 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Transformer for Survival Prediction Using Multimodality Whole Slide Images and Genomics
Nov 29, 2022Learning good representation of giga-pixel level whole slide pathology images (WSI) for downstream tasks is critical. Previous studies employ multiple instance learning (MIL) to represent WSIs as bags of sampled patches because, for most occasions, only slide-level labels are available, and only a tiny region of the WSI is disease-positive area. However, WSI representation learning still remains an open problem due to: (1) patch sampling on a higher resolution may be incapable of depicting microenvironment information such as the relative position between the tumor cells and surrounding tissues, while patches at lower resolution lose the fine-grained detail; (2) extracting patches from giant WSI results in large bag size, which tremendously increases the computational cost. To solve the problems, this paper proposes a hierarchical-based multimodal transformer framework that learns a hierarchical mapping between pathology images and corresponding genes. Precisely, we randomly extract instant-level patch features from WSIs with different magnification. Then a co-attention mapping between imaging and genomics is learned to uncover the pairwise interaction and reduce the space complexity of imaging features. Such early fusion makes it computationally feasible to use MIL Transformer for the survival prediction task. Our architecture requires fewer GPU resources compared with benchmark methods while maintaining better WSI representation ability. We evaluate our approach on five cancer types from the Cancer Genome Atlas database and achieved an average c-index of $0.673$, outperforming the state-of-the-art multimodality methods.
Pareto-aware Neural Architecture Generation for Diverse Computational Budgets
Oct 14, 2022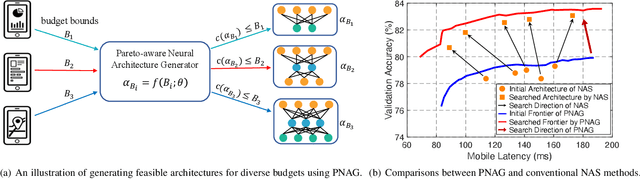
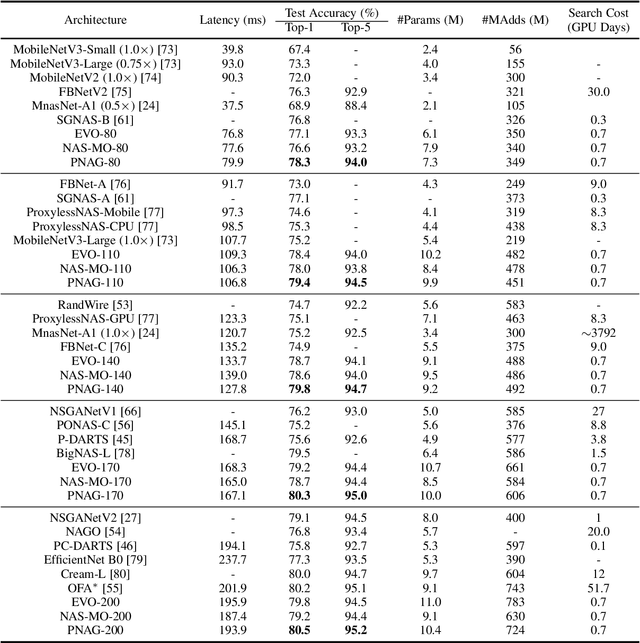
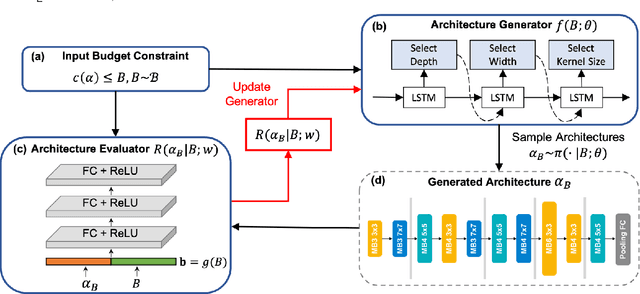
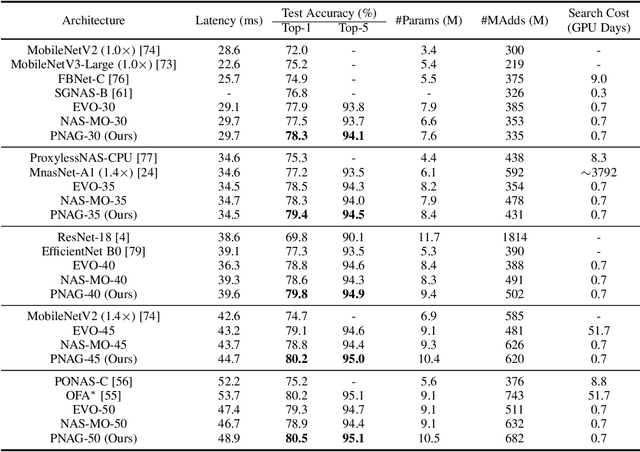
