 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Robustness and Generalization in Multi-Agent Systems: A Case Study on Neural MMO
Aug 30, 2023

We present the results of the second Neural MMO challenge, hosted at IJCAI 2022, which received 1600+ submissions. This competition targets robustness and generalization in multi-agent systems: participants train teams of agents to complete a multi-task objective against opponents not seen during training. The competition combines relatively complex environment design with large numbers of agents in the environment. The top submissions demonstrate strong success on this task using mostly standard reinforcement learning (RL) methods combined with domain-specific engineering. We summarize the competition design and results and suggest that, as an academic community, competitions may be a powerful approach to solving hard problems and establishing a solid benchmark for algorithms. We will open-source our benchmark including the environment wrapper, baselines, a visualization tool, and selected policies for further research.
Towards Complex Real-World Safety Factory Inspection: A High-Quality Dataset for Safety Clothing and Helmet Detection
Jun 03, 2023Safety clothing and helmets play a crucial role in ensuring worker safety at construction sites. Recently, deep learning methods have garnered significant attention in the field of computer vision for their potential to enhance safety and efficiency in various industries. However, limited availability of high-quality datasets has hindered the development of deep learning methods for safety clothing and helmet detection. In this work, we present a large, comprehensive, and realistic high-quality dataset for safety clothing and helmet detection, which was collected from a real-world chemical plant and annotated by professional security inspectors. Our dataset has been compared with several existing open-source datasets, and its effectiveness has been verified applying some classic object detection methods. The results demonstrate that our dataset is more complete and performs better in real-world settings. Furthermore, we have released our deployment code to the public to encourage the adoption of our dataset and improve worker safety. We hope that our efforts will promote the convergence of academic research and industry, ultimately contribute to the betterment of society.
Large Language Models are Zero-Shot Rankers for Recommender Systems
May 15, 2023



Recently, large language models (LLMs) (e.g. GPT-4) have demonstrated impressive general-purpose task-solving abilities, including the potential to approach recommendation tasks. Along this line of research, this work aims to investigate the capacity of LLMs that act as the ranking model for recommender systems. To conduct our empirical study, we first formalize the recommendation problem as a conditional ranking task, considering sequential interaction histories as conditions and the items retrieved by the candidate generation model as candidates. We adopt a specific prompting approach to solving the ranking task by LLMs: we carefully design the prompting template by including the sequential interaction history, the candidate items, and the ranking instruction. We conduct extensive experiments on two widely-used datasets for recommender systems and derive several key findings for the use of LLMs in recommender systems. We show that LLMs have promising zero-shot ranking abilities, even competitive to or better than conventional recommendation models on candidates retrieved by multiple candidate generators. We also demonstrate that LLMs struggle to perceive the order of historical interactions and can be affected by biases like position bias, while these issues can be alleviated via specially designed prompting and bootstrapping strategies. The code to reproduce this work is available at https://github.com/RUCAIBox/LLMRank.
Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach
May 11, 2023



In the past decades, recommender systems have attracted much attention in both research and industry communities, and a large number of studies have been devoted to developing effective recommendation models. Basically speaking, these models mainly learn the underlying user preference from historical behavior data, and then estimate the user-item matching relationships for recommendations. Inspired by the recent progress on large language models (LLMs), we take a different approach to developing the recommendation models, considering recommendation as instruction following by LLMs. The key idea is that the preferences or needs of a user can be expressed in natural language descriptions (called instructions), so that LLMs can understand and further execute the instruction for fulfilling the recommendation task. Instead of using public APIs of LLMs, we instruction tune an open-source LLM (3B Flan-T5-XL), in order to better adapt LLMs to recommender systems. For this purpose, we first design a general instruction format for describing the preference, intention, task form and context of a user in natural language. Then we manually design 39 instruction templates and automatically generate a large amount of user-personalized instruction data (252K instructions) with varying types of preferences and intentions. To demonstrate the effectiveness of our approach, we instantiate the instruction templates into several widely-studied recommendation (or search) tasks, and conduct extensive experiments on these tasks with real-world datasets. Experiment results show that the proposed approach can outperform several competitive baselines, including the powerful GPT-3.5, on these evaluation tasks. Our approach sheds light on developing more user-friendly recommender systems, in which users can freely communicate with the system and obtain more accurate recommendations via natural language instructions.
A Survey of Large Language Models
Apr 27, 2023



