 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAPO: Self-Adaptive Process Optimization Makes Small Reasoners Stronger
Jan 28, 2026Existing self-evolution methods overlook the influence of fine-grained reasoning steps, which leads to the reasoner-verifier gap. The computational inefficiency of Monte Carlo (MC) process supervision further exacerbates the difficulty in mitigating the gap. Motivated by the Error-Related Negativity (ERN), which the reasoner can localize error following incorrect decisions, guiding rapid adjustments, we propose a Self-Adaptive Process Optimization (SAPO) method for self-improvement in Small Language Models (SLMs). SAPO adaptively and efficiently introduces process supervision signals by actively minimizing the reasoner-verifier gap rather than relying on inefficient MC estimations. Extensive experiments demonstrate that the proposed method outperforms most existing self-evolution methods on two challenging task types: mathematics and code. Additionally, to further investigate SAPO's impact on verifier performance, this work introduces two new benchmarks for process reward models in both mathematical and coding tasks.
LLMdoctor: Token-Level Flow-Guided Preference Optimization for Efficient Test-Time Alignment of Large Language Models
Jan 15, 2026Aligning Large Language Models (LLMs) with human preferences is critical, yet traditional fine-tuning methods are computationally expensive and inflexible. While test-time alignment offers a promising alternative, existing approaches often rely on distorted trajectory-level signals or inefficient sampling, fundamentally capping performance and failing to preserve the generative diversity of the base model. This paper introduces LLMdoctor, a novel framework for efficient test-time alignment that operates via a patient-doctor paradigm. It integrates token-level reward acquisition with token-level flow-guided preference optimization (TFPO) to steer a large, frozen patient LLM with a smaller, specialized doctor model. Unlike conventional methods that rely on trajectory-level rewards, LLMdoctor first extracts fine-grained, token-level preference signals from the patient model's behavioral variations. These signals then guide the training of the doctor model via TFPO, which establishes flow consistency across all subtrajectories, enabling precise token-by-token alignment while inherently preserving generation diversity. Extensive experiments demonstrate that LLMdoctor significantly outperforms existing test-time alignment methods and even surpasses the performance of full fine-tuning approaches like DPO.
Sample-aware Adaptive Structured Pruning for Large Language Models
Mar 08, 2025



Large language models (LLMs) have achieved outstanding performance in natural language processing, but enormous model sizes and high computational costs limit their practical deployment. Structured pruning can effectively reduce the resource demands for deployment by removing redundant model parameters. However, the randomly selected calibration data and fixed single importance estimation metrics in existing structured pruning methods lead to degraded performance of pruned models. This study introduces AdaPruner, a sample-aware adaptive structured pruning framework for LLMs, aiming to optimize the calibration data and importance estimation metrics in the structured pruning process. Specifically, AdaPruner effectively removes redundant parameters from LLMs by constructing a structured pruning solution space and then employing Bayesian optimization to adaptively search for the optimal calibration data and importance estimation metrics. Experimental results show that the AdaPruner outperforms existing structured pruning methods on a family of LLMs with varying pruning ratios, demonstrating its applicability and robustness. Remarkably, at a 20\% pruning ratio, the model pruned with AdaPruner maintains 97\% of the performance of the unpruned model.
Data-Free Black-Box Federated Learning via Zeroth-Order Gradient Estimation
Mar 08, 2025



Federated learning (FL) enables decentralized clients to collaboratively train a global model under the orchestration of a central server without exposing their individual data. However, the iterative exchange of model parameters between the server and clients imposes heavy communication burdens, risks potential privacy leakage, and even precludes collaboration among heterogeneous clients. Distillation-based FL tackles these challenges by exchanging low-dimensional model outputs rather than model parameters, yet it highly relies on a task-relevant auxiliary dataset that is often not available in practice. Data-free FL attempts to overcome this limitation by training a server-side generator to directly synthesize task-specific data samples for knowledge transfer. However, the update rule of the generator requires clients to share on-device models for white-box access, which greatly compromises the advantages of distillation-based FL. This motivates us to explore a data-free and black-box FL framework via Zeroth-order Gradient Estimation (FedZGE), which estimates the gradients after flowing through on-device models in a black-box optimization manner to complete the training of the generator in terms of fidelity, transferability, diversity, and equilibrium, without involving any auxiliary data or sharing any model parameters, thus combining the advantages of both distillation-based FL and data-free FL. Experiments on large-scale image classification datasets and network architectures demonstrate the superiority of FedZGE in terms of data heterogeneity, model heterogeneity, communication efficiency, and privacy protection.
Vision-aware Multimodal Prompt Tuning for Uploadable Multi-source Few-shot Domain Adaptation
Mar 08, 2025