Designing feasible and effective architectures under diverse computational budgets, incurred by different applications/devices, is essential for deploying deep models in real-world applications. To achieve this goal, existing methods often perform an independent architecture search process for each target budget, which is very inefficient yet unnecessary. More critically, these independent search processes cannot share their learned knowledge (i.e., the distribution of good architectures) with each other and thus often result in limited search results. To address these issues, we propose a Pareto-aware Neural Architecture Generator (PNAG) which only needs to be trained once and dynamically produces the Pareto optimal architecture for any given budget via inference. To train our PNAG, we learn the whole Pareto frontier by jointly finding multiple Pareto optimal architectures under diverse budgets. Such a joint search algorithm not only greatly reduces the overall search cost but also improves the search results. Extensive experiments on three hardware platforms (i.e., mobile device, CPU, and GPU) show the superiority of our method over existing methods.
MARS: A Motif-based Autoregressive Model for Retrosynthesis Prediction
Sep 27, 2022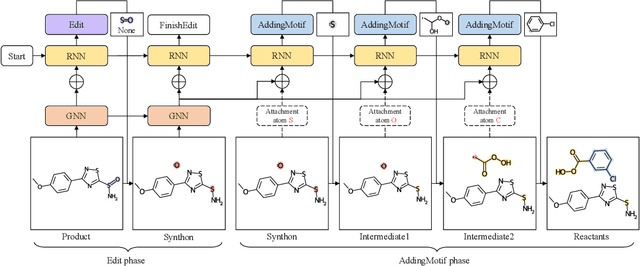
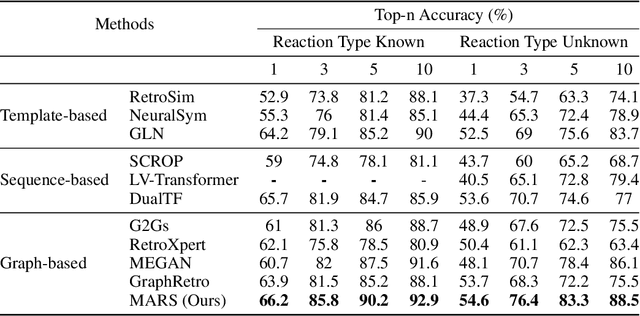
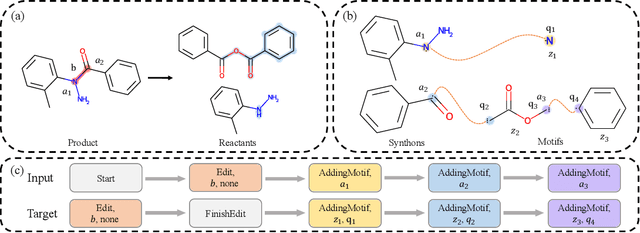
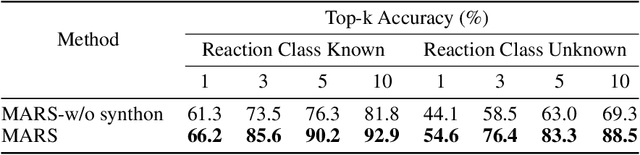
Retrosynthesis is a major task for drug discovery. It is formulated as a graph-generating problem by many existing approaches. Specifically, these methods firstly identify the reaction center, and break target molecule accordingly to generate synthons. Reactants are generated by either adding atoms sequentially to synthon graphs or directly adding proper leaving groups. However, both two strategies suffer since adding atoms results in a long prediction sequence which increases generation difficulty, while adding leaving groups can only consider the ones in the training set which results in poor generalization. In this paper, we propose a novel end-to-end graph generation model for retrosynthesis prediction, which sequentially identifies the reaction center, generates the synthons, and adds motifs to the synthons to generate reactants. Since chemically meaningful motifs are bigger than atoms and smaller than leaving groups, our method enjoys lower prediction complexity than adding atoms and better generalization than adding leaving groups. Experiments on a benchmark dataset show that the proposed model significantly outperforms previous state-of-the-art algorithms.
