 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoCut: Multi-Layer Evolution-Aware Visual Token Compression for Efficient Large Vision-Language Models
Jun 01, 2026Large vision-language models (LVLMs) achieve strong performance on image and video understanding tasks, but their inference efficiency is constrained by the large number of visual tokens produced by vision encoders. Most existing visual token compression methods estimate token importance from attention scores or representation properties at specific layers, overlooking how visual tokens evolve across the vision encoder. Such layer-specific criteria may provide incomplete importance estimates and limit performance preservation after compression. To address this issue, we analyze layer-wise visual token evolution directions and observe that tokens form multiple group evolution directions across vision-encoder layers. Our analysis further shows that informative tokens tend to exhibit persistent deviations from common group evolution directions. Based on this observation, we propose EvoCut, a training-free and attention-free visual token compression method that estimates token importance from multi-layer evolution deviation. Experimental results show that EvoCut can retain only 11.1\% of the visual tokens on LLaVA-1.5-7B while preserving 94.4\% of the average performance, demonstrating its effectiveness in balancing efficiency and accuracy.
SA-CAISR: Stage-Adaptive and Conflict-Aware Incremental Sequential Recommendation
Feb 09, 2026Sequential recommendation (SR) aims to predict a user's next action by learning from their historical interaction sequences. In real-world applications, these models require periodic updates to adapt to new interactions and evolving user preferences. While incremental learning methods facilitate these updates, they face significant challenges. Replay-based approaches incur high memory and computational costs, and regularization-based methods often struggle to discard outdated or conflicting knowledge. To overcome these challenges, we propose SA-CAISR, a Stage-Adaptive and Conflict-Aware Incremental Sequential Recommendation framework. As a buffer-free framework, SA-CAISR operates using only the old model and new data, directly addressing the high costs of replay-based techniques. SA-CAISR introduces a novel Fisher-weighted knowledge-screening mechanism that dynamically identifies outdated knowledge by estimating parameter-level conflicts between the old model and new data, allowing our approach to selectively remove obsolete knowledge while preserving compatible historical patterns. This dynamic balance between stability and adaptability allows our method to achieve a new state-of-the-art performance in incremental SR. Specifically, SA-CAISR improves Recall@20 by 2.0%, MRR@20 by 1.2%, and NDCG@20 by 1.4% on average across datasets, while reducing memory usage by 97.5% and training time by 46.9% compared to the best baselines. This efficiency allows real-world systems to rapidly update user profiles with minimal computational overhead, ensuring more timely and accurate recommendations.
GenCI: Generative Modeling of User Interest Shift via Cohort-based Intent Learning for CTR Prediction
Jan 26, 2026Click-through rate (CTR) prediction plays a pivotal role in online advertising and recommender systems. Despite notable progress in modeling user preferences from historical behaviors, two key challenges persist. First, exsiting discriminative paradigms focus on matching candidates to user history, often overfitting to historically dominant features and failing to adapt to rapid interest shifts. Second, a critical information chasm emerges from the point-wise ranking paradigm. By scoring each candidate in isolation, CTR models discard the rich contextual signal implied by the recalled set as a whole, leading to a misalignment where long-term preferences often override the user's immediate, evolving intent. To address these issues, we propose GenCI, a generative user intent framework that leverages semantic interest cohorts to model dynamic user preferences for CTR prediction. The framework first employs a generative model, trained with a next-item prediction (NTP) objective, to proactively produce candidate interest cohorts. These cohorts serve as explicit, candidate-agnostic representations of a user's immediate intent. A hierarchical candidate-aware network then injects this rich contextual signal into the ranking stage, refining them with cross-attention to align with both user history and the target item. The entire model is trained end-to-end, creating a more aligned and effective CTR prediction pipeline. Extensive experiments on three widely used datasets demonstrate the effectiveness of our approach.
