 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTR: Improving Large 3D Reconstruction Models through Geometry and Texture Refinement
Jun 09, 2024We propose a novel approach for 3D mesh reconstruction from multi-view images. Our method takes inspiration from large reconstruction models like LRM that use a transformer-based triplane generator and a Neural Radiance Field (NeRF) model trained on multi-view images. However, in our method, we introduce several important modifications that allow us to significantly enhance 3D reconstruction quality. First of all, we examine the original LRM architecture and find several shortcomings. Subsequently, we introduce respective modifications to the LRM architecture, which lead to improved multi-view image representation and more computationally efficient training. Second, in order to improve geometry reconstruction and enable supervision at full image resolution, we extract meshes from the NeRF field in a differentiable manner and fine-tune the NeRF model through mesh rendering. These modifications allow us to achieve state-of-the-art performance on both 2D and 3D evaluation metrics, such as a PSNR of 28.67 on Google Scanned Objects (GSO) dataset. Despite these superior results, our feed-forward model still struggles to reconstruct complex textures, such as text and portraits on assets. To address this, we introduce a lightweight per-instance texture refinement procedure. This procedure fine-tunes the triplane representation and the NeRF color estimation model on the mesh surface using the input multi-view images in just 4 seconds. This refinement improves the PSNR to 29.79 and achieves faithful reconstruction of complex textures, such as text. Additionally, our approach enables various downstream applications, including text- or image-to-3D generation.
TensoIR: Tensorial Inverse Rendering
Apr 24, 2023We propose TensoIR, a novel inverse rendering approach based on tensor factorization and neural fields. Unlike previous works that use purely MLP-based neural fields, thus suffering from low capacity and high computation costs, we extend TensoRF, a state-of-the-art approach for radiance field modeling, to estimate scene geometry, surface reflectance, and environment illumination from multi-view images captured under unknown lighting conditions. Our approach jointly achieves radiance field reconstruction and physically-based model estimation, leading to photo-realistic novel view synthesis and relighting results. Benefiting from the efficiency and extensibility of the TensoRF-based representation, our method can accurately model secondary shading effects (like shadows and indirect lighting) and generally support input images captured under single or multiple unknown lighting conditions. The low-rank tensor representation allows us to not only achieve fast and compact reconstruction but also better exploit shared information under an arbitrary number of capturing lighting conditions. We demonstrate the superiority of our method to baseline methods qualitatively and quantitatively on various challenging synthetic and real-world scenes.
Robust Point Cloud Segmentation with Noisy Annotations
Dec 06, 2022



Point cloud segmentation is a fundamental task in 3D. Despite recent progress on point cloud segmentation with the power of deep networks, current learning methods based on the clean label assumptions may fail with noisy labels. Yet, class labels are often mislabeled at both instance-level and boundary-level in real-world datasets. In this work, we take the lead in solving the instance-level label noise by proposing a Point Noise-Adaptive Learning (PNAL) framework. Compared to noise-robust methods on image tasks, our framework is noise-rate blind, to cope with the spatially variant noise rate specific to point clouds. Specifically, we propose a point-wise confidence selection to obtain reliable labels from the historical predictions of each point. A cluster-wise label correction is proposed with a voting strategy to generate the best possible label by considering the neighbor correlations. To handle boundary-level label noise, we also propose a variant ``PNAL-boundary " with a progressive boundary label cleaning strategy. Extensive experiments demonstrate its effectiveness on both synthetic and real-world noisy datasets. Even with $60\%$ symmetric noise and high-level boundary noise, our framework significantly outperforms its baselines, and is comparable to the upper bound trained on completely clean data. Moreover, we cleaned the popular real-world dataset ScanNetV2 for rigorous experiment. Our code and data is available at https://github.com/pleaseconnectwifi/PNAL.