DeepNoise: Disentanglement of Experimental Noise from Real Biological Signals based on Fluorescent Microscopy Image Classification via Deep Learning
Sep 13, 2022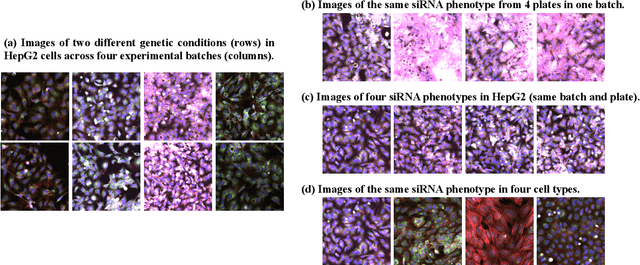
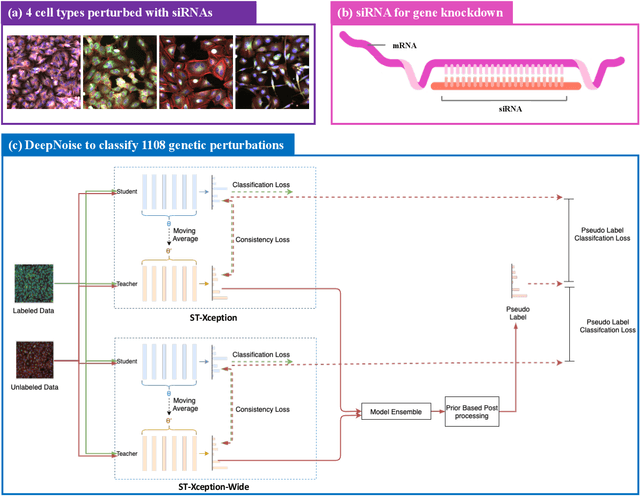
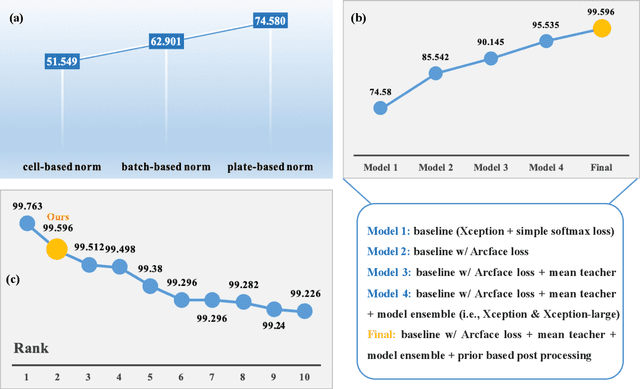
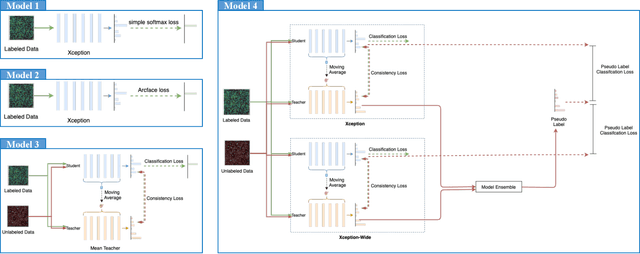
The high-content image-based assay is commonly leveraged for identifying the phenotypic impact of genetic perturbations in biology field. However, a persistent issue remains unsolved during experiments: the interferential technical noise caused by systematic errors (e.g., temperature, reagent concentration, and well location) is always mixed up with the real biological signals, leading to misinterpretation of any conclusion drawn. Here, we show a mean teacher based deep learning model (DeepNoise) that can disentangle biological signals from the experimental noise. Specifically, we aim to classify the phenotypic impact of 1,108 different genetic perturbations screened from 125,510 fluorescent microscopy images, which are totally unrecognizable by human eye. We validate our model by participating in the Recursion Cellular Image Classification Challenge, and our proposed method achieves an extremely high classification score (Acc: 99.596%), ranking the 2nd place among 866 participating groups. This promising result indicates the successful separation of biological and technical factors, which might help decrease the cost of treatment development and expedite the drug discovery process.
