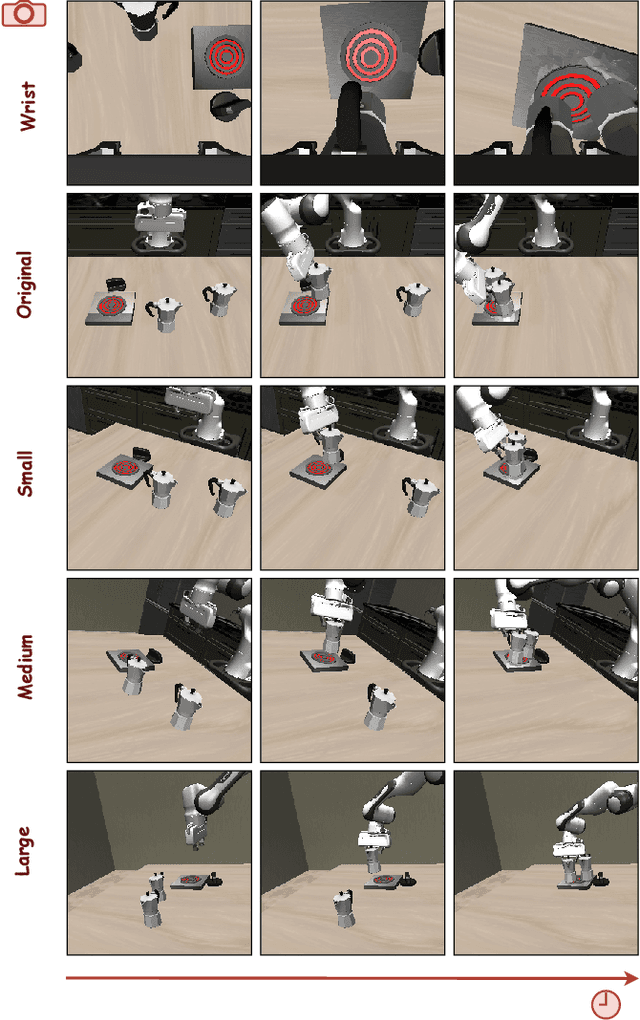

Vision-Language-Action (VLA) models often fail to generalize to novel camera viewpoints, a limitation stemming from their difficulty in inferring robust 3D geometry from 2D images. We introduce GeoAware-VLA, a simple yet effective approach that enhances viewpoint invariance by integrating strong geometric priors into the vision backbone. Instead of training a visual encoder or relying on explicit 3D data, we leverage a frozen, pretrained geometric vision model as a feature extractor. A trainable projection layer then adapts these geometrically-rich features for the policy decoder, relieving it of the burden of learning 3D consistency from scratch. Through extensive evaluations on LIBERO benchmark subsets, we show GeoAware-VLA achieves substantial improvements in zero-shot generalization to novel camera poses, boosting success rates by over 2x in simulation. Crucially, these benefits translate to the physical world; our model shows a significant performance gain on a real robot, especially when evaluated from unseen camera angles. Our approach proves effective across both continuous and discrete action spaces, highlighting that robust geometric grounding is a key component for creating more generalizable robotic agents.
A Hybrid Hinge-Beam Continuum Robot with Passive Safety Capping for Real-Time Fatigue Awareness
Sep 11, 2025Cable-driven continuum robots offer high flexibility and lightweight design, making them well-suited for tasks in constrained and unstructured environments. However, prolonged use can induce mechanical fatigue from plastic deformation and material degradation, compromising performance and risking structural failure. In the state of the art, fatigue estimation of continuum robots remains underexplored, limiting long-term operation. To address this, we propose a fatigue-aware continuum robot with three key innovations: (1) a Hybrid Hinge-Beam structure where TwistBeam and BendBeam decouple torsion and bending: passive revolute joints in the BendBeam mitigate stress concentration, while TwistBeam's limited torsional deformation reduces BendBeam stress magnitude, enhancing durability; (2) a Passive Stopper that safely constrains motion via mechanical constraints and employs motor torque sensing to detect corresponding limit torque, ensuring safety and enabling data collection; and (3) a real-time fatigue-awareness method that estimates stiffness from motor torque at the limit pose, enabling online fatigue estimation without additional sensors. Experiments show that the proposed design reduces fatigue accumulation by about 49% compared with a conventional design, while passive mechanical limiting combined with motor-side sensing allows accurate estimation of structural fatigue and damage. These results confirm the effectiveness of the proposed architecture for safe and reliable long-term operation.