Language is essentially a complex, intricate system of human expressions governed by grammatical rules. It poses a significant challenge to develop capable AI algorithms for comprehending and grasping a language. As a major approach, language modeling has been widely studied for language understanding and generation in the past two decades, evolving from statistical language models to neural language models. Recently, pre-trained language models (PLMs) have been proposed by pre-training Transformer models over large-scale corpora, showing strong capabilities in solving various NLP tasks. Since researchers have found that model scaling can lead to performance improvement, they further study the scaling effect by increasing the model size to an even larger size. Interestingly, when the parameter scale exceeds a certain level, these enlarged language models not only achieve a significant performance improvement but also show some special abilities that are not present in small-scale language models. To discriminate the difference in parameter scale, the research community has coined the term large language models (LLM) for the PLMs of significant size. Recently, the research on LLMs has been largely advanced by both academia and industry, and a remarkable progress is the launch of ChatGPT, which has attracted widespread attention from society. The technical evolution of LLMs has been making an important impact on the entire AI community, which would revolutionize the way how we develop and use AI algorithms. In this survey, we review the recent advances of LLMs by introducing the background, key findings, and mainstream techniques. In particular, we focus on four major aspects of LLMs, namely pre-training, adaptation tuning, utilization, and capacity evaluation. Besides, we also summarize the available resources for developing LLMs and discuss the remaining issues for future directions.
Uncertainty-driven Trajectory Truncation for Model-based Offline Reinforcement Learning
Apr 10, 2023



Equipped with the trained environmental dynamics, model-based offline reinforcement learning (RL) algorithms can often successfully learn good policies from fixed-sized datasets, even some datasets with poor quality. Unfortunately, however, it can not be guaranteed that the generated samples from the trained dynamics model are reliable (e.g., some synthetic samples may lie outside of the support region of the static dataset). To address this issue, we propose Trajectory Truncation with Uncertainty (TATU), which adaptively truncates the synthetic trajectory if the accumulated uncertainty along the trajectory is too large. We theoretically show the performance bound of TATU to justify its benefits. To empirically show the advantages of TATU, we first combine it with two classical model-based offline RL algorithms, MOPO and COMBO. Furthermore, we integrate TATU with several off-the-shelf model-free offline RL algorithms, e.g., BCQ. Experimental results on the D4RL benchmark show that TATU significantly improves their performance, often by a large margin.
VPFusion: Towards Robust Vertical Representation Learning for 3D Object Detection
Apr 06, 2023Efficient point cloud representation is a fundamental element of Lidar-based 3D object detection. Recent grid-based detectors usually divide point clouds into voxels or pillars and construct single-stream networks in Bird's Eye View. However, these point cloud encoding paradigms underestimate the point representation in the vertical direction, which cause the loss of semantic or fine-grained information, especially for vertical sensitive objects like pedestrian and cyclists. In this paper, we propose an explicit vertical multi-scale representation learning framework, VPFusion, to combine the complementary information from both voxel and pillar streams. Specifically, VPFusion first builds upon a sparse voxel-pillar-based backbone. The backbone divides point clouds into voxels and pillars, then encodes features with 3D and 2D sparse convolution simultaneously. Next, we introduce the Sparse Fusion Layer (SFL), which establishes a bidirectional pathway for sparse voxel and pillar features to enable the interaction between them. Additionally, we present the Dense Fusion Neck (DFN) to effectively combine the dense feature maps from voxel and pillar branches with multi-scale. Extensive experiments on the large-scale Waymo Open Dataset and nuScenes Dataset demonstrate that VPFusion surpasses the single-stream baselines by a large margin and achieves state-of-the-art performance with real-time inference speed.
GAT-COBO: Cost-Sensitive Graph Neural Network for Telecom Fraud Detection
Mar 29, 2023