Close the Visual Domain Gap by Physics-Grounded Active Stereovision Depth Sensor Simulation
Feb 07, 2022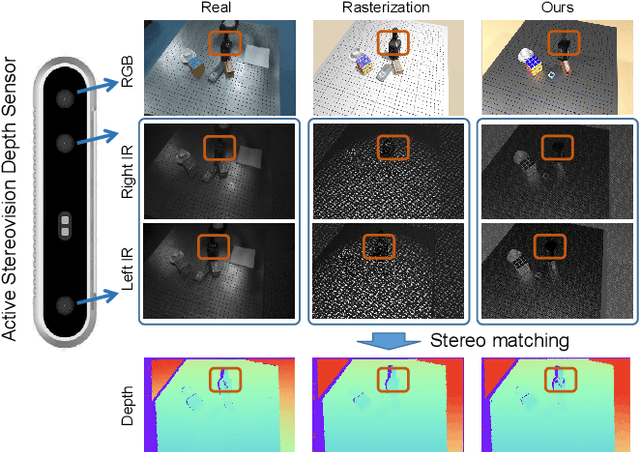
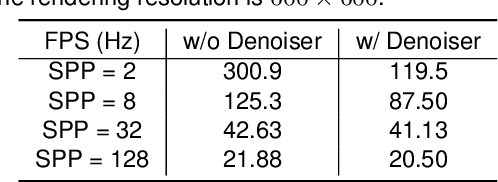
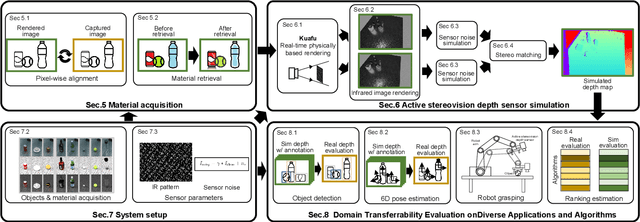
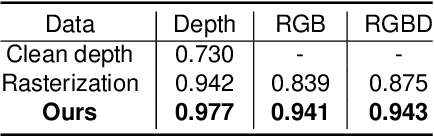
In this paper, we focus on the simulation of active stereovision depth sensors, which are popular in both academic and industry communities. Inspired by the underlying mechanism of the sensors, we designed a fully physics-grounded simulation pipeline, which includes material acquisition, ray tracing based infrared (IR) image rendering, IR noise simulation, and depth estimation. The pipeline is able to generate depth maps with material-dependent error patterns similar to a real depth sensor. We conduct extensive experiments to show that perception algorithms and reinforcement learning policies trained in our simulation platform could transfer well to real world test cases without any fine-tuning. Furthermore, due to the high degree of realism of this simulation, our depth sensor simulator can be used as a convenient testbed to evaluate the algorithm performance in the real world, which will largely reduce the human effort in developing robotic algorithms. The entire pipeline has been integrated into the SAPIEN simulator and is open-sourced to promote the research of vision and robotics communities.
3D Question Answering
Dec 15, 2021

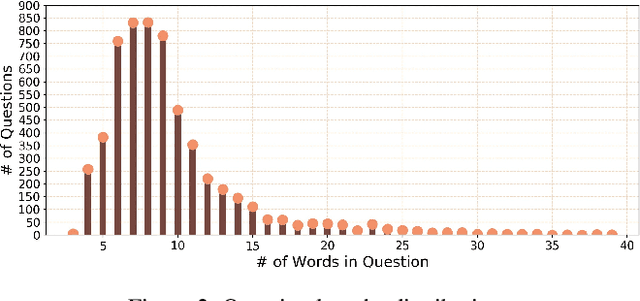

Visual Question Answering (VQA) has witnessed tremendous progress in recent years. However, most efforts only focus on the 2D image question answering tasks. In this paper, we present the first attempt at extending VQA to the 3D domain, which can facilitate artificial intelligence's perception of 3D real-world scenarios. Different from image based VQA, 3D Question Answering (3DQA) takes the color point cloud as input and requires both appearance and 3D geometry comprehension ability to answer the 3D-related questions. To this end, we propose a novel transformer-based 3DQA framework \textbf{``3DQA-TR"}, which consists of two encoders for exploiting the appearance and geometry information, respectively. The multi-modal information of appearance, geometry, and the linguistic question can finally attend to each other via a 3D-Linguistic Bert to predict the target answers. To verify the effectiveness of our proposed 3DQA framework, we further develop the first 3DQA dataset \textbf{``ScanQA"}, which builds on the ScanNet dataset and contains $\sim$6K questions, $\sim$30K answers for $806$ scenes. Extensive experiments on this dataset demonstrate the obvious superiority of our proposed 3DQA framework over existing VQA frameworks, and the effectiveness of our major designs. Our code and dataset will be made publicly available to facilitate the research in this direction.
