 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuDiff Agent: A Governed AI Workflow for Single-Crystal Neutron Crystallography
Feb 18, 2026Large-scale facilities increasingly face analysis and reporting latency as the limiting step in scientific throughput, particularly for structurally and magnetically complex samples that require iterative reduction, integration, refinement, and validation. To improve time-to-result and analysis efficiency, NeuDiff Agent is introduced as a governed, tool-using AI workflow for TOPAZ at the Spallation Neutron Source that takes instrument data products through reduction, integration, refinement, and validation to a validated crystal structure and a publication-ready CIF. NeuDiff Agent executes this established pipeline under explicit governance by restricting actions to allowlisted tools, enforcing fail-closed verification gates at key workflow boundaries, and capturing complete provenance for inspection, auditing, and controlled replay. Performance is assessed using a fixed prompt protocol and repeated end-to-end runs with two large language model backends, with user and machine time partitioned and intervention burden and recovery behaviors quantified under gating. In a reference-case benchmark, NeuDiff Agent reduces wall time from 435 minutes (manual) to 86.5(4.7) to 94.4(3.5) minutes (4.6-5.0x faster) while producing a validated CIF with no checkCIF level A or B alerts. These results establish a practical route to deploy agentic AI in facility crystallography while preserving traceability and publication-facing validation requirements.
Joint Masked Reconstruction and Contrastive Learning for Mining Interactions Between Proteins
Mar 06, 2025

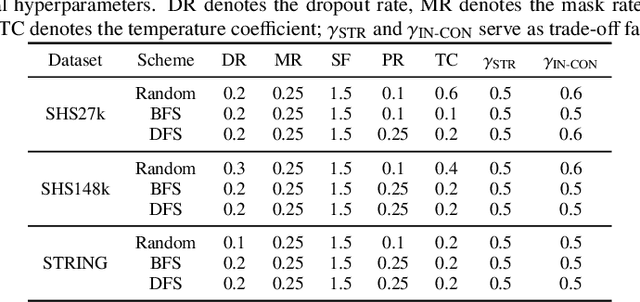

Protein-protein interaction (PPI) prediction is an instrumental means in elucidating the mechanisms underlying cellular operations, holding significant practical implications for the realms of pharmaceutical development and clinical treatment. Presently, the majority of research methods primarily concentrate on the analysis of amino acid sequences, while investigations predicated on protein structures remain in the nascent stages of exploration. Despite the emergence of several structure-based algorithms in recent years, these are still confronted with inherent challenges: (1) the extraction of intrinsic structural information of proteins typically necessitates the expenditure of substantial computational resources; (2) these models are overly reliant on seen protein data, struggling to effectively unearth interaction cues between unknown proteins. To further propel advancements in this domain, this paper introduces a novel PPI prediction method jointing masked reconstruction and contrastive learning, termed JmcPPI. This methodology dissects the PPI prediction task into two distinct phases: during the residue structure encoding phase, JmcPPI devises two feature reconstruction tasks and employs graph attention mechanism to capture structural information between residues; during the protein interaction inference phase, JmcPPI perturbs the original PPI graph and employs a multi-graph contrastive learning strategy to thoroughly mine extrinsic interaction information of novel proteins. Extensive experiments conducted on three widely utilized PPI datasets demonstrate that JmcPPI surpasses existing optimal baseline models across various data partition schemes. The associated code can be accessed via https://github.com/lijfrank-open/JmcPPI.
Tracing Intricate Cues in Dialogue: Joint Graph Structure and Sentiment Dynamics for Multimodal Emotion Recognition
Jul 31, 2024



Multimodal emotion recognition in conversation (MERC) has garnered substantial research attention recently. Existing MERC methods face several challenges: (1) they fail to fully harness direct inter-modal cues, possibly leading to less-than-thorough cross-modal modeling; (2) they concurrently extract information from the same and different modalities at each network layer, potentially triggering conflicts from the fusion of multi-source data; (3) they lack the agility required to detect dynamic sentimental changes, perhaps resulting in inaccurate classification of utterances with abrupt sentiment shifts. To address these issues, a novel approach named GraphSmile is proposed for tracking intricate emotional cues in multimodal dialogues. GraphSmile comprises two key components, i.e., GSF and SDP modules. GSF ingeniously leverages graph structures to alternately assimilate inter-modal and intra-modal emotional dependencies layer by layer, adequately capturing cross-modal cues while effectively circumventing fusion conflicts. SDP is an auxiliary task to explicitly delineate the sentiment dynamics between utterances, promoting the model's ability to distinguish sentimental discrepancies. Furthermore, GraphSmile is effortlessly applied to multimodal sentiment analysis in conversation (MSAC), forging a unified multimodal affective model capable of executing MERC and MSAC tasks. Empirical results on multiple benchmarks demonstrate that GraphSmile can handle complex emotional and sentimental patterns, significantly outperforming baseline models.
InstructERC: Reforming Emotion Recognition in Conversation with a Retrieval Multi-task LLMs Framework
Sep 22, 2023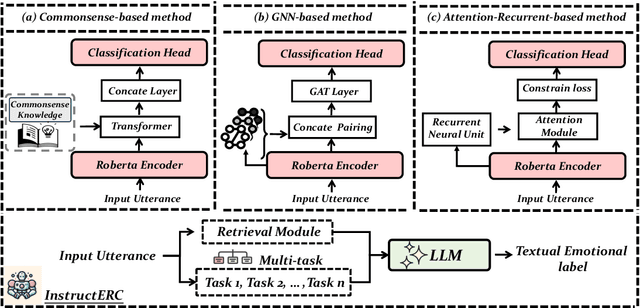