Conventional multi-source domain few-shot adaptation (MFDA) faces the challenge of further reducing the load on edge-side devices in low-resource scenarios. Considering the native language-supervised advantage of CLIP and the plug-and-play nature of prompt to transfer CLIP efficiently, this paper introduces an uploadable multi-source few-shot domain adaptation (UMFDA) schema. It belongs to a decentralized edge collaborative learning in the edge-side models that must maintain a low computational load. And only a limited amount of annotations in source domain data is provided, with most of the data being unannotated. Further, this paper proposes a vision-aware multimodal prompt tuning framework (VAMP) under the decentralized schema, where the vision-aware prompt guides the text domain-specific prompt to maintain semantic discriminability and perceive the domain information. The cross-modal semantic and domain distribution alignment losses optimize each edge-side model, while text classifier consistency and semantic diversity losses promote collaborative learning among edge-side models. Extensive experiments were conducted on OfficeHome and DomainNet datasets to demonstrate the effectiveness of the proposed VAMP in the UMFDA, which outperformed the previous prompt tuning methods.
Multi-Attribute Multi-Grained Adaptation of Pre-Trained Language Models for Text Understanding from Bayesian Perspective
Mar 08, 2025



Current neural networks often employ multi-domain-learning or attribute-injecting mechanisms to incorporate non-independent and identically distributed (non-IID) information for text understanding tasks by capturing individual characteristics and the relationships among samples. However, the extent of the impact of non-IID information and how these methods affect pre-trained language models (PLMs) remains unclear. This study revisits the assumption that non-IID information enhances PLMs to achieve performance improvements from a Bayesian perspective, which unearths and integrates non-IID and IID features. Furthermore, we proposed a multi-attribute multi-grained framework for PLM adaptations (M2A), which combines multi-attribute and multi-grained views to mitigate uncertainty in a lightweight manner. We evaluate M2A through prevalent text-understanding datasets and demonstrate its superior performance, mainly when data are implicitly non-IID, and PLMs scale larger.
Learning to Reason via Self-Iterative Process Feedback for Small Language Models
Dec 11, 2024



Small language models (SLMs) are more efficient, cost-effective, and customizable than large language models (LLMs), though they often underperform in specific areas like reasoning. Past methods for enhancing SLMs' reasoning, such as supervised fine-tuning and distillation, often depend on costly external signals, resulting in SLMs being overly confident with limited supervision signals, thus limiting their abilities. Therefore, this study enables SLMs to learn to reason from self-iterative feedback. By combining odds ratio preference optimization (ORPO), we fine-tune and align SLMs using positive and negative signals generated by themselves. Additionally, we introduce process supervision for rewards in preference alignment by sampling-based inference simulation and process reward models. Compared to Supervised Fine-Tuning (SFT), our method improves the performance of Gemma-2B by 12.43 (Acc) on GSM8K and 3.95 (Pass@1) on MBPP. Furthermore, the proposed method also demonstrated superior out-of-domain generalization capabilities on MMLU_Math and HumanEval.
Chinese Metaphor Recognition Using a Multi-stage Prompting Large Language Model
Aug 17, 2024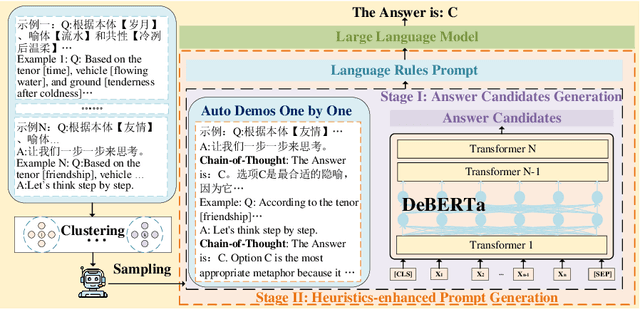