ConCL: Concept Contrastive Learning for Dense Prediction Pre-training in Pathology Images
Jul 14, 2022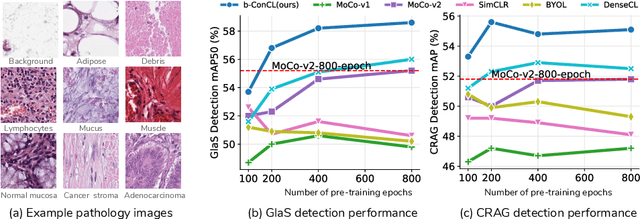
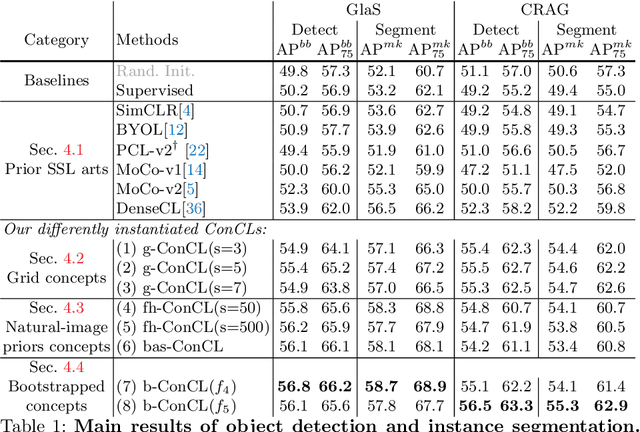
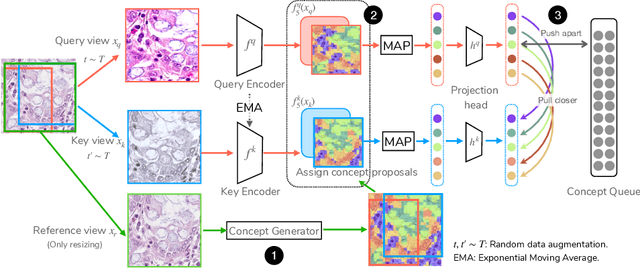
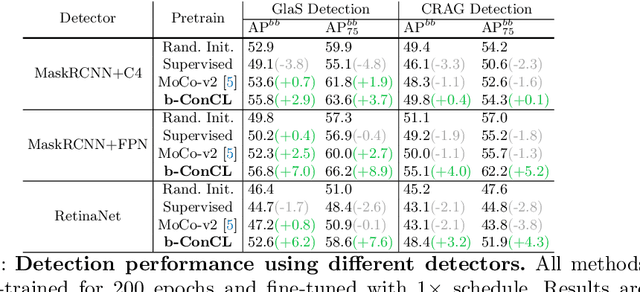
Detectingandsegmentingobjectswithinwholeslideimagesis essential in computational pathology workflow. Self-supervised learning (SSL) is appealing to such annotation-heavy tasks. Despite the extensive benchmarks in natural images for dense tasks, such studies are, unfortunately, absent in current works for pathology. Our paper intends to narrow this gap. We first benchmark representative SSL methods for dense prediction tasks in pathology images. Then, we propose concept contrastive learning (ConCL), an SSL framework for dense pre-training. We explore how ConCL performs with concepts provided by different sources and end up with proposing a simple dependency-free concept generating method that does not rely on external segmentation algorithms or saliency detection models. Extensive experiments demonstrate the superiority of ConCL over previous state-of-the-art SSL methods across different settings. Along our exploration, we distll several important and intriguing components contributing to the success of dense pre-training for pathology images. We hope this work could provide useful data points and encourage the community to conduct ConCL pre-training for problems of interest. Code is available.