Entropy-Guided Token Dropout: Training Autoregressive Language Models with Limited Domain Data
Dec 29, 2025As access to high-quality, domain-specific data grows increasingly scarce, multi-epoch training has become a practical strategy for adapting large language models (LLMs). However, autoregressive models often suffer from performance degradation under repeated data exposure, where overfitting leads to a marked decline in model capability. Through empirical analysis, we trace this degradation to an imbalance in learning dynamics: predictable, low-entropy tokens are learned quickly and come to dominate optimization, while the model's ability to generalize on high-entropy tokens deteriorates with continued training. To address this, we introduce EntroDrop, an entropy-guided token dropout method that functions as structured data regularization. EntroDrop selectively masks low-entropy tokens during training and employs a curriculum schedule to adjust regularization strength in alignment with training progress. Experiments across model scales from 0.6B to 8B parameters show that EntroDrop consistently outperforms standard regularization baselines and maintains robust performance throughout extended multi-epoch training. These findings underscore the importance of aligning regularization with token-level learning dynamics when training on limited data. Our approach offers a promising pathway toward more effective adaptation of LLMs in data-constrained domains.
Slow Thinking for Sequential Recommendation
Apr 13, 2025To develop effective sequential recommender systems, numerous methods have been proposed to model historical user behaviors. Despite the effectiveness, these methods share the same fast thinking paradigm. That is, for making recommendations, these methods typically encodes user historical interactions to obtain user representations and directly match these representations with candidate item representations. However, due to the limited capacity of traditional lightweight recommendation models, this one-step inference paradigm often leads to suboptimal performance. To tackle this issue, we present a novel slow thinking recommendation model, named STREAM-Rec. Our approach is capable of analyzing historical user behavior, generating a multi-step, deliberative reasoning process, and ultimately delivering personalized recommendations. In particular, we focus on two key challenges: (1) identifying the suitable reasoning patterns in recommender systems, and (2) exploring how to effectively stimulate the reasoning capabilities of traditional recommenders. To this end, we introduce a three-stage training framework. In the first stage, the model is pretrained on large-scale user behavior data to learn behavior patterns and capture long-range dependencies. In the second stage, we design an iterative inference algorithm to annotate suitable reasoning traces by progressively refining the model predictions. This annotated data is then used to fine-tune the model. Finally, in the third stage, we apply reinforcement learning to further enhance the model generalization ability. Extensive experiments validate the effectiveness of our proposed method.
Universal Item Tokenization for Transferable Generative Recommendation
Apr 06, 2025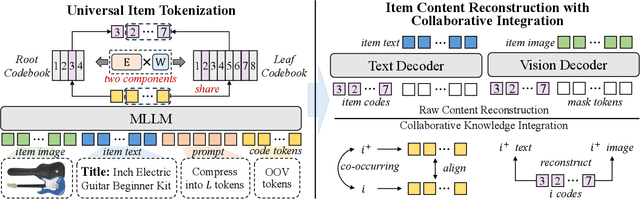
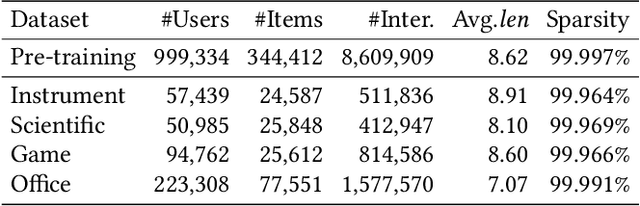
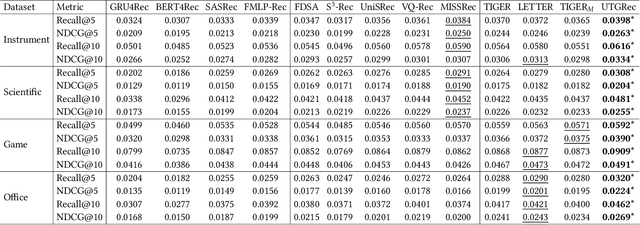
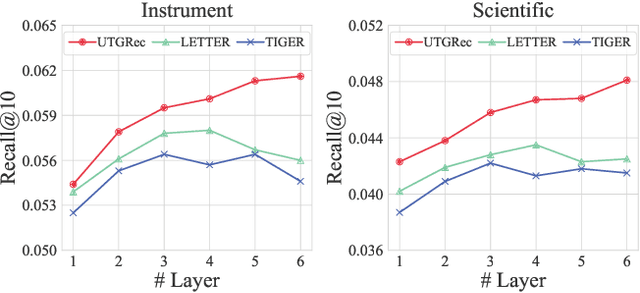
Recently, generative recommendation has emerged as a promising paradigm, attracting significant research attention. The basic framework involves an item tokenizer, which represents each item as a sequence of codes serving as its identifier, and a generative recommender that predicts the next item by autoregressively generating the target item identifier. However, in existing methods, both the tokenizer and the recommender are typically domain-specific, limiting their ability for effective transfer or adaptation to new domains. To this end, we propose UTGRec, a Universal item Tokenization approach for transferable Generative Recommendation. Specifically, we design a universal item tokenizer for encoding rich item semantics by adapting a multimodal large language model (MLLM). By devising tree-structured codebooks, we discretize content representations into corresponding codes for item tokenization. To effectively learn the universal item tokenizer on multiple domains, we introduce two key techniques in our approach. For raw content reconstruction, we employ dual lightweight decoders to reconstruct item text and images from discrete representations to capture general knowledge embedded in the content. For collaborative knowledge integration, we assume that co-occurring items are similar and integrate collaborative signals through co-occurrence alignment and reconstruction. Finally, we present a joint learning framework to pre-train and adapt the transferable generative recommender across multiple domains. Extensive experiments on four public datasets demonstrate the superiority of UTGRec compared to both traditional and generative recommendation baselines.
