 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIMO: Gaze-Informed Human Motion Prediction in Context
Apr 20, 2022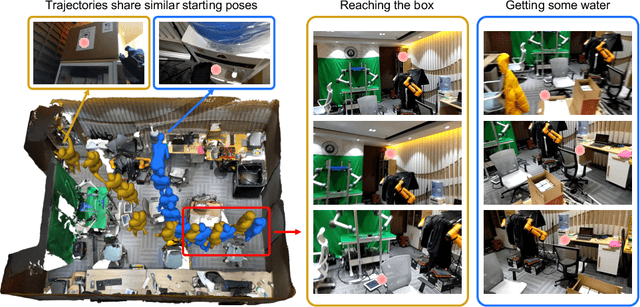
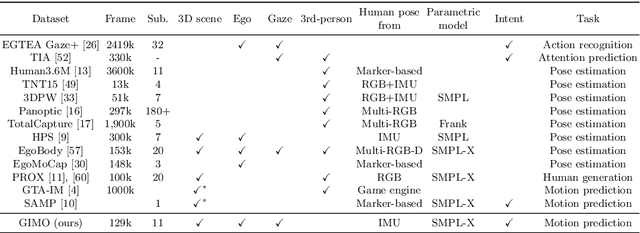
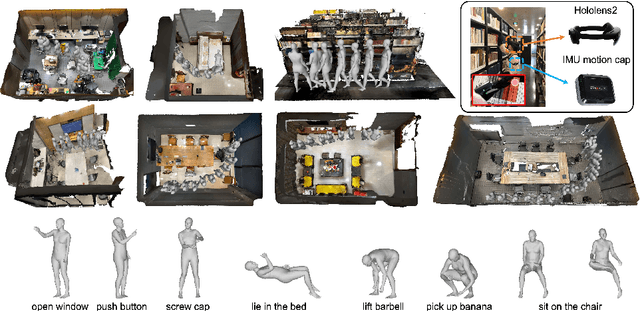
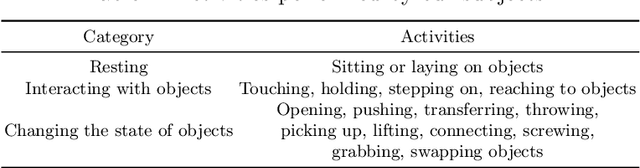
Predicting human motion is critical for assistive robots and AR/VR applications, where the interaction with humans needs to be safe and comfortable. Meanwhile, an accurate prediction depends on understanding both the scene context and human intentions. Even though many works study scene-aware human motion prediction, the latter is largely underexplored due to the lack of ego-centric views that disclose human intent and the limited diversity in motion and scenes. To reduce the gap, we propose a large-scale human motion dataset that delivers high-quality body pose sequences, scene scans, as well as ego-centric views with eye gaze that serves as a surrogate for inferring human intent. By employing inertial sensors for motion capture, our data collection is not tied to specific scenes, which further boosts the motion dynamics observed from our subjects. We perform an extensive study of the benefits of leveraging eye gaze for ego-centric human motion prediction with various state-of-the-art architectures. Moreover, to realize the full potential of gaze, we propose a novel network architecture that enables bidirectional communication between the gaze and motion branches. Our network achieves the top performance in human motion prediction on the proposed dataset, thanks to the intent information from the gaze and the denoised gaze feature modulated by the motion. The proposed dataset and our network implementation will be publicly available.
