 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Noise to Latent: Generating Gaussian Latents for INR-Based Image Compression
Nov 11, 2025Recent implicit neural representation (INR)-based image compression methods have shown competitive performance by overfitting image-specific latent codes. However, they remain inferior to end-to-end (E2E) compression approaches due to the absence of expressive latent representations. On the other hand, E2E methods rely on transmitting latent codes and requiring complex entropy models, leading to increased decoding complexity. Inspired by the normalization strategy in E2E codecs where latents are transformed into Gaussian noise to demonstrate the removal of spatial redundancy, we explore the inverse direction: generating latents directly from Gaussian noise. In this paper, we propose a novel image compression paradigm that reconstructs image-specific latents from a multi-scale Gaussian noise tensor, deterministically generated using a shared random seed. A Gaussian Parameter Prediction (GPP) module estimates the distribution parameters, enabling one-shot latent generation via reparameterization trick. The predicted latent is then passed through a synthesis network to reconstruct the image. Our method eliminates the need to transmit latent codes while preserving latent-based benefits, achieving competitive rate-distortion performance on Kodak and CLIC dataset. To the best of our knowledge, this is the first work to explore Gaussian latent generation for learned image compression.
Neural Video Compression with In-Loop Contextual Filtering and Out-of-Loop Reconstruction Enhancement
Sep 04, 2025This paper explores the application of enhancement filtering techniques in neural video compression. Specifically, we categorize these techniques into in-loop contextual filtering and out-of-loop reconstruction enhancement based on whether the enhanced representation affects the subsequent coding loop. In-loop contextual filtering refines the temporal context by mitigating error propagation during frame-by-frame encoding. However, its influence on both the current and subsequent frames poses challenges in adaptively applying filtering throughout the sequence. To address this, we introduce an adaptive coding decision strategy that dynamically determines filtering application during encoding. Additionally, out-of-loop reconstruction enhancement is employed to refine the quality of reconstructed frames, providing a simple yet effective improvement in coding efficiency. To the best of our knowledge, this work presents the first systematic study of enhancement filtering in the context of conditional-based neural video compression. Extensive experiments demonstrate a 7.71% reduction in bit rate compared to state-of-the-art neural video codecs, validating the effectiveness of the proposed approach.
EHVC: Efficient Hierarchical Reference and Quality Structure for Neural Video Coding
Sep 04, 2025Neural video codecs (NVCs), leveraging the power of end-to-end learning, have demonstrated remarkable coding efficiency improvements over traditional video codecs. Recent research has begun to pay attention to the quality structures in NVCs, optimizing them by introducing explicit hierarchical designs. However, less attention has been paid to the reference structure design, which fundamentally should be aligned with the hierarchical quality structure. In addition, there is still significant room for further optimization of the hierarchical quality structure. To address these challenges in NVCs, we propose EHVC, an efficient hierarchical neural video codec featuring three key innovations: (1) a hierarchical multi-reference scheme that draws on traditional video codec design to align reference and quality structures, thereby addressing the reference-quality mismatch; (2) a lookahead strategy to utilize an encoder-side context from future frames to enhance the quality structure; (3) a layer-wise quality scale with random quality training strategy to stabilize quality structures during inference. With these improvements, EHVC achieves significantly superior performance to the state-of-the-art NVCs. Code will be released in: https://github.com/bytedance/NEVC.
QVRF: A Quantization-error-aware Variable Rate Framework for Learned Image Compression
Mar 10, 2023Learned image compression has exhibited promising compression performance, but variable bitrates over a wide range remain a challenge. State-of-the-art variable rate methods compromise the loss of model performance and require numerous additional parameters. In this paper, we present a Quantization-error-aware Variable Rate Framework (QVRF) that utilizes a univariate quantization regulator a to achieve wide-range variable rates within a single model. Specifically, QVRF defines a quantization regulator vector coupled with predefined Lagrange multipliers to control quantization error of all latent representation for discrete variable rates. Additionally, the reparameterization method makes QVRF compatible with a round quantizer. Exhaustive experiments demonstrate that existing fixed-rate VAE-based methods equipped with QVRF can achieve wide-range continuous variable rates within a single model without significant performance degradation. Furthermore, QVRF outperforms contemporary variable-rate methods in rate-distortion performance with minimal additional parameters.