Super LiDAR Reflectance for Robotic Perception
Aug 14, 2025Conventionally, human intuition often defines vision as a modality of passive optical sensing, while active optical sensing is typically regarded as measuring rather than the default modality of vision. However, the situation now changes: sensor technologies and data-driven paradigms empower active optical sensing to redefine the boundaries of vision, ushering in a new era of active vision. Light Detection and Ranging (LiDAR) sensors capture reflectance from object surfaces, which remains invariant under varying illumination conditions, showcasing significant potential in robotic perception tasks such as detection, recognition, segmentation, and Simultaneous Localization and Mapping (SLAM). These applications often rely on dense sensing capabilities, typically achieved by high-resolution, expensive LiDAR sensors. A key challenge with low-cost LiDARs lies in the sparsity of scan data, which limits their broader application. To address this limitation, this work introduces an innovative framework for generating dense LiDAR reflectance images from sparse data, leveraging the unique attributes of non-repeating scanning LiDAR (NRS-LiDAR). We tackle critical challenges, including reflectance calibration and the transition from static to dynamic scene domains, facilitating the reconstruction of dense reflectance images in real-world settings. The key contributions of this work include a comprehensive dataset for LiDAR reflectance image densification, a densification network tailored for NRS-LiDAR, and diverse applications such as loop closure and traffic lane detection using the generated dense reflectance images.
Towards Safe Imitation Learning via Potential Field-Guided Flow Matching
Aug 12, 2025



Deep generative models, particularly diffusion and flow matching models, have recently shown remarkable potential in learning complex policies through imitation learning. However, the safety of generated motions remains overlooked, particularly in complex environments with inherent obstacles. In this work, we address this critical gap by proposing Potential Field-Guided Flow Matching Policy (PF2MP), a novel approach that simultaneously learns task policies and extracts obstacle-related information, represented as a potential field, from the same set of successful demonstrations. During inference, PF2MP modulates the flow matching vector field via the learned potential field, enabling safe motion generation. By leveraging these complementary fields, our approach achieves improved safety without compromising task success across diverse environments, such as navigation tasks and robotic manipulation scenarios. We evaluate PF2MP in both simulation and real-world settings, demonstrating its effectiveness in task space and joint space control. Experimental results demonstrate that PF2MP enhances safety, achieving a significant reduction of collisions compared to baseline policies. This work paves the way for safer motion generation in unstructured and obstaclerich environments.
SmallPlan: Leverage Small Language Models for Sequential Path Planning with Simulation-Powered, LLM-Guided Distillation
May 01, 2025Efficient path planning in robotics, particularly within large-scale, dynamic environments, remains a significant hurdle. While Large Language Models (LLMs) offer strong reasoning capabilities, their high computational cost and limited adaptability in dynamic scenarios hinder real-time deployment on edge devices. We present SmallPlan -- a novel framework leveraging LLMs as teacher models to train lightweight Small Language Models (SLMs) for high-level path planning tasks. In SmallPlan, the SLMs provide optimal action sequences to navigate across scene graphs that compactly represent full-scaled 3D scenes. The SLMs are trained in a simulation-powered, interleaved manner with LLM-guided supervised fine-tuning (SFT) and reinforcement learning (RL). This strategy not only enables SLMs to successfully complete navigation tasks but also makes them aware of important factors like travel distance and number of trials. Through experiments, we demonstrate that the fine-tuned SLMs perform competitively with larger models like GPT-4o on sequential path planning, without suffering from hallucination and overfitting. SmallPlan is resource-efficient, making it well-suited for edge-device deployment and advancing practical autonomous robotics.