RoboAssembly: Learning Generalizable Furniture Assembly Policy in a Novel Multi-robot Contact-rich Simulation Environment
Dec 19, 2021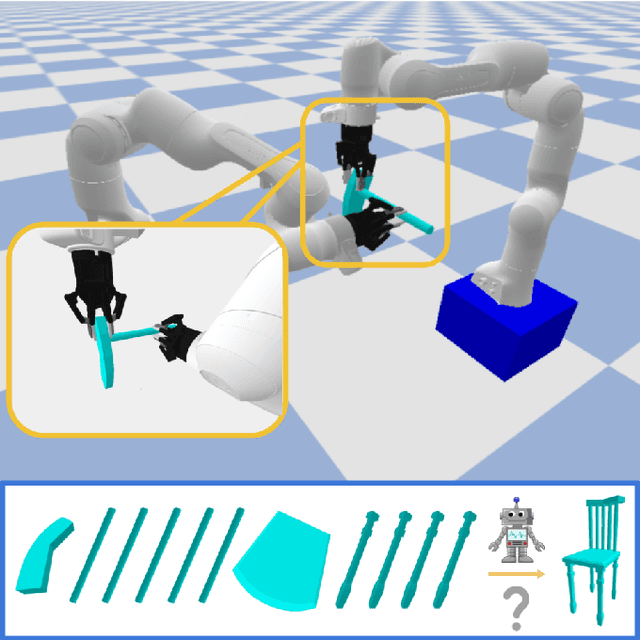
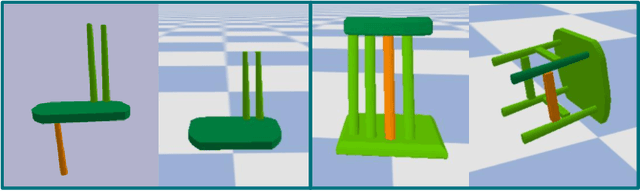
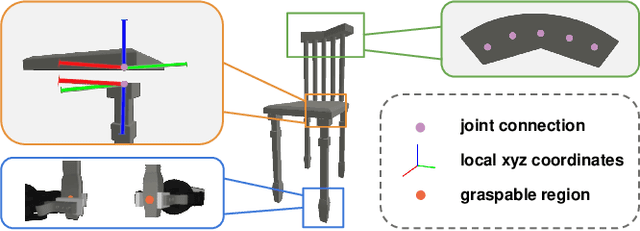
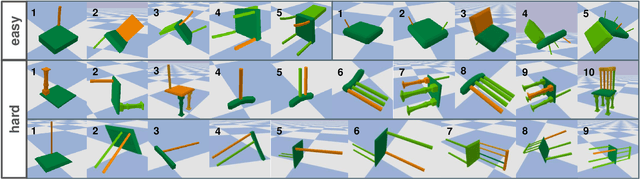
Part assembly is a typical but challenging task in robotics, where robots assemble a set of individual parts into a complete shape. In this paper, we develop a robotic assembly simulation environment for furniture assembly. We formulate the part assembly task as a concrete reinforcement learning problem and propose a pipeline for robots to learn to assemble a diverse set of chairs. Experiments show that when testing with unseen chairs, our approach achieves a success rate of 74.5% under the object-centric setting and 50.0% under the full setting. We adopt an RRT-Connect algorithm as the baseline, which only achieves a success rate of 18.8% after a significantly longer computation time. Supplemental materials and videos are available on our project webpage.
Object Pursuit: Building a Space of Objects via Discriminative Weight Generation
Dec 18, 2021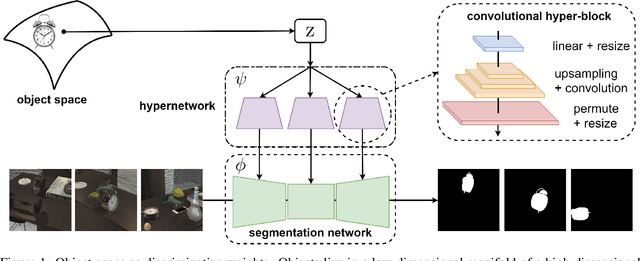



We propose a framework to continuously learn object-centric representations for visual learning and understanding. Existing object-centric representations either rely on supervisions that individualize objects in the scene, or perform unsupervised disentanglement that can hardly deal with complex scenes in the real world. To mitigate the annotation burden and relax the constraints on the statistical complexity of the data, our method leverages interactions to effectively sample diverse variations of an object and the corresponding training signals while learning the object-centric representations. Throughout learning, objects are streamed one by one in random order with unknown identities, and are associated with latent codes that can synthesize discriminative weights for each object through a convolutional hypernetwork. Moreover, re-identification of learned objects and forgetting prevention are employed to make the learning process efficient and robust. We perform an extensive study of the key features of the proposed framework and analyze the characteristics of the learned representations. Furthermore, we demonstrate the capability of the proposed framework in learning representations that can improve label efficiency in downstream tasks. Our code and trained models will be made publicly available.
