 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL-STEC: Learned Video Compression with Long-term Spatio-Temporal Enhanced Context
Dec 14, 2025Neural Video Compression has emerged in recent years, with condition-based frameworks outperforming traditional codecs. However, most existing methods rely solely on the previous frame's features to predict temporal context, leading to two critical issues. First, the short reference window misses long-term dependencies and fine texture details. Second, propagating only feature-level information accumulates errors over frames, causing prediction inaccuracies and loss of subtle textures. To address these, we propose the Long-term Spatio-Temporal Enhanced Context (L-STEC) method. We first extend the reference chain with LSTM to capture long-term dependencies. We then incorporate warped spatial context from the pixel domain, fusing spatio-temporal information through a multi-receptive field network to better preserve reference details. Experimental results show that L-STEC significantly improves compression by enriching contextual information, achieving 37.01% bitrate savings in PSNR and 31.65% in MS-SSIM compared to DCVC-TCM, outperforming both VTM-17.0 and DCVC-FM and establishing new state-of-the-art performance.
Decoupling Template Bias in CLIP: Harnessing Empty Prompts for Enhanced Few-Shot Learning
Dec 10, 2025The Contrastive Language-Image Pre-Training (CLIP) model excels in few-shot learning by aligning visual and textual representations. Our study shows that template-sample similarity (TSS), defined as the resemblance between a text template and an image sample, introduces bias. This bias leads the model to rely on template proximity rather than true sample-to-category alignment, reducing both accuracy and robustness in classification. We present a framework that uses empty prompts, textual inputs that convey the idea of "emptiness" without category information. These prompts capture unbiased template features and offset TSS bias. The framework employs two stages. During pre-training, empty prompts reveal and reduce template-induced bias within the CLIP encoder. During few-shot fine-tuning, a bias calibration loss enforces correct alignment between images and their categories, ensuring the model focuses on relevant visual cues. Experiments across multiple benchmarks demonstrate that our template correction method significantly reduces performance fluctuations caused by TSS, yielding higher classification accuracy and stronger robustness. The repository of this project is available at https://github.com/zhenyuZ-HUST/Decoupling-Template-Bias-in-CLIP.
Compressed Domain Prior-Guided Video Super-Resolution for Cloud Gaming Content
Jan 03, 2025Cloud gaming is an advanced form of Internet service that necessitates local terminals to decode within limited resources and time latency. Super-Resolution (SR) techniques are often employed on these terminals as an efficient way to reduce the required bit-rate bandwidth for cloud gaming. However, insufficient attention has been paid to SR of compressed game video content. Most SR networks amplify block artifacts and ringing effects in decoded frames while ignoring edge details of game content, leading to unsatisfactory reconstruction results. In this paper, we propose a novel lightweight network called Coding Prior-Guided Super-Resolution (CPGSR) to address the SR challenges in compressed game video content. First, we design a Compressed Domain Guided Block (CDGB) to extract features of different depths from coding priors, which are subsequently integrated with features from the U-net backbone. Then, a series of re-parameterization blocks are utilized for reconstruction. Ultimately, inspired by the quantization in video coding, we propose a partitioned focal frequency loss to effectively guide the model's focus on preserving high-frequency information. Extensive experiments demonstrate the advancement of our approach.
MICM: Rethinking Unsupervised Pretraining for Enhanced Few-shot Learning
Aug 23, 2024



Humans exhibit a remarkable ability to learn quickly from a limited number of labeled samples, a capability that starkly contrasts with that of current machine learning systems. Unsupervised Few-Shot Learning (U-FSL) seeks to bridge this divide by reducing reliance on annotated datasets during initial training phases. In this work, we first quantitatively assess the impacts of Masked Image Modeling (MIM) and Contrastive Learning (CL) on few-shot learning tasks. Our findings highlight the respective limitations of MIM and CL in terms of discriminative and generalization abilities, which contribute to their underperformance in U-FSL contexts. To address these trade-offs between generalization and discriminability in unsupervised pretraining, we introduce a novel paradigm named Masked Image Contrastive Modeling (MICM). MICM creatively combines the targeted object learning strength of CL with the generalized visual feature learning capability of MIM, significantly enhancing its efficacy in downstream few-shot learning inference. Extensive experimental analyses confirm the advantages of MICM, demonstrating significant improvements in both generalization and discrimination capabilities for few-shot learning. Our comprehensive quantitative evaluations further substantiate the superiority of MICM, showing that our two-stage U-FSL framework based on MICM markedly outperforms existing leading baselines.
Visual Analysis Motivated Rate-Distortion Model for Image Coding
Apr 21, 2021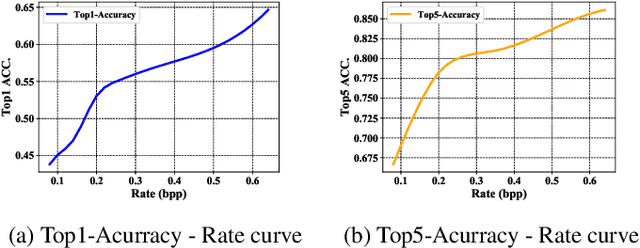
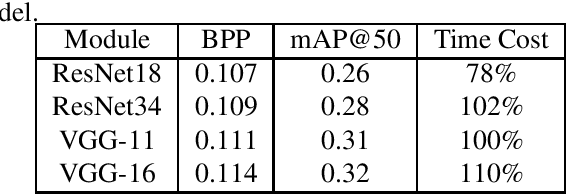
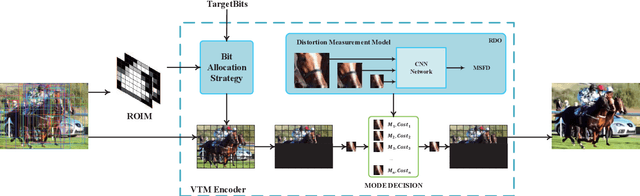

Optimized for pixel fidelity metrics, images compressed by existing image codec are facing systematic challenges when used for visual analysis tasks, especially under low-bitrate coding. This paper proposes a visual analysis-motivated rate-distortion model for Versatile Video Coding (VVC) intra compression. The proposed model has two major contributions, a novel rate allocation strategy and a new distortion measurement model. We first propose the region of interest for machine (ROIM) to evaluate the degree of importance for each coding tree unit (CTU) in visual analysis. Then, a novel CTU-level bit allocation model is proposed based on ROIM and the local texture characteristics of each CTU. After an in-depth analysis of multiple distortion models, a visual analysis friendly distortion criteria is subsequently proposed by extracting deep feature of each coding unit (CU). To alleviate the problem of lacking spatial context information when calculating the distortion of each CU, we finally propose a multi-scale feature distortion (MSFD) metric using different neighboring pixels by weighting the extracted deep features in each scale. Extensive experimental results show that the proposed scheme could achieve up to 28.17\% bitrate saving under the same analysis performance among several typical visual analysis tasks such as image classification, object detection, and semantic segmentation.