A Dataset and Method for Hallux Valgus Angle Estimation Based on Deep Learing
Jul 08, 2021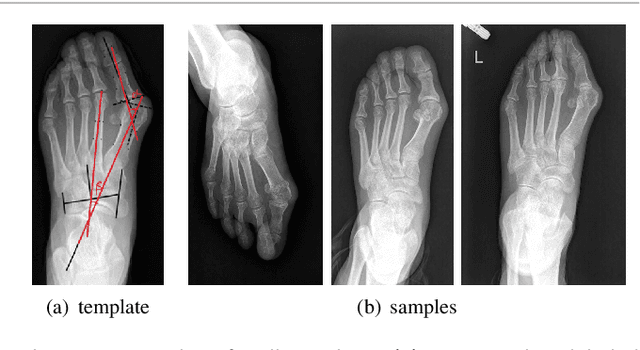

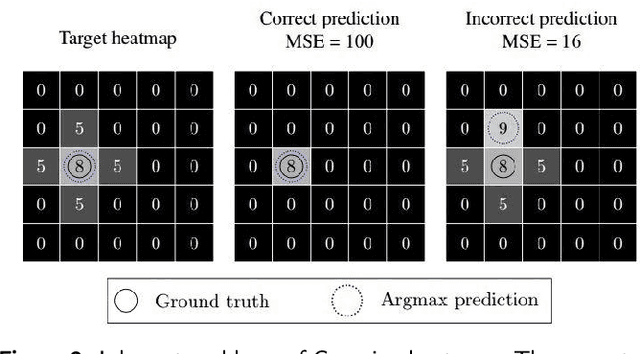
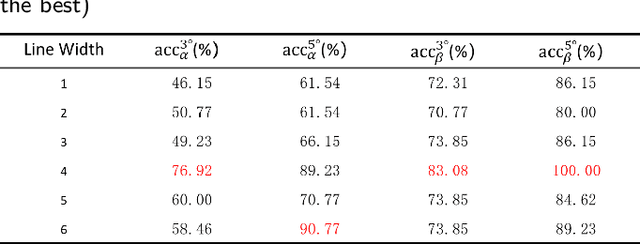
Angular measurements is essential to make a resonable treatment for Hallux valgus (HV), a common forefoot deformity. However, it still depends on manual labeling and measurement, which is time-consuming and sometimes unreliable. Automating this process is a thing of concern. However, it lack of dataset and the keypoints based method which made a great success in pose estimation is not suitable for this field.To solve the problems, we made a dataset and developed an algorithm based on deep learning and linear regression. It shows great fitting ability to the ground truth.