IFR-Explore: Learning Inter-object Functional Relationships in 3D Indoor Scenes
Dec 18, 2021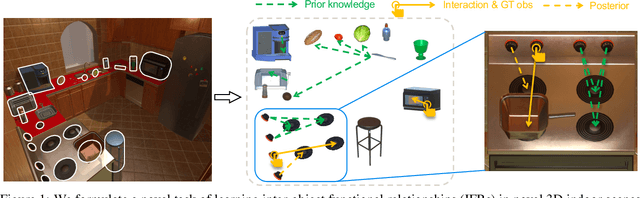
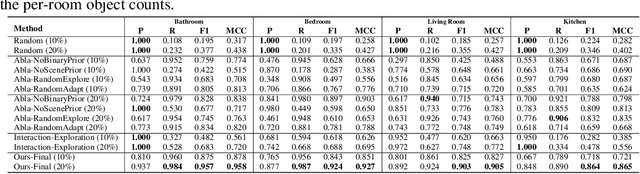
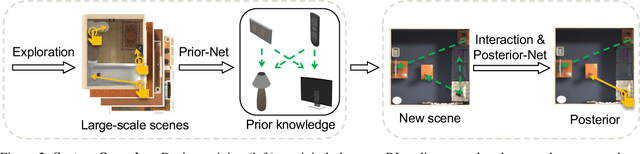

Building embodied intelligent agents that can interact with 3D indoor environments has received increasing research attention in recent years. While most works focus on single-object or agent-object visual functionality and affordances, our work proposes to study a new kind of visual relationship that is also important to perceive and model -- inter-object functional relationships (e.g., a switch on the wall turns on or off the light, a remote control operates the TV). Humans often spend little or no effort to infer these relationships, even when entering a new room, by using our strong prior knowledge (e.g., we know that buttons control electrical devices) or using only a few exploratory interactions in cases of uncertainty (e.g., multiple switches and lights in the same room). In this paper, we take the first step in building AI system learning inter-object functional relationships in 3D indoor environments with key technical contributions of modeling prior knowledge by training over large-scale scenes and designing interactive policies for effectively exploring the training scenes and quickly adapting to novel test scenes. We create a new benchmark based on the AI2Thor and PartNet datasets and perform extensive experiments that prove the effectiveness of our proposed method. Results show that our model successfully learns priors and fast-interactive-adaptation strategies for exploring inter-object functional relationships in complex 3D scenes. Several ablation studies further validate the usefulness of each proposed module.