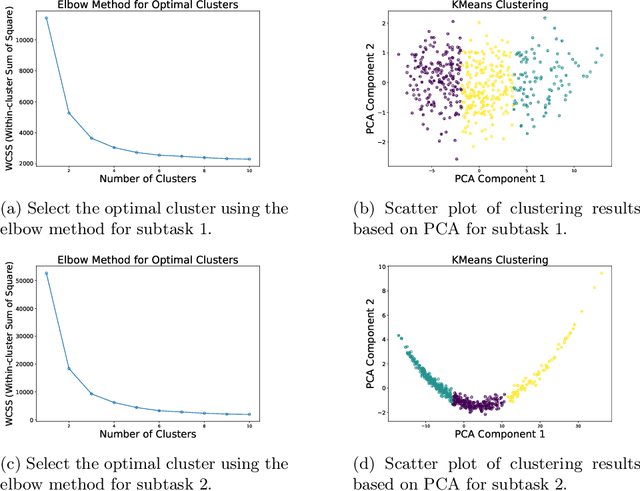
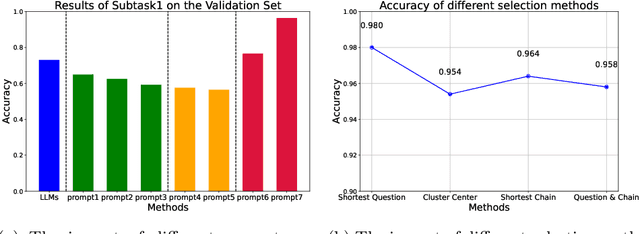
Metaphors are common in everyday language, and the identification and understanding of metaphors are facilitated by models to achieve a better understanding of the text. Metaphors are mainly identified and generated by pre-trained models in existing research, but situations, where tenors or vehicles are not included in the metaphor, cannot be handled. The problem can be effectively solved by using Large Language Models (LLMs), but significant room for exploration remains in this early-stage research area. A multi-stage generative heuristic-enhanced prompt framework is proposed in this study to enhance the ability of LLMs to recognize tenors, vehicles, and grounds in Chinese metaphors. In the first stage, a small model is trained to obtain the required confidence score for answer candidate generation. In the second stage, questions are clustered and sampled according to specific rules. Finally, the heuristic-enhanced prompt needed is formed by combining the generated answer candidates and demonstrations. The proposed model achieved 3rd place in Track 1 of Subtask 1, 1st place in Track 2 of Subtask 1, and 1st place in both tracks of Subtask 2 at the NLPCC-2024 Shared Task 9.
Zero-Shot Cross-Domain Dialogue State Tracking via Dual Low-Rank Adaptation
Jul 31, 2024Zero-shot dialogue state tracking (DST) seeks to enable dialogue systems to transition to unfamiliar domains without manual annotation or extensive retraining. Prior research has approached this objective by embedding prompts into language models (LMs). Common methodologies include integrating prompts at the input layer or introducing learnable variables at each transformer layer. Nonetheless, each strategy exhibits inherent limitations. Prompts integrated at the input layer risk underutilization, with their impact potentially diminishing across successive transformer layers. Conversely, the addition of learnable variables to each layer can complicate the training process and increase inference latency. To tackle the issues mentioned above, this paper proposes Dual Low-Rank Adaptation (DualLoRA), a plug-and-play architecture designed for zero-shot DST. DualLoRA incorporates two distinct Low-Rank Adaptation (LoRA) components, targeting both dialogue context processing and prompt optimization, to ensure the comprehensive influence of prompts throughout the transformer model layers. This is achieved without incurring additional inference latency, showcasing an efficient integration into existing architectures. Through rigorous evaluation on the MultiWOZ and SGD datasets, DualLoRA demonstrates notable improvements across multiple domains, outperforming traditional baseline methods in zero-shot settings. Our code is accessible at: \url{https://github.com/suntea233/DualLoRA}.
Instruction Tuning with Retrieval-based Examples Ranking for Aspect-based Sentiment Analysis
May 29, 2024



Aspect-based sentiment analysis (ABSA) identifies sentiment information related to specific aspects and provides deeper market insights to businesses and organizations. With the emergence of large language models (LMs), recent studies have proposed using fixed examples for instruction tuning to reformulate ABSA as a generation task. However, the performance is sensitive to the selection of in-context examples; several retrieval methods are based on surface similarity and are independent of the LM generative objective. This study proposes an instruction learning method with retrieval-based example ranking for ABSA tasks. For each target sample, an LM was applied as a scorer to estimate the likelihood of the output given the input and a candidate example as the prompt, and training examples were labeled as positive or negative by ranking the scores. An alternating training schema is proposed to train both the retriever and LM. Instructional prompts can be constructed using high-quality examples. The LM is used for both scoring and inference, improving the generation efficiency without incurring additional computational costs or training difficulties. Extensive experiments on three ABSA subtasks verified the effectiveness of the proposed method, demonstrating its superiority over various strong baseline models. Code and data are released at https://github.com/zgMin/IT-RER-ABSA.