Learned Block-based Hybrid Image Compression
Jan 18, 2021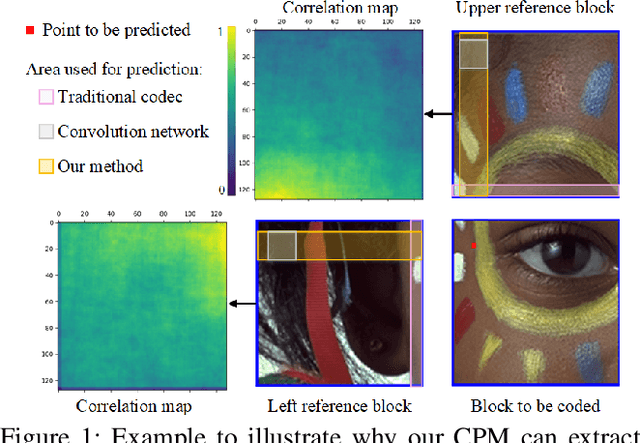
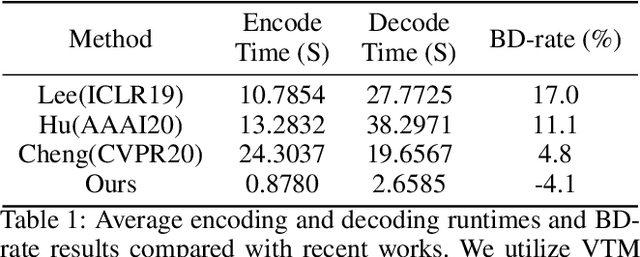
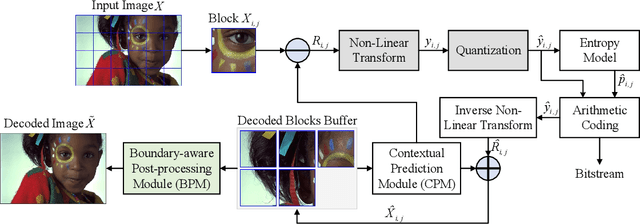
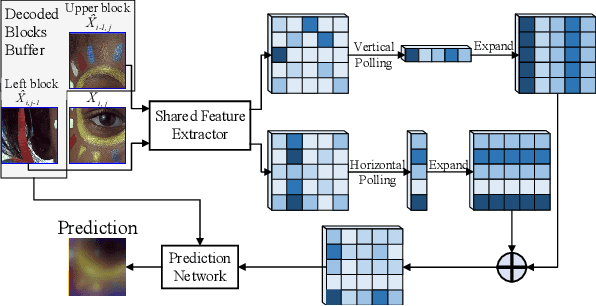
Recent works on learned image compression perform encoding and decoding processes in a full-resolution manner, resulting in two problems when deployed for practical applications. First, parallel acceleration of the autoregressive entropy model cannot be achieved due to serial decoding. Second, full-resolution inference often causes the out-of-memory(OOM) problem with limited GPU resources, especially for high-resolution images. Block partition is a good design choice to handle the above issues, but it brings about new challenges in reducing the redundancy between blocks and eliminating block effects. To tackle the above challenges, this paper provides a learned block-based hybrid image compression (LBHIC) framework. Specifically, we introduce explicit intra prediction into a learned image compression framework to utilize the relation among adjacent blocks. Superior to context modeling by linear weighting of neighbor pixels in traditional codecs, we propose a contextual prediction module (CPM) to better capture long-range correlations by utilizing the strip pooling to extract the most relevant information in neighboring latent space, thus achieving effective information prediction. Moreover, to alleviate blocking artifacts, we further propose a boundary-aware postprocessing module (BPM) with the edge importance taken into account. Extensive experiments demonstrate that the proposed LBHIC codec outperforms the VVC, with a bit-rate conservation of 4.1%, and reduces the decoding time by approximately 86.7% compared with that of state-of-the-art learned image compression methods.
FAN: Frequency Aggregation Network for Real Image Super-resolution
Sep 30, 2020

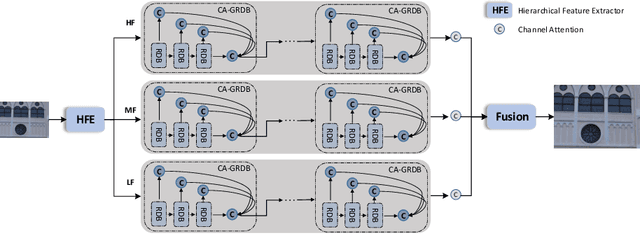

