 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models in Biomedical Imaging: Turning Hype into Reality
Dec 17, 2025



Foundation models (FMs) are driving a prominent shift in artificial intelligence across different domains, including biomedical imaging. These models are designed to move beyond narrow pattern recognition towards emulating sophisticated clinical reasoning, understanding complex spatial relationships, and integrating multimodal data with unprecedented flexibility. However, a critical gap exists between this potential and the current reality, where the clinical evaluation and deployment of FMs are hampered by significant challenges. Herein, we critically assess the current state-of-the-art, analyzing hype by examining the core capabilities and limitations of FMs in the biomedical domain. We also provide a taxonomy of reasoning, ranging from emulated sequential logic and spatial understanding to the integration of explicit symbolic knowledge, to evaluate whether these models exhibit genuine cognition or merely mimic surface-level patterns. We argue that a critical frontier lies beyond statistical correlation, in the pursuit of causal inference, which is essential for building robust models that understand cause and effect. Furthermore, we discuss the paramount issues in deployment stemming from trustworthiness, bias, and safety, dissecting the challenges of algorithmic bias, data bias and privacy, and model hallucinations. We also draw attention to the need for more inclusive, rigorous, and clinically relevant validation frameworks to ensure their safe and ethical application. We conclude that while the vision of autonomous AI-doctors remains distant, the immediate reality is the emergence of powerful technology and assistive tools that would benefit clinical practice. The future of FMs in biomedical imaging hinges not on scale alone, but on developing hybrid, causally aware, and verifiably safe systems that augment, rather than replace, human expertise.
L-STEC: Learned Video Compression with Long-term Spatio-Temporal Enhanced Context
Dec 14, 2025Neural Video Compression has emerged in recent years, with condition-based frameworks outperforming traditional codecs. However, most existing methods rely solely on the previous frame's features to predict temporal context, leading to two critical issues. First, the short reference window misses long-term dependencies and fine texture details. Second, propagating only feature-level information accumulates errors over frames, causing prediction inaccuracies and loss of subtle textures. To address these, we propose the Long-term Spatio-Temporal Enhanced Context (L-STEC) method. We first extend the reference chain with LSTM to capture long-term dependencies. We then incorporate warped spatial context from the pixel domain, fusing spatio-temporal information through a multi-receptive field network to better preserve reference details. Experimental results show that L-STEC significantly improves compression by enriching contextual information, achieving 37.01% bitrate savings in PSNR and 31.65% in MS-SSIM compared to DCVC-TCM, outperforming both VTM-17.0 and DCVC-FM and establishing new state-of-the-art performance.
E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
Dec 11, 2025



Self-supervised pre-training has revolutionized foundation models for languages, individual 2D images and videos, but remains largely unexplored for learning 3D-aware representations from multi-view images. In this paper, we present E-RayZer, a self-supervised large 3D Vision model that learns truly 3D-aware representations directly from unlabeled images. Unlike prior self-supervised methods such as RayZer that infer 3D indirectly through latent-space view synthesis, E-RayZer operates directly in 3D space, performing self-supervised 3D reconstruction with Explicit geometry. This formulation eliminates shortcut solutions and yields representations that are geometrically grounded. To ensure convergence and scalability, we introduce a novel fine-grained learning curriculum that organizes training from easy to hard samples and harmonizes heterogeneous data sources in an entirely unsupervised manner. Experiments demonstrate that E-RayZer significantly outperforms RayZer on pose estimation, matches or sometimes surpasses fully supervised reconstruction models such as VGGT. Furthermore, its learned representations outperform leading visual pre-training models (e.g., DINOv3, CroCo v2, VideoMAE V2, and RayZer) when transferring to 3D downstream tasks, establishing E-RayZer as a new paradigm for 3D-aware visual pre-training.