AdaAfford: Learning to Adapt Manipulation Affordance for 3D Articulated Objects via Few-shot Interactions
Dec 01, 2021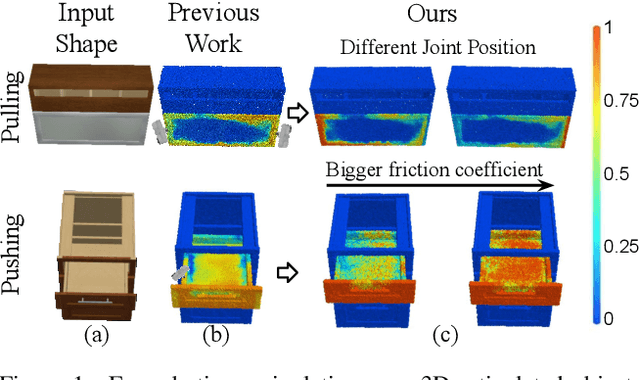
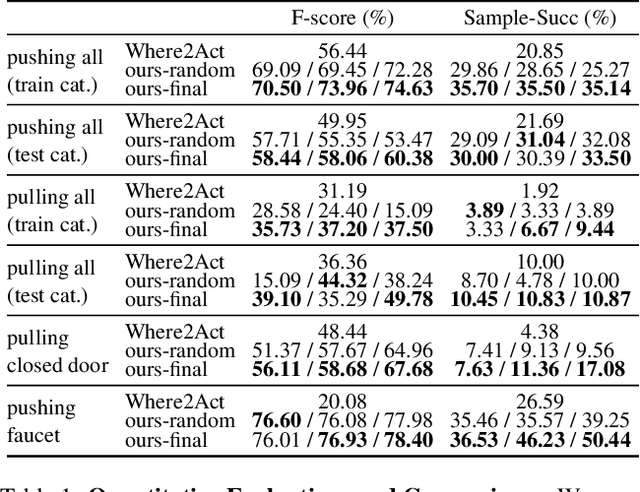
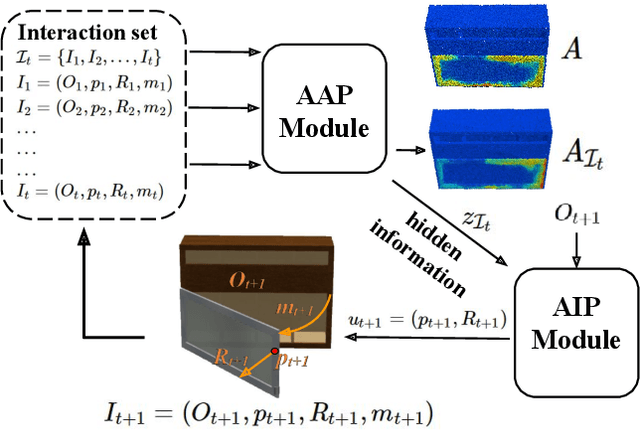
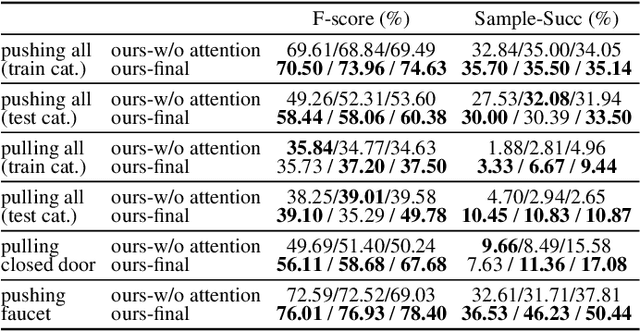
Perceiving and interacting with 3D articulated objects, such as cabinets, doors, and faucets, pose particular challenges for future home-assistant robots performing daily tasks in human environments. Besides parsing the articulated parts and joint parameters, researchers recently advocate learning manipulation affordance over the input shape geometry which is more task-aware and geometrically fine-grained. However, taking only passive observations as inputs, these methods ignore many hidden but important kinematic constraints (e.g., joint location and limits) and dynamic factors (e.g., joint friction and restitution), therefore losing significant accuracy for test cases with such uncertainties. In this paper, we propose a novel framework, named AdaAfford, that learns to perform very few test-time interactions for quickly adapting the affordance priors to more accurate instance-specific posteriors. We conduct large-scale experiments using the PartNet-Mobility dataset and prove that our system performs better than baselines.