Computationally-Efficient Linear Periodically Time-Variant Digital PLL Modeling Using Conversion Matrices and Uncorrelated Upsampling
Jan 26, 2024



This paper introduces a conversion matrix method for linear periodically time-variant (LPTV) digital phase-locked loop (DPLL) phase noise modeling that offers precise and computationally efficient results to enable rapid design iteration and optimization. Unlike many previous studies, which either assume linear time-invariance (LTI) and therefore overlook phase noise aliasing effects, or solve LPTV systems with noise folding and multiple sampling rate conversions that heightens modeling and computational complexity, the proposed conversion matrix method allows the designer to represent the LPTV systems using intuitive LTI-like transfer functions with excellent accuracy. Additionally, computational efficiency is improved through the uncorrelated upsampling method, which eliminates the need to consider beat frequency of noise sources with different sampling rates. The proposed algorithm is applied to modeling a DPLL with time-varying proportional loop gain, and the modeling accuracy is validated with Simulink transient simulations.
Cross Domain LifeLong Sequential Modeling for Online Click-Through Rate Prediction
Dec 11, 2023



Deep neural networks (DNNs) that incorporated lifelong sequential modeling (LSM) have brought great success to recommendation systems in various social media platforms. While continuous improvements have been made in domain-specific LSM, limited work has been done in cross-domain LSM, which considers modeling of lifelong sequences of both target domain and source domain. In this paper, we propose Lifelong Cross Network (LCN) to incorporate cross-domain LSM to improve the click-through rate (CTR) prediction in the target domain. The proposed LCN contains a LifeLong Attention Pyramid (LAP) module that comprises of three levels of cascaded attentions to effectively extract interest representations with respect to the candidate item from lifelong sequences. We also propose Cross Representation Production (CRP) module to enforce additional supervision on the learning and alignment of cross-domain representations so that they can be better reused on learning of the CTR prediction in the target domain. We conducted extensive experiments on WeChat Channels industrial dataset as well as on benchmark dataset. Results have revealed that the proposed LCN outperforms existing work in terms of both prediction accuracy and online performance.
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Nov 28, 2023



Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
Scaling Law of Large Sequential Recommendation Models
Nov 19, 2023Scaling of neural networks has recently shown great potential to improve the model capacity in various fields. Specifically, model performance has a power-law relationship with model size or data size, which provides important guidance for the development of large-scale models. However, there is still limited understanding on the scaling effect of user behavior models in recommender systems, where the unique data characteristics (e.g. data scarcity and sparsity) pose new challenges to explore the scaling effect in recommendation tasks. In this work, we focus on investigating the scaling laws in large sequential recommendation models. Specially, we consider a pure ID-based task formulation, where the interaction history of a user is formatted as a chronological sequence of item IDs. We don't incorporate any side information (e.g. item text), because we would like to explore how scaling law holds from the perspective of user behavior. With specially improved strategies, we scale up the model size to 0.8B parameters, making it feasible to explore the scaling effect in a diverse range of model sizes. As the major findings, we empirically show that scaling law still holds for these trained models, even in data-constrained scenarios. We then fit the curve for scaling law, and successfully predict the test loss of the two largest tested model scales. Furthermore, we examine the performance advantage of scaling effect on five challenging recommendation tasks, considering the unique issues (e.g. cold start, robustness, long-term preference) in recommender systems. We find that scaling up the model size can greatly boost the performance on these challenging tasks, which again verifies the benefits of large recommendation models.