The development of emotion recognition in dialogue (ERC) has been consistently hindered by the complexity of pipeline designs, leading to ERC models that often overfit to specific datasets and dialogue patterns. In this study, we propose a novel approach, namely InstructERC, to reformulates the ERC task from a discriminative framework to a generative framework based on Large Language Models (LLMs) . InstructERC has two significant contributions: Firstly, InstructERC introduces a simple yet effective retrieval template module, which helps the model explicitly integrate multi-granularity dialogue supervision information by concatenating the historical dialog content, label statement, and emotional domain demonstrations with high semantic similarity. Furthermore, we introduce two additional emotion alignment tasks, namely speaker identification and emotion prediction tasks, to implicitly model the dialogue role relationships and future emotional tendencies in conversations. Our LLM-based plug-and-play plugin framework significantly outperforms all previous models and achieves comprehensive SOTA on three commonly used ERC datasets. Extensive analysis of parameter-efficient and data-scaling experiments provide empirical guidance for applying InstructERC in practical scenarios. Our code will be released after blind review.
Watch the Speakers: A Hybrid Continuous Attribution Network for Emotion Recognition in Conversation With Emotion Disentanglement
Sep 19, 2023Emotion Recognition in Conversation (ERC) has attracted widespread attention in the natural language processing field due to its enormous potential for practical applications. Existing ERC methods face challenges in achieving generalization to diverse scenarios due to insufficient modeling of context, ambiguous capture of dialogue relationships and overfitting in speaker modeling. In this work, we present a Hybrid Continuous Attributive Network (HCAN) to address these issues in the perspective of emotional continuation and emotional attribution. Specifically, HCAN adopts a hybrid recurrent and attention-based module to model global emotion continuity. Then a novel Emotional Attribution Encoding (EAE) is proposed to model intra- and inter-emotional attribution for each utterance. Moreover, aiming to enhance the robustness of the model in speaker modeling and improve its performance in different scenarios, A comprehensive loss function emotional cognitive loss $\mathcal{L}_{\rm EC}$ is proposed to alleviate emotional drift and overcome the overfitting of the model to speaker modeling. Our model achieves state-of-the-art performance on three datasets, demonstrating the superiority of our work. Another extensive comparative experiments and ablation studies on three benchmarks are conducted to provided evidence to support the efficacy of each module. Further exploration of generalization ability experiments shows the plug-and-play nature of the EAE module in our method.
Simple Model Also Works: A Novel Emotion Recognition Network in Textual Conversation Based on Curriculum Learning Strategy
Aug 12, 2023



Emotion Recognition in Conversation (ERC) has emerged as a research hotspot in domains such as conversational robots and question-answer systems. How to efficiently and adequately retrieve contextual emotional cues has been one of the key challenges in the ERC task. Existing efforts do not fully model the context and employ complex network structures, resulting in excessive computational resource overhead without substantial performance improvement. In this paper, we propose a novel Emotion Recognition Network based on Curriculum Learning strategy (ERNetCL). The proposed ERNetCL primarily consists of Temporal Encoder (TE), Spatial Encoder (SE), and Curriculum Learning (CL) loss. We utilize TE and SE to combine the strengths of previous methods in a simplistic manner to efficiently capture temporal and spatial contextual information in the conversation. To simulate the way humans learn curriculum from easy to hard, we apply the idea of CL to the ERC task to progressively optimize the network parameters of ERNetCL. At the beginning of training, we assign lower learning weights to difficult samples. As the epoch increases, the learning weights for these samples are gradually raised. Extensive experiments on four datasets exhibit that our proposed method is effective and dramatically beats other baseline models.
CFN-ESA: A Cross-Modal Fusion Network with Emotion-Shift Awareness for Dialogue Emotion Recognition
Jul 28, 2023