M3D-VTON: A Monocular-to-3D Virtual Try-On Network
Aug 11, 2021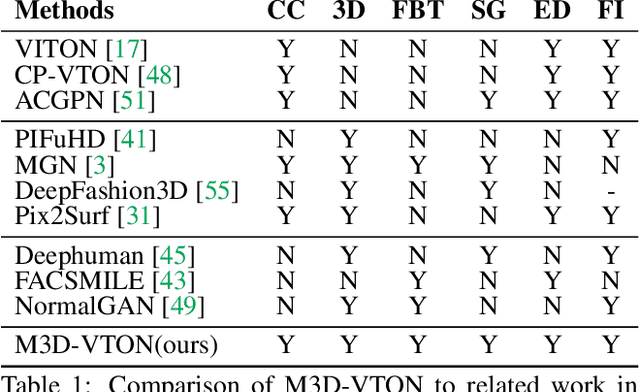
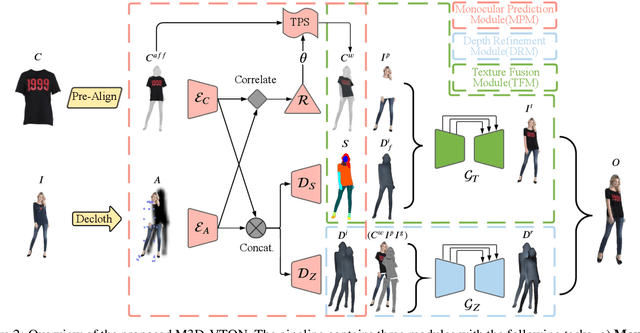
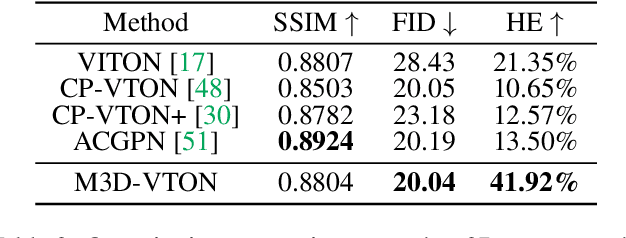
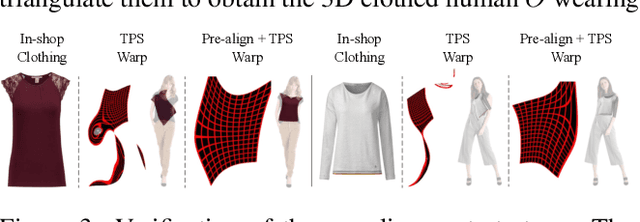
Virtual 3D try-on can provide an intuitive and realistic view for online shopping and has a huge potential commercial value. However, existing 3D virtual try-on methods mainly rely on annotated 3D human shapes and garment templates, which hinders their applications in practical scenarios. 2D virtual try-on approaches provide a faster alternative to manipulate clothed humans, but lack the rich and realistic 3D representation. In this paper, we propose a novel Monocular-to-3D Virtual Try-On Network (M3D-VTON) that builds on the merits of both 2D and 3D approaches. By integrating 2D information efficiently and learning a mapping that lifts the 2D representation to 3D, we make the first attempt to reconstruct a 3D try-on mesh only taking the target clothing and a person image as inputs. The proposed M3D-VTON includes three modules: 1) The Monocular Prediction Module (MPM) that estimates an initial full-body depth map and accomplishes 2D clothes-person alignment through a novel two-stage warping procedure; 2) The Depth Refinement Module (DRM) that refines the initial body depth to produce more detailed pleat and face characteristics; 3) The Texture Fusion Module (TFM) that fuses the warped clothing with the non-target body part to refine the results. We also construct a high-quality synthesized Monocular-to-3D virtual try-on dataset, in which each person image is associated with a front and a back depth map. Extensive experiments demonstrate that the proposed M3D-VTON can manipulate and reconstruct the 3D human body wearing the given clothing with compelling details and is more efficient than other 3D approaches.