Similarity-aware Positive Instance Sampling for Graph Contrastive Pre-training
Jun 23, 2022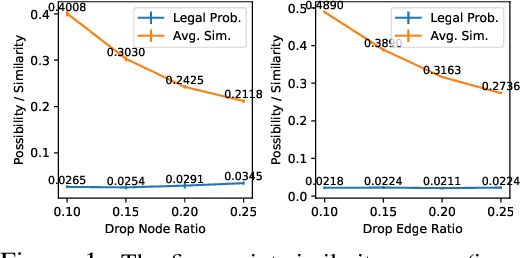
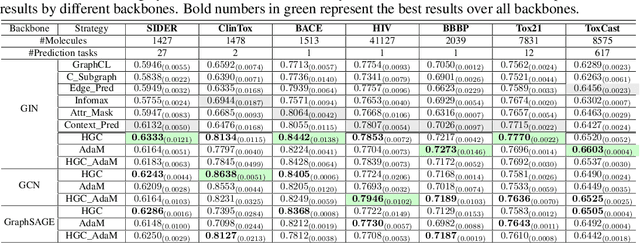

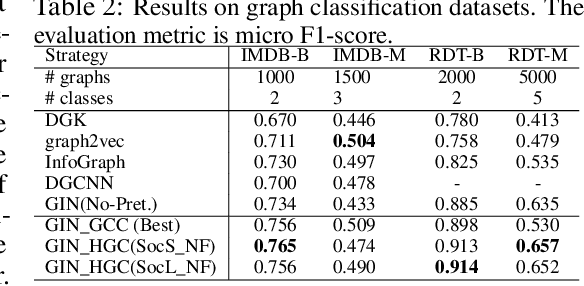
Graph instance contrastive learning has been proved as an effective task for Graph Neural Network (GNN) pre-training. However, one key issue may seriously impede the representative power in existing works: Positive instances created by current methods often miss crucial information of graphs or even yield illegal instances (such as non-chemically-aware graphs in molecular generation). To remedy this issue, we propose to select positive graph instances directly from existing graphs in the training set, which ultimately maintains the legality and similarity to the target graphs. Our selection is based on certain domain-specific pair-wise similarity measurements as well as sampling from a hierarchical graph encoding similarity relations among graphs. Besides, we develop an adaptive node-level pre-training method to dynamically mask nodes to distribute them evenly in the graph. We conduct extensive experiments on $13$ graph classification and node classification benchmark datasets from various domains. The results demonstrate that the GNN models pre-trained by our strategies can outperform those trained-from-scratch models as well as the variants obtained by existing methods.
Seeking Common Ground While Reserving Differences: Multiple Anatomy Collaborative Framework for Undersampled MRI Reconstruction
Jun 16, 2022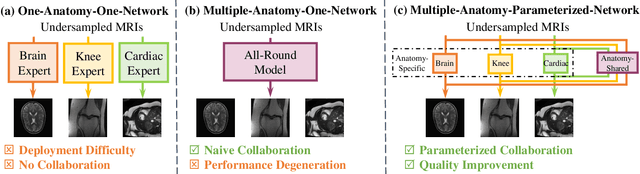
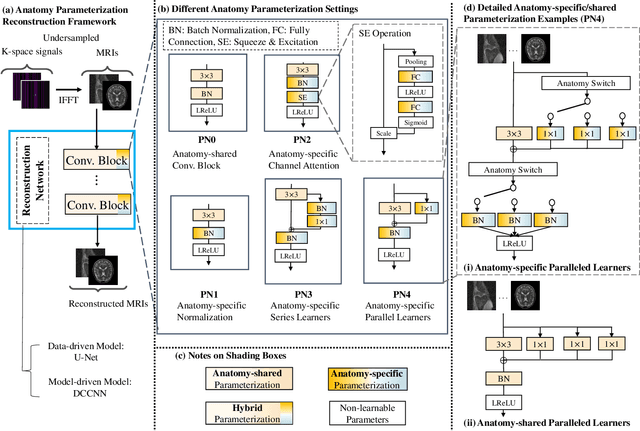
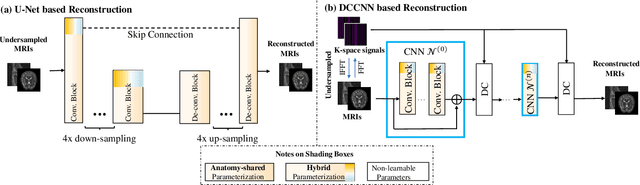
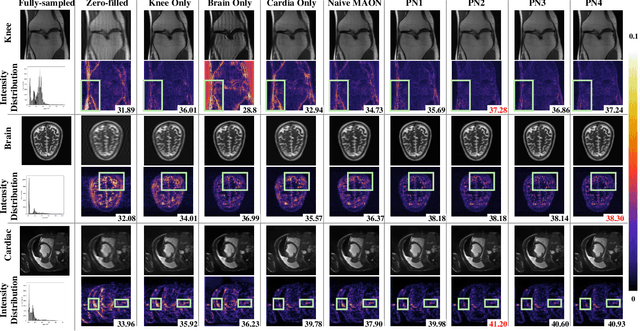
Recently, deep neural networks have greatly advanced undersampled Magnetic Resonance Image (MRI) reconstruction, wherein most studies follow the one-anatomy-one-network fashion, i.e., each expert network is trained and evaluated for a specific anatomy. Apart from inefficiency in training multiple independent models, such convention ignores the shared de-aliasing knowledge across various anatomies which can benefit each other. To explore the shared knowledge, one naive way is to combine all the data from various anatomies to train an all-round network. Unfortunately, despite the existence of the shared de-aliasing knowledge, we reveal that the exclusive