Multimodal Emotion Recognition in Conversation (ERC) has garnered growing attention from research communities in various fields. In this paper, we propose a cross-modal fusion network with emotion-shift awareness (CFN-ESA) for ERC. Extant approaches employ each modality equally without distinguishing the amount of emotional information, rendering it hard to adequately extract complementary and associative information from multimodal data. To cope with this problem, in CFN-ESA, textual modalities are treated as the primary source of emotional information, while visual and acoustic modalities are taken as the secondary sources. Besides, most multimodal ERC models ignore emotion-shift information and overfocus on contextual information, leading to the failure of emotion recognition under emotion-shift scenario. We elaborate an emotion-shift module to address this challenge. CFN-ESA mainly consists of the unimodal encoder (RUME), cross-modal encoder (ACME), and emotion-shift module (LESM). RUME is applied to extract conversation-level contextual emotional cues while pulling together the data distributions between modalities; ACME is utilized to perform multimodal interaction centered on textual modality; LESM is used to model emotion shift and capture related information, thereby guide the learning of the main task. Experimental results demonstrate that CFN-ESA can effectively promote performance for ERC and remarkably outperform the state-of-the-art models.
A Dual-Stream Recurrence-Attention Network with Global-Local Awareness for Emotion Recognition in Textual Dialogue
Jul 02, 2023



In real-world dialogue systems, the ability to understand the user's emotions and interact anthropomorphically is of great significance. Emotion Recognition in Conversation (ERC) is one of the key ways to accomplish this goal and has attracted growing attention. How to model the context in a conversation is a central aspect and a major challenge of ERC tasks. Most existing approaches are generally unable to capture both global and local contextual information efficiently, and their network structures are too complex to design. For this reason, in this work, we propose a straightforward Dual-stream Recurrence-Attention Network (DualRAN) based on Recurrent Neural Network (RNN) and Multi-head ATtention network (MAT). The proposed model eschews the complex network structure of current methods and focuses on combining recurrence-based methods with attention-based methods. DualRAN is a dual-stream structure mainly consisting of local- and global-aware modules, modeling a conversation from distinct perspectives. To achieve the local-aware module, we extend the structure of RNN, thus enhancing the expressive capability of the network. In addition, we develop two single-stream network variants for DualRAN, i.e., SingleRANv1 and SingleRANv2. We conduct extensive experiments on four widely used benchmark datasets, and the results reveal that the proposed model outshines all baselines. Ablation studies further demonstrate the effectiveness of each component.
Towards Complex Real-World Safety Factory Inspection: A High-Quality Dataset for Safety Clothing and Helmet Detection
Jun 03, 2023Safety clothing and helmets play a crucial role in ensuring worker safety at construction sites. Recently, deep learning methods have garnered significant attention in the field of computer vision for their potential to enhance safety and efficiency in various industries. However, limited availability of high-quality datasets has hindered the development of deep learning methods for safety clothing and helmet detection. In this work, we present a large, comprehensive, and realistic high-quality dataset for safety clothing and helmet detection, which was collected from a real-world chemical plant and annotated by professional security inspectors. Our dataset has been compared with several existing open-source datasets, and its effectiveness has been verified applying some classic object detection methods. The results demonstrate that our dataset is more complete and performs better in real-world settings. Furthermore, we have released our deployment code to the public to encourage the adoption of our dataset and improve worker safety. We hope that our efforts will promote the convergence of academic research and industry, ultimately contribute to the betterment of society.
EmotionIC: Emotional Inertia and Contagion-driven Dependency Modelling for Emotion Recognition in Conversation
Mar 22, 2023Emotion Recognition in Conversation (ERC) has attracted growing attention in recent years as a result of the advancement and implementation of human-computer interface technologies. However, previous approaches to modeling global and local context dependencies lost the diversity of dependency information and do not take the context dependency into account at the classification level. In this paper, we propose a novel approach to dependency modeling driven by Emotional Inertia and Contagion (EmotionIC) for conversational emotion recognition at the feature extraction and classification levels. At the feature extraction level, our designed Identity Masked Multi-head Attention (IM-MHA) captures the identity-based long-distant context in the dialogue to contain the diverse influence of different participants and construct the global emotional atmosphere, while the devised Dialogue-based Gate Recurrent Unit (DialogGRU) that aggregates the emotional tendencies of dyadic dialogue is applied to refine the contextual features with inter- and intra-speaker dependencies. At the classification level, by introducing skip connections in Conditional Random Field (CRF), we elaborate the Skip-chain CRF (SkipCRF) to capture the high-order dependencies within and between speakers, and to emulate the emotional flow of distant participants. Experimental results show that our method can significantly outperform the state-of-the-art models on four benchmark datasets. The ablation studies confirm that our modules can effectively model emotional inertia and contagion.