Single image super-resolution (SISR) aims to recover the high-resolution (HR) image from its low-resolution (LR) input image. With the development of deep learning, SISR has achieved great progress. However, It is still a challenge to restore the real-world LR image with complicated authentic degradations. Therefore, we propose FAN, a frequency aggregation network, to address the real-world image super-resolu-tion problem. Specifically, we extract different frequencies of the LR image and pass them to a channel attention-grouped residual dense network (CA-GRDB) individually to output corresponding feature maps. And then aggregating these residual dense feature maps adaptively to recover the HR image with enhanced details and textures. We conduct extensive experiments quantitatively and qualitatively to verify that our FAN performs well on the real image super-resolution task of AIM 2020 challenge. According to the released final results, our team SR-IM achieves the fourth place on the X4 track with PSNR of 31.1735 and SSIM of 0.8728.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020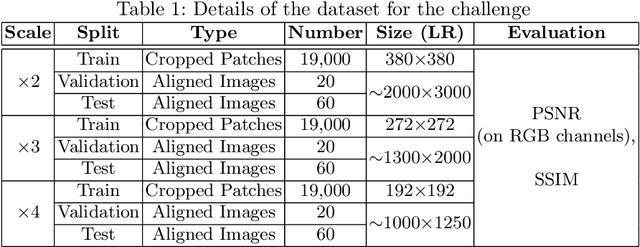
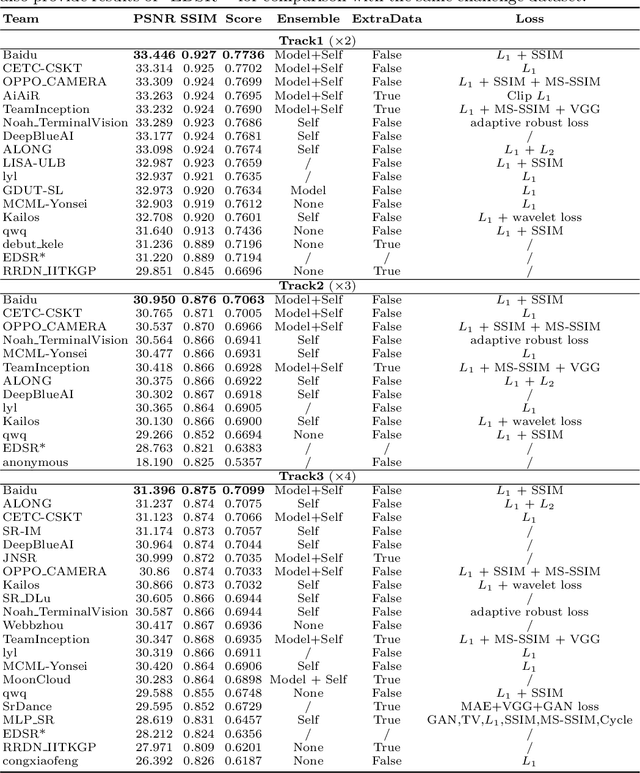
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
Learning Disentangled Feature Representation for Hybrid-distorted Image Restoration
Jul 22, 2020
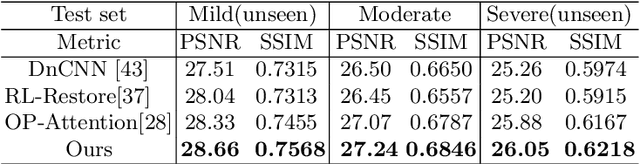
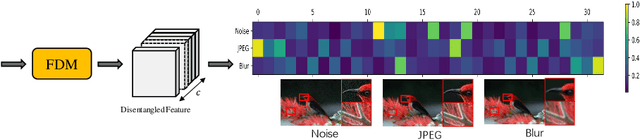

Hybrid-distorted image restoration (HD-IR) is dedicated to restore real distorted image that is degraded by multiple distortions. Existing HD-IR approaches usually ignore the inherent interference among hybrid distortions which compromises the restoration performance. To decompose such interference, we introduce the concept of Disentangled Feature Learning to achieve the feature-level divide-and-conquer of hybrid distortions. Specifically, we propose the feature disentanglement module (FDM) to distribute feature representations of different distortions into different channels by revising gain-control-based normalization. We also propose a feature aggregation module (FAM) with channel-wise attention to adaptively filter out the distortion representations and aggregate useful content information from different channels for the construction of raw image. The effectiveness of the proposed scheme is verified by visualizing the correlation matrix of features and channel responses of different distortions. Extensive experimental results also prove superior performance of our approach compared with the latest HD-IR schemes.