Learning to Regrasp by Learning to Place
Sep 18, 2021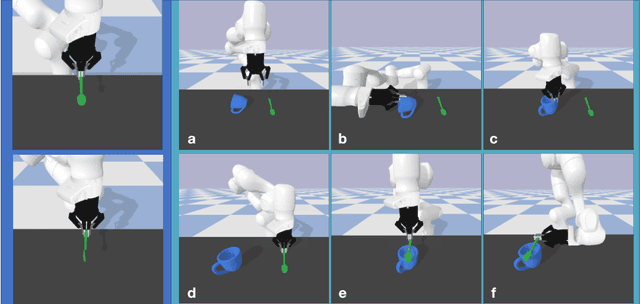
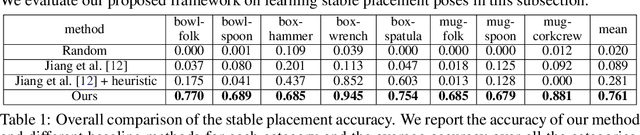
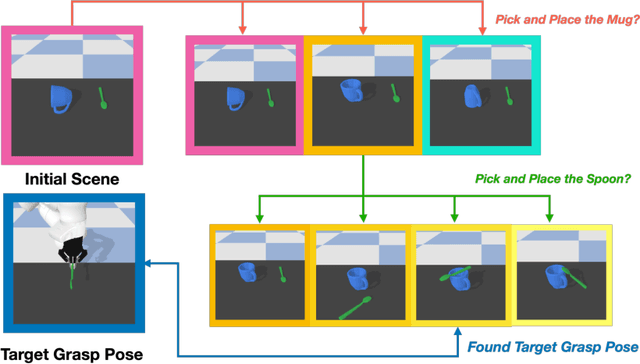

In this paper, we explore whether a robot can learn to regrasp a diverse set of objects to achieve various desired grasp poses. Regrasping is needed whenever a robot's current grasp pose fails to perform desired manipulation tasks. Endowing robots with such an ability has applications in many domains such as manufacturing or domestic services. Yet, it is a challenging task due to the large diversity of geometry in everyday objects and the high dimensionality of the state and action space. In this paper, we propose a system for robots to take partial point clouds of an object and the supporting environment as inputs and output a sequence of pick-and-place operations to transform an initial object grasp pose to the desired object grasp poses. The key technique includes a neural stable placement predictor and a regrasp graph based solution through leveraging and changing the surrounding environment. We introduce a new and challenging synthetic dataset for learning and evaluating the proposed approach. In this dataset, we show that our system is able to achieve 73.3% success rate of regrasping diverse objects.
O2O-Afford: Annotation-Free Large-Scale Object-Object Affordance Learning
Jun 29, 2021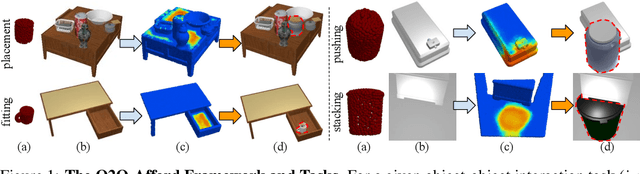
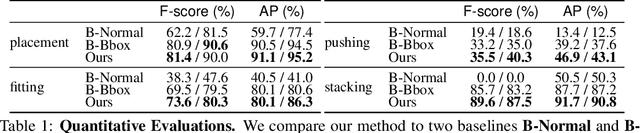
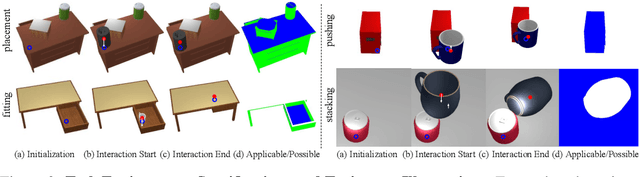

Contrary to the vast literature in modeling, perceiving, and understanding agent-object (e.g., human-object, hand-object, robot-object) interaction in computer vision and robotics, very few past works have studied the task of object-object interaction, which also plays an important role in robotic manipulation and planning tasks. There is a rich space of object-object interaction scenarios in our daily life, such as placing an object on a messy tabletop, fitting an object inside a drawer, pushing an object using a tool, etc. In this paper, we propose a unified affordance learning framework to learn object-object interaction for various tasks. By constructing four object-object interaction task environments using physical simulation (SAPIEN) and thousands of ShapeNet models with rich geometric diversity, we are able to conduct