Learning with Noisy Labels for Robust Point Cloud Segmentation
Aug 05, 2021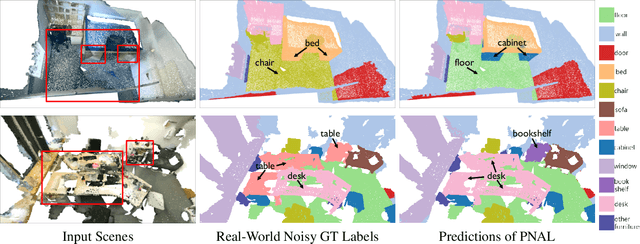
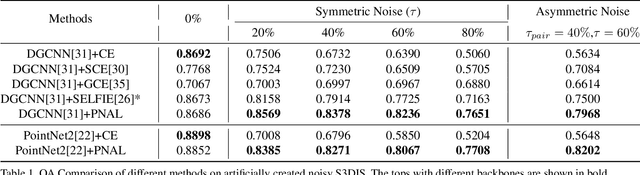
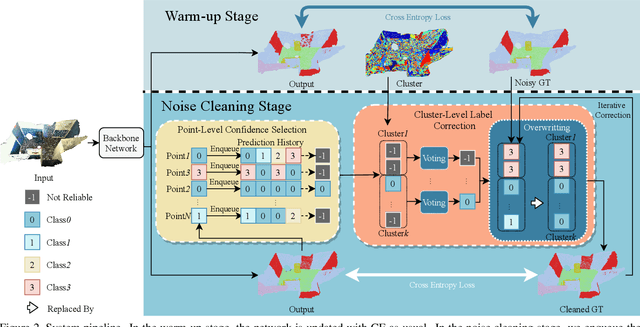
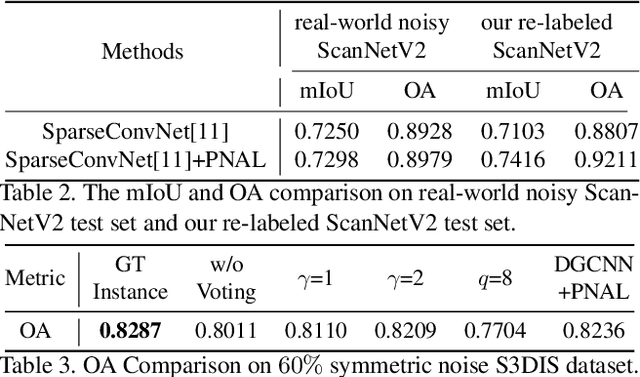
Point cloud segmentation is a fundamental task in 3D. Despite recent progress on point cloud segmentation with the power of deep networks, current deep learning methods based on the clean label assumptions may fail with noisy labels. Yet, object class labels are often mislabeled in real-world point cloud datasets. In this work, we take the lead in solving this issue by proposing a novel Point Noise-Adaptive Learning (PNAL) framework. Compared to existing noise-robust methods on image tasks, our PNAL is noise-rate blind, to cope with the spatially variant noise rate problem specific to point clouds. Specifically, we propose a novel point-wise confidence selection to obtain reliable labels based on the historical predictions of each point. A novel cluster-wise label correction is proposed with a voting strategy to generate the best possible label taking the neighbor point correlations into consideration. We conduct extensive experiments to demonstrate the effectiveness of PNAL on both synthetic and real-world noisy datasets. In particular, even with $60\%$ symmetric noisy labels, our proposed method produces much better results than its baseline counterpart without PNAL and is comparable to the ideal upper bound trained on a completely clean dataset. Moreover, we fully re-labeled the validation set of a popular but noisy real-world scene dataset ScanNetV2 to make it clean, for rigorous experiment and future research. Our code and data are available at \url{https://shuquanye.com/PNAL_website/}.