Memorize, Then Recall: A Generative Framework for Low Bit-rate Surveillance Video Compression
Dec 30, 2019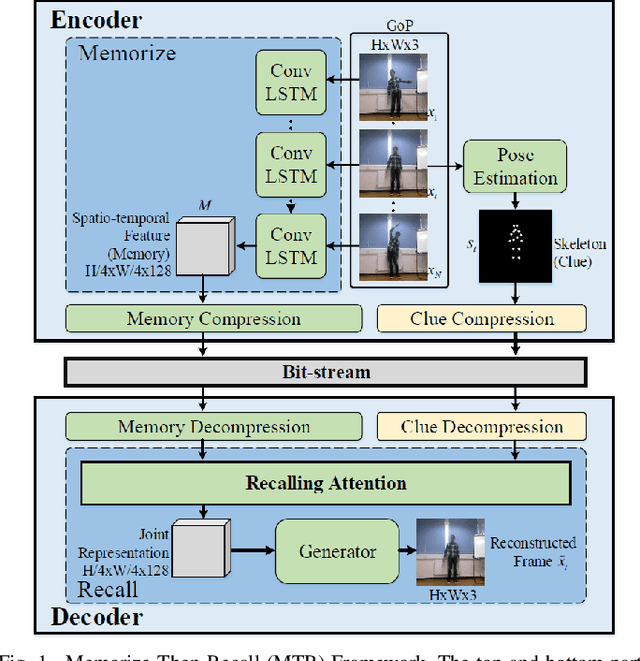
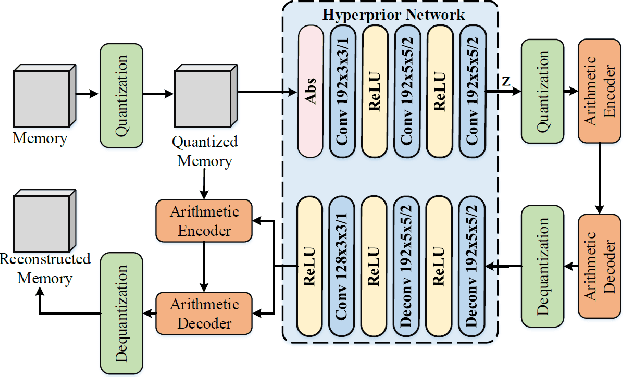
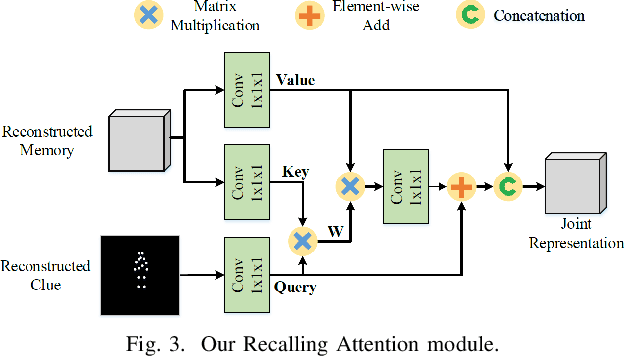

Surveillance video applications grow dramatically in public safety and daily life, which often detect and recognize moving objects inside video signals. Existing surveillance video compression schemes are still based on traditional hybrid coding frameworks handling temporal redundancy by block-wise motion compensation mechanism, lacking the extraction and utilization of inherent structure information. In this paper, we alleviate this issue by decomposing surveillance video signals into the structure of a global spatio-temporal feature (memory) and skeleton for each frame (clue). The memory is abstracted by a recurrent neural network across Group of Pictures (GoP) inside one video sequence, representing appearance for elements that appeared inside GoP. While the skeleton is obtained by the specific pose estimator, it served as a clue for recalling memory. In addition, we introduce an attention mechanism to learn the relationships between appearance and skeletons. And we reconstruct each frame with an adversarial training process. Experimental results demonstrate that our approach can effectively generate realistic frames from appearance and skeleton accordingly. Compared with the latest video compression standard H.265, it shows much higher compression performance on surveillance video.