From Noise to Latent: Generating Gaussian Latents for INR-Based Image Compression
Nov 11, 2025Recent implicit neural representation (INR)-based image compression methods have shown competitive performance by overfitting image-specific latent codes. However, they remain inferior to end-to-end (E2E) compression approaches due to the absence of expressive latent representations. On the other hand, E2E methods rely on transmitting latent codes and requiring complex entropy models, leading to increased decoding complexity. Inspired by the normalization strategy in E2E codecs where latents are transformed into Gaussian noise to demonstrate the removal of spatial redundancy, we explore the inverse direction: generating latents directly from Gaussian noise. In this paper, we propose a novel image compression paradigm that reconstructs image-specific latents from a multi-scale Gaussian noise tensor, deterministically generated using a shared random seed. A Gaussian Parameter Prediction (GPP) module estimates the distribution parameters, enabling one-shot latent generation via reparameterization trick. The predicted latent is then passed through a synthesis network to reconstruct the image. Our method eliminates the need to transmit latent codes while preserving latent-based benefits, achieving competitive rate-distortion performance on Kodak and CLIC dataset. To the best of our knowledge, this is the first work to explore Gaussian latent generation for learned image compression.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
A Survey on Deep Text Hashing: Efficient Semantic Text Retrieval with Binary Representation
Oct 31, 2025



With the rapid growth of textual content on the Internet, efficient large-scale semantic text retrieval has garnered increasing attention from both academia and industry. Text hashing, which projects original texts into compact binary hash codes, is a crucial method for this task. By using binary codes, the semantic similarity computation for text pairs is significantly accelerated via fast Hamming distance calculations, and storage costs are greatly reduced. With the advancement of deep learning, deep text hashing has demonstrated significant advantages over traditional, data-independent hashing techniques. By leveraging deep neural networks, these methods can learn compact and semantically rich binary representations directly from data, overcoming the performance limitations of earlier approaches. This survey investigates current deep text hashing methods by categorizing them based on their core components: semantic extraction, hash code quality preservation, and other key technologies. We then present a detailed evaluation schema with results on several popular datasets, followed by a discussion of practical applications and open-source tools for implementation. Finally, we conclude by discussing key challenges and future research directions, including the integration of deep text hashing with large language models to further advance the field. The project for this survey can be accessed at https://github.com/hly1998/DeepTextHashing.
1+1>2: A Synergistic Sparse and Low-Rank Compression Method for Large Language Models
Oct 30, 2025



Large Language Models (LLMs) have demonstrated remarkable proficiency in language comprehension and generation; however, their widespread adoption is constrained by substantial bandwidth and computational demands. While pruning and low-rank approximation have each demonstrated promising performance individually, their synergy for LLMs remains underexplored. We introduce \underline{S}ynergistic \underline{S}parse and \underline{L}ow-Rank \underline{C}ompression (SSLC) methods for LLMs, which leverages the strengths of both techniques: low-rank approximation compresses the model by retaining its essential structure with minimal information loss, whereas sparse optimization eliminates non-essential weights, preserving those crucial for generalization. Based on theoretical analysis, we first formulate the low-rank approximation and sparse optimization as a unified problem and solve it by iterative optimization algorithm. Experiments on LLaMA and Qwen2.5 models (7B-70B) show that SSLC, without any additional training steps, consistently surpasses standalone methods, achieving state-of-the-arts results. Notably, SSLC compresses Qwen2.5 by 50\% with no performance drop and achieves at least 1.63$\times$ speedup, offering a practical solution for efficient LLM deployment.
pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation
Oct 16, 2025Few-step diffusion or flow-based generative models typically distill a velocity-predicting teacher into a student that predicts a shortcut towards denoised data. This format mismatch has led to complex distillation procedures that often suffer from a quality-diversity trade-off. To address this, we propose policy-based flow models ($\pi$-Flow). $\pi$-Flow modifies the output layer of a student flow model to predict a network-free policy at one timestep. The policy then produces dynamic flow velocities at future substeps with negligible overhead, enabling fast and accurate ODE integration on these substeps without extra network evaluations. To match the policy's ODE trajectory to the teacher's, we introduce a novel imitation distillation approach, which matches the policy's velocity to the teacher's along the policy's trajectory using a standard $\ell_2$ flow matching loss. By simply mimicking the teacher's behavior, $\pi$-Flow enables stable and scalable training and avoids the quality-diversity trade-off. On ImageNet 256$^2$, it attains a 1-NFE FID of 2.85, outperforming MeanFlow of the same DiT architecture. On FLUX.1-12B and Qwen-Image-20B at 4 NFEs, $\pi$-Flow achieves substantially better diversity than state-of-the-art few-step methods, while maintaining teacher-level quality.