Compositionally Generalizable 3D Structure Prediction
Dec 04, 2020

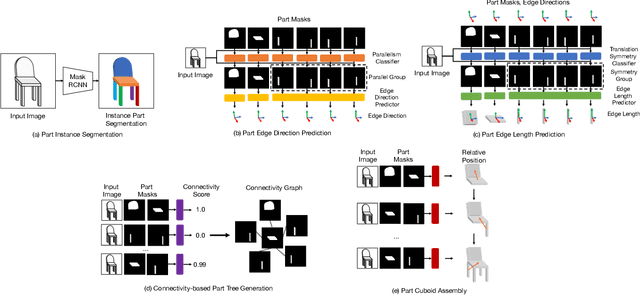
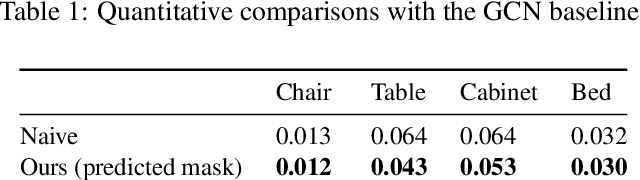
Single-image 3D shape reconstruction is an important and long-standing problem in computer vision. A plethora of existing works is constantly pushing the state-of-the-art performance in the deep learning era. However, there remains a much difficult and largely under-explored issue on how to generalize the learned skills over novel unseen object categories that have very different shape geometry distribution. In this paper, we bring in the concept of compositional generalizability and propose a novel framework that factorizes the 3D shape reconstruction problem into proper sub-problems, each of which is tackled by a carefully designed neural sub-module with generalizability guarantee. The intuition behind our formulation is that object parts (slates and cylindrical parts), their relationships (adjacency, equal-length, and parallelism) and shape substructures (T-junctions and a symmetric group of parts) are mostly shared across object categories, even though the object geometry may look very different (chairs and cabinets). Experiments on PartNet show that we achieve superior performance than baseline methods, which validates our problem factorization and network designs.
Point-Based Multi-View Stereo Network
Aug 12, 2019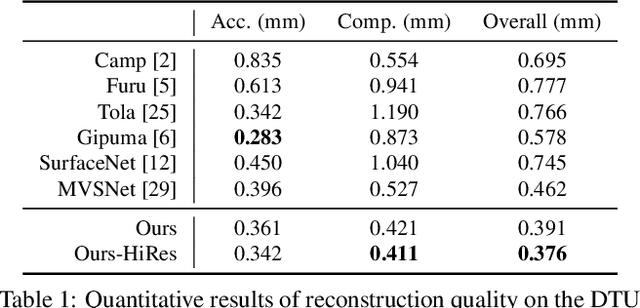
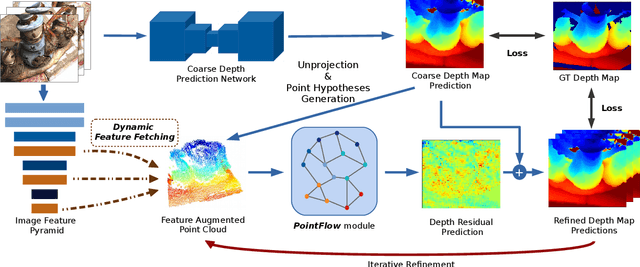
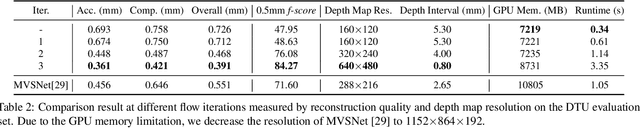
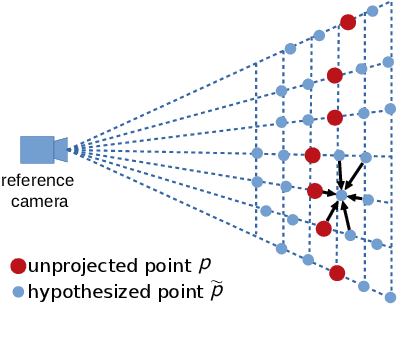
We introduce Point-MVSNet, a novel point-based deep framework for multi-view stereo (MVS). Distinct from existing cost volume approaches, our method directly processes the target scene as point clouds. More specifically, our method predicts the depth in a coarse-to-fine manner. We first generate a coarse depth map, convert it into a point cloud and refine the point cloud iteratively by estimating the residual between the depth of the current iteration and that of the ground truth. Our network leverages 3D geometry priors and 2D texture information jointly and effectively by fusing them into a feature-augmented point cloud, and processes the point cloud to estimate the 3D flow for each point. This point-based architecture allows higher accuracy, more computational efficiency and more flexibility than cost-volume-based counterparts. Experimental results show that our approach achieves a significant improvement in reconstruction quality compared with state-of-the-art methods on the DTU and the Tanks and Temples dataset. Our source code and trained models are available at https://github.com/callmeray/PointMVSNet .