knowledge across different anatomies can deteriorate specific reconstruction targets, yielding overall performance degradation. Observing this, in this study, we present a novel deep MRI reconstruction framework with both anatomy-shared and anatomy-specific parameterized learners, aiming to "seek common ground while reserving differences" across different anatomies.Particularly, the primary anatomy-shared learners are exposed to different anatomies to model flourishing shared knowledge, while the efficient anatomy-specific learners are trained with their target anatomy for exclusive knowledge. Four different implementations of anatomy-specific learners are presented and explored on the top of our framework in two MRI reconstruction networks. Comprehensive experiments on brain, knee and cardiac MRI datasets demonstrate that three of these learners are able to enhance reconstruction performance via multiple anatomy collaborative learning.
A Survey of Trustworthy Graph Learning: Reliability, Explainability, and Privacy Protection
May 23, 2022


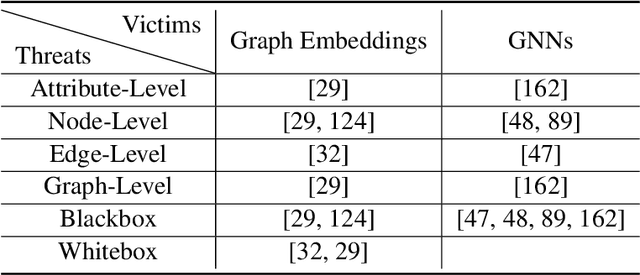
Deep graph learning has achieved remarkable progresses in both business and scientific areas ranging from finance and e-commerce, to drug and advanced material discovery. Despite these progresses, how to ensure various deep graph learning algorithms behave in a socially responsible manner and meet regulatory compliance requirements becomes an emerging problem, especially in risk-sensitive domains. Trustworthy graph learning (TwGL) aims to solve the above problems from a technical viewpoint. In contrast to conventional graph learning research which mainly cares about model performance, TwGL considers various reliability and safety aspects of the graph learning framework including but not limited to robustness, explainability, and privacy. In this survey, we provide a comprehensive review of recent leading approaches in the TwGL field from three dimensions, namely, reliability, explainability, and privacy protection. We give a general categorization for existing work and review typical work for each category. To give further insights for TwGL research, we provide a unified view to inspect previous works and build the connection between them. We also point out some important open problems remaining to be solved in the future developments of TwGL.