Along with the rapid evolution of mobile communication technologies, such as 5G, there has been a drastically increase in telecom fraud, which significantly dissipates individual fortune and social wealth. In recent years, graph mining techniques are gradually becoming a mainstream solution for detecting telecom fraud. However, the graph imbalance problem, caused by the Pareto principle, brings severe challenges to graph data mining. This is a new and challenging problem, but little previous work has been noticed. In this paper, we propose a Graph ATtention network with COst-sensitive BOosting (GAT-COBO) for the graph imbalance problem. First, we design a GAT-based base classifier to learn the embeddings of all nodes in the graph. Then, we feed the embeddings into a well-designed cost-sensitive learner for imbalanced learning. Next, we update the weights according to the misclassification cost to make the model focus more on the minority class. Finally, we sum the node embeddings obtained by multiple cost-sensitive learners to obtain a comprehensive node representation, which is used for the downstream anomaly detection task. Extensive experiments on two real-world telecom fraud detection datasets demonstrate that our proposed method is effective for the graph imbalance problem, outperforming the state-of-the-art GNNs and GNN-based fraud detectors. In addition, our model is also helpful for solving the widespread over-smoothing problem in GNNs. The GAT-COBO code and datasets are available at https://github.com/xxhu94/GAT-COBO.
Recent Advances in RecBole: Extensions with more Practical Considerations
Nov 28, 2022