large-scale object-object affordance learning without the need for human annotations or demonstrations. At the core of technical contribution, we propose an object-kernel point convolution network to reason about detailed interaction between two objects. Experiments on large-scale synthetic data and real-world data prove the effectiveness of the proposed approach. Please refer to the project webpage for code, data, video, and more materials: https://cs.stanford.edu/~kaichun/o2oafford
VAT-Mart: Learning Visual Action Trajectory Proposals for Manipulating 3D ARTiculated Objects
Jun 28, 2021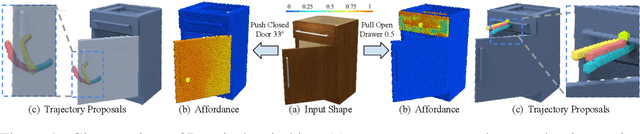

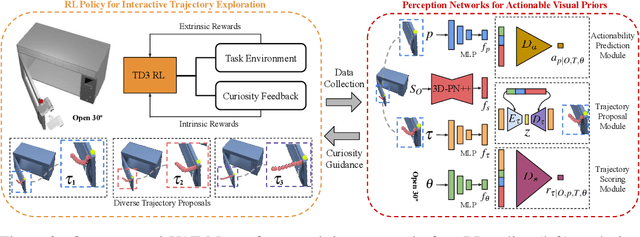

Perceiving and manipulating 3D articulated objects (e.g., cabinets, doors) in human environments is an important yet challenging task for future home-assistant robots. The space of 3D articulated objects is exceptionally rich in their myriad semantic categories, diverse shape geometry, and complicated part functionality. Previous works mostly abstract kinematic structure with estimated joint parameters and part poses as the visual representations for manipulating 3D articulated objects. In this paper, we propose object-centric actionable visual priors as a novel perception-interaction handshaking point that the perception system outputs more actionable guidance than kinematic structure estimation, by predicting dense geometry-aware, interaction-aware, and task-aware visual action affordance and trajectory proposals. We design an interaction-for-perception framework VAT-Mart to learn such actionable visual representations by simultaneously training a curiosity-driven reinforcement learning policy exploring diverse interaction trajectories and a perception module summarizing and generalizing the explored knowledge for pointwise predictions among diverse shapes. Experiments prove the effectiveness of the proposed approach using the large-scale PartNet-Mobility dataset in SAPIEN environment and show promising generalization capabilities to novel test shapes, unseen object categories, and real-world data. Project page: https://hyperplane-lab.github.io/vat-mart
Where2Act: From Pixels to Actions for Articulated 3D Objects
Jan 07, 2021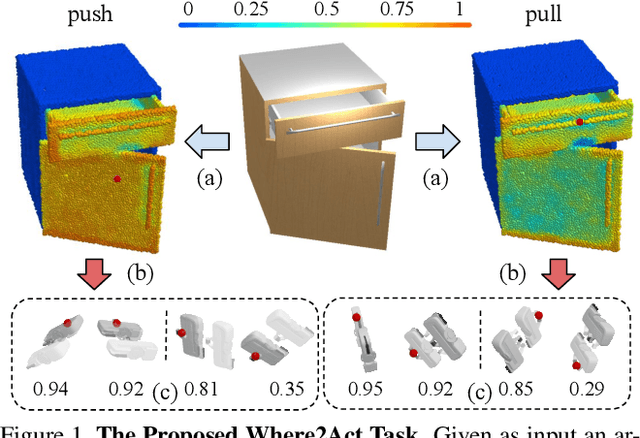
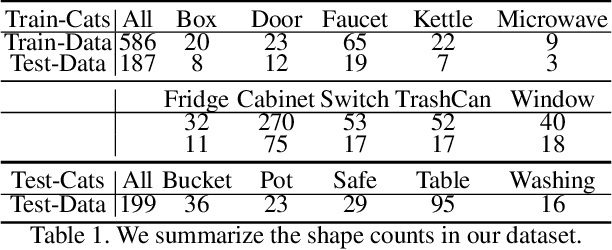
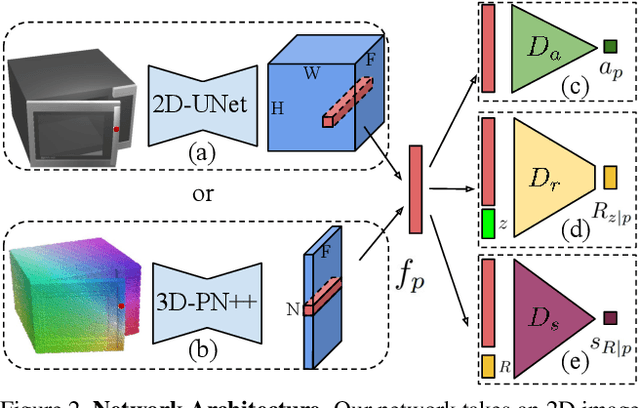