DRFLM: Distributionally Robust Federated Learning with Inter-client Noise via Local Mixup
Apr 16, 2022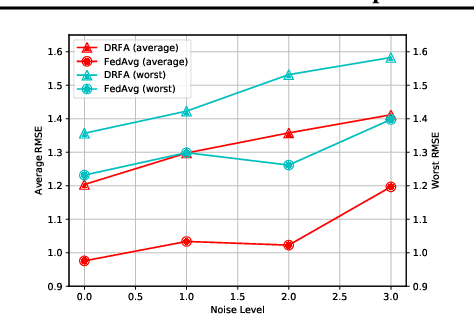
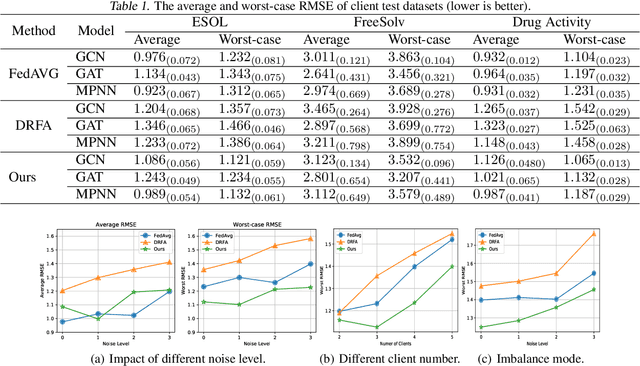
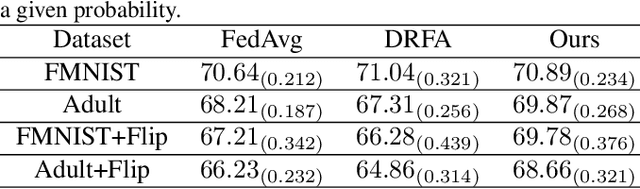
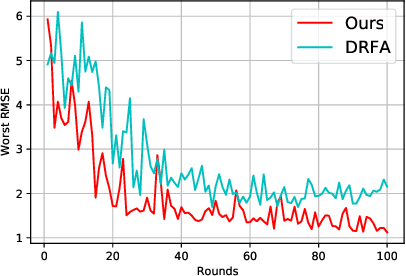
Recently, federated learning has emerged as a promising approach for training a global model using data from multiple organizations without leaking their raw data. Nevertheless, directly applying federated learning to real-world tasks faces two challenges: (1) heterogeneity in the data among different organizations; and (2) data noises inside individual organizations. In this paper, we propose a general framework to solve the above two challenges simultaneously. Specifically, we propose using distributionally robust optimization to mitigate the negative effects caused by data heterogeneity paradigm to sample clients based on a learnable distribution at each iteration. Additionally, we observe that this optimization paradigm is easily affected by data noises inside local clients, which has a significant performance degradation in terms of global model prediction accuracy. To solve this problem, we propose to incorporate mixup techniques into the local training process of federated learning. We further provide comprehensive theoretical analysis including robustness analysis, convergence analysis, and generalization ability. Furthermore, we conduct empirical studies across different drug discovery tasks, such as ADMET property prediction and drug-target affinity prediction.