RecBole has recently attracted increasing attention from the research community. As the increase of the number of users, we have received a number of suggestions and update requests. This motivates us to make some significant improvements on our library, so as to meet the user requirements and contribute to the research community. In order to show the recent update in RecBole, we write this technical report to introduce our latest improvements on RecBole. In general, we focus on the flexibility and efficiency of RecBole in the past few months. More specifically, we have four development targets: (1) more flexible data processing, (2) more efficient model training, (3) more reproducible configurations, and (4) more comprehensive user documentation. Readers can download the above updates at: https://github.com/RUCAIBox/RecBole.
Centimeter-level Positioning by Instantaneous Lidar-aided GNSS Ambiguity Resolution
Apr 26, 2022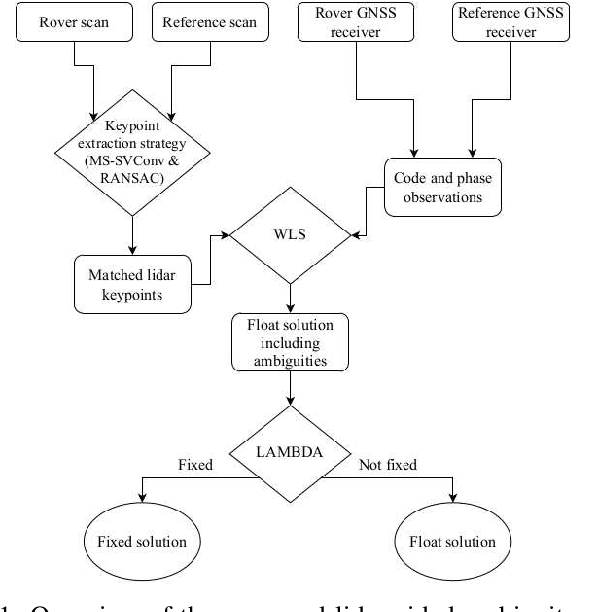
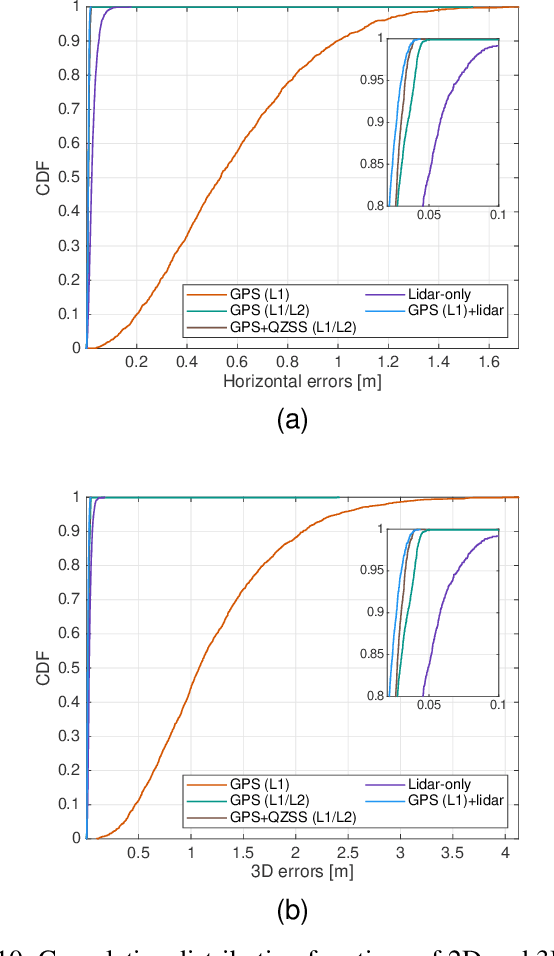
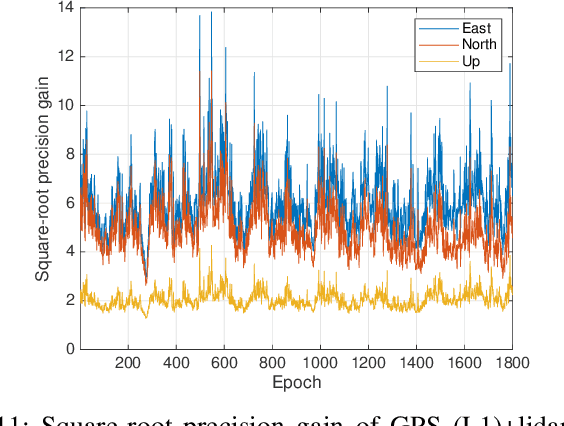
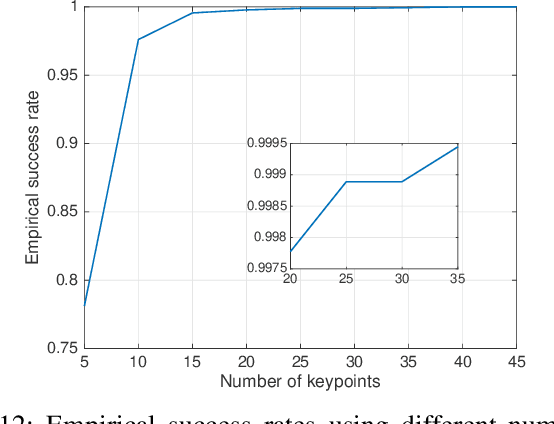
High-precision vehicle positioning is key to the implementation of modern driving systems in urban environments. Global Navigation Satellite System (GNSS) carrier phase measurements can provide millimeter- to centimeter-level positioning, provided that the integer ambiguities are correctly resolved. Abundant code measurements are often used to facilitate integer ambiguity resolution (IAR), however, they suffer from signal blockage and multipath in urban canyons. In this contribution, a lidar-aided instantaneous ambiguity resolution method is proposed. Lidar measurements, in the form of 3D keypoints, are generated by a learning-based point cloud registration method using a pre-built HD map and integrated with GNSS observations in a mixed measurement model to produce precise float solutions, which in turn increase the ambiguity success rate. Closed-form expressions of the ambiguity variance matrix and the associated Ambiguity Dilution of Precision (ADOP) are developed to provide a priori evaluation of such lidar-aided ambiguity resolution performance. Both analytical and experimental results show that the proposed method enables successful instantaneous IAR with limited GNSS satellites and frequencies, leading to centimeter-level vehicle positioning.