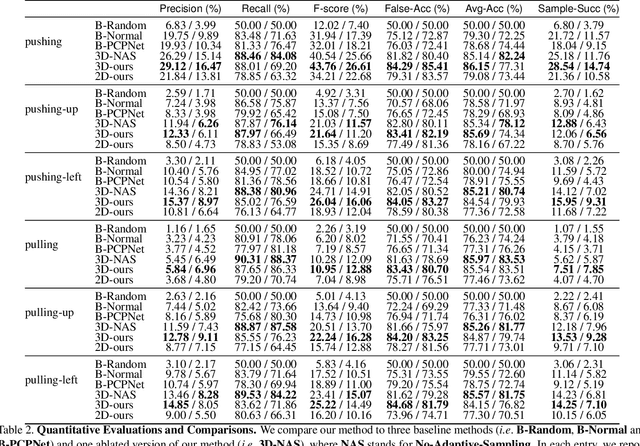
One of the fundamental goals of visual perception is to allow agents to meaningfully interact with their environment. In this paper, we take a step towards that long-term goal -- we extract highly localized actionable information related to elementary actions such as pushing or pulling for articulated objects with movable parts. For example, given a drawer, our network predicts that applying a pulling force on the handle opens the drawer. We propose, discuss, and evaluate novel network architectures that given image and depth data, predict the set of actions possible at each pixel, and the regions over articulated parts that are likely to move under the force. We propose a learning-from-interaction framework with an online data sampling strategy that allows us to train the network in simulation (SAPIEN) and generalizes across categories. But more importantly, our learned models even transfer to real-world data. Check the project website for the code and data release.
Compositionally Generalizable 3D Structure Prediction
Dec 04, 2020

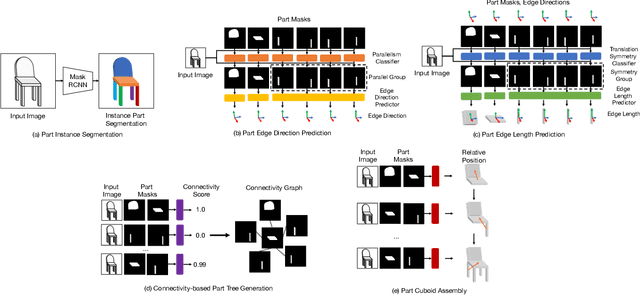
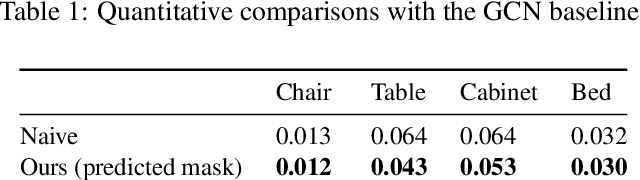
Single-image 3D shape reconstruction is an important and long-standing problem in computer vision. A plethora of existing works is constantly pushing the state-of-the-art performance in the deep learning era. However, there remains a much difficult and largely under-explored issue on how to generalize the learned skills over novel unseen object categories that have very different shape geometry distribution. In this paper, we bring in the concept of compositional generalizability and propose a novel framework that factorizes the 3D shape reconstruction problem into proper sub-problems, each of which is tackled by a carefully designed neural sub-module with generalizability guarantee. The intuition behind our formulation is that object parts (slates and cylindrical parts), their relationships (adjacency, equal-length, and parallelism) and shape substructures (T-junctions and a symmetric group of parts) are mostly shared across object categories, even though the object geometry may look very different (chairs and cabinets). Experiments on PartNet show that we achieve superior performance than baseline methods, which validates our problem factorization and network designs.