AdaSwitch: Adaptive Switching Generation for Knowledge Distillation
Oct 09, 2025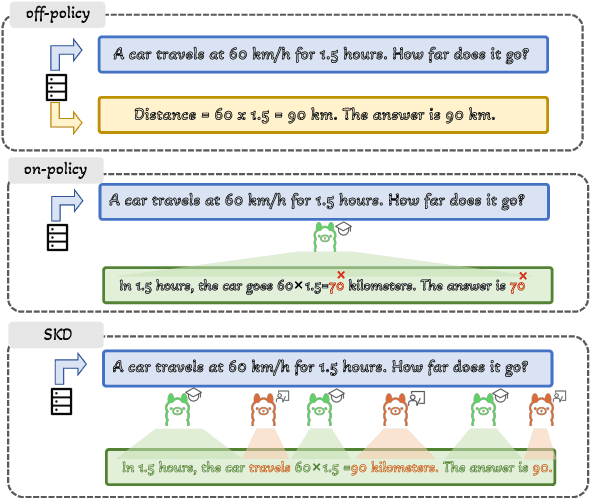
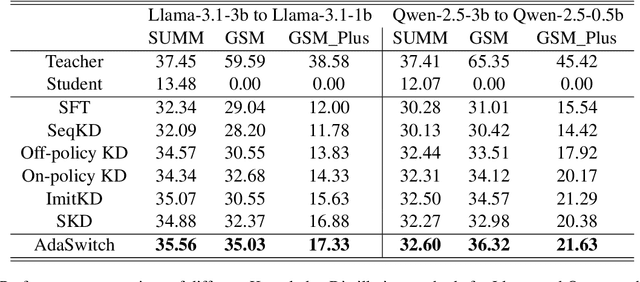
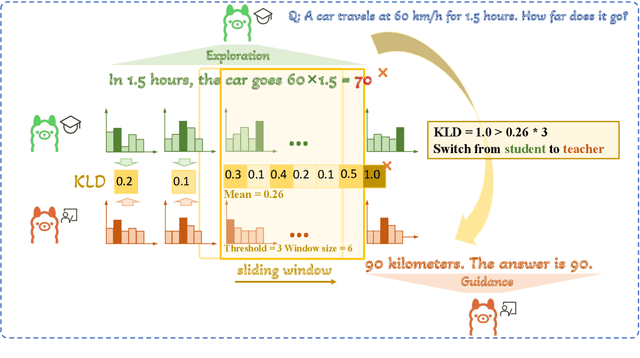
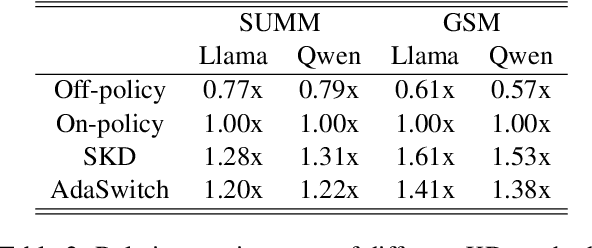
Small language models (SLMs) are crucial for applications with strict latency and computational constraints, yet achieving high performance remains challenging. Knowledge distillation (KD) can transfer capabilities from large teacher models, but existing methods involve trade-offs: off-policy distillation provides high-quality supervision but introduces a training-inference mismatch, while on-policy approaches maintain consistency but rely on low-quality student outputs. To address these issues, we propose AdaSwitch, a novel approach that dynamically combines on-policy and off-policy generation at the token level. AdaSwitch allows the student to first explore its own predictions and then selectively integrate teacher guidance based on real-time quality assessment. This approach simultaneously preserves consistency and maintains supervision quality. Experiments on three datasets with two teacher-student LLM pairs demonstrate that AdaSwitch consistently improves accuracy, offering a practical and effective method for distilling SLMs with acceptable additional overhead.
NAMOUnc: Navigation Among Movable Obstacles with Decision Making on Uncertainty Interval
Sep 16, 2025Navigation among movable obstacles (NAMO) is a critical task in robotics, often challenged by real-world uncertainties such as observation noise, model approximations, action failures, and partial observability. Existing solutions frequently assume ideal conditions, leading to suboptimal or risky decisions. This paper introduces NAMOUnc, a novel framework designed to address these uncertainties by integrating them into the decision-making process. We first estimate them and compare the corresponding time cost intervals for removing and bypassing obstacles, optimizing both the success rate and time efficiency, ensuring safer and more efficient navigation. We validate our method through extensive simulations and real-world experiments, demonstrating significant improvements over existing NAMO frameworks. More details can be found in our website: https://kai-zhang-er.github.io/namo-uncertainty/