Pan-cancer computational histopathology reveals tumor mutational burden status through weakly-supervised deep learning
Apr 07, 2022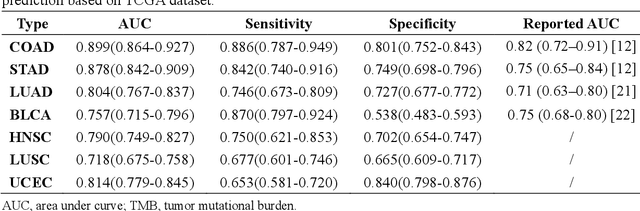
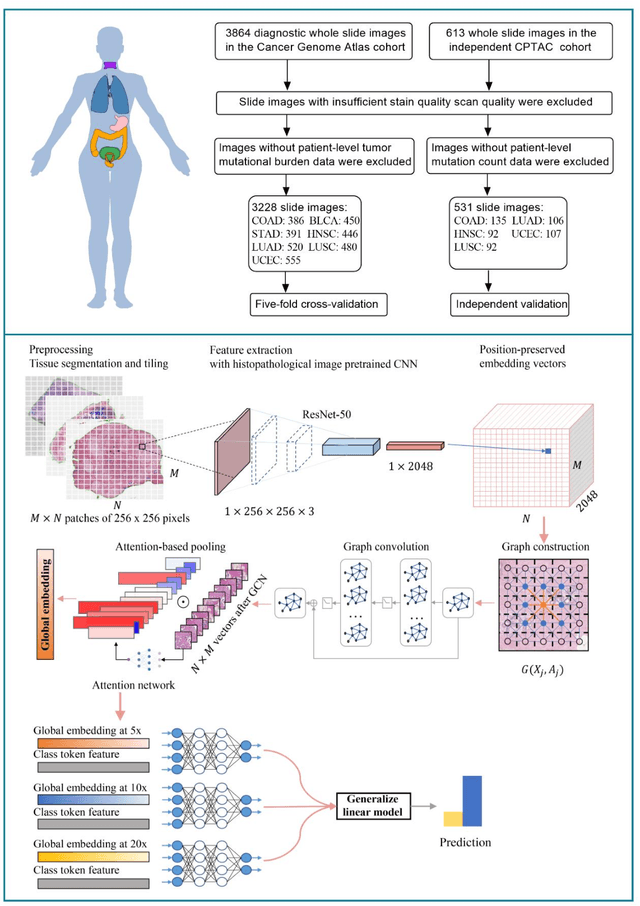
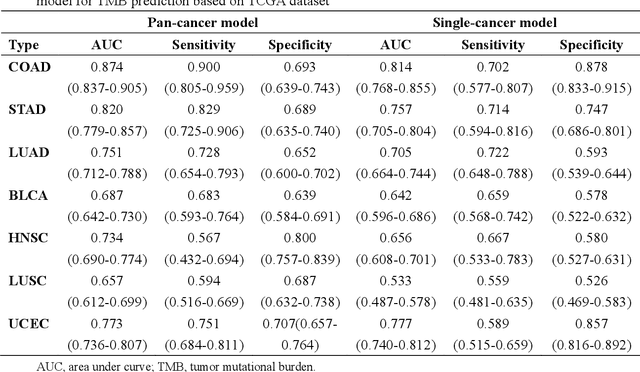
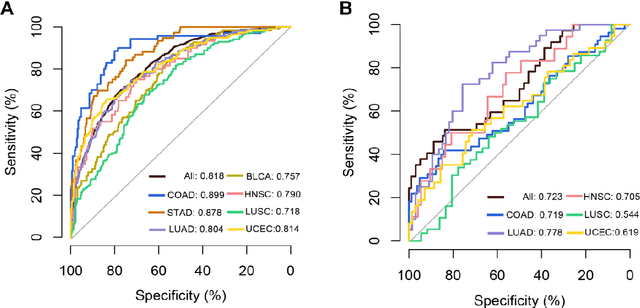
Tumor mutational burden (TMB) is a potential genomic biomarker that can help identify patients who will benefit from immunotherapy across a variety of cancers. We included whole slide images (WSIs) of 3228 diagnostic slides from the Cancer Genome Atlas and 531 WSIs from the Clinical Proteomic Tumor Analysis Consortium for the development and verification of a pan-cancer TMB prediction model (PC-TMB). We proposed a multiscale weakly-supervised deep learning framework for predicting TMB of seven types of tumors based only on routinely used hematoxylin-eosin (H&E)-stained WSIs. PC-TMB achieved a mean area under curve (AUC) of 0.818 (0.804-0.831) in the cross-validation cohort, which was superior to the best single-scale model. In comparison with the state-of-the-art TMB prediction model from previous publications, our multiscale model achieved better performance over previously reported models. In addition, the improvements of PC-TMB over the single-tumor models were also confirmed by the ablation tests on 10x magnification. The PC-TMB algorithm also exhibited good generalization on external validation cohort with AUC of 0.732 (0.683-0.761). PC-TMB possessed a comparable survival-risk stratification performance to the TMB measured by whole exome sequencing, but with low cost and being time-efficient for providing a prognostic biomarker of multiple solid tumors. Moreover, spatial heterogeneity of TMB within tumors was also identified through our PC-TMB, which might enable image-based screening for molecular biomarkers with spatial variation and potential exploring for genotype-spatial heterogeneity relationships.