 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonizing Base and Novel Classes: A Class-Contrastive Approach for Generalized Few-Shot Segmentation
Mar 24, 2023



Current methods for few-shot segmentation (FSSeg) have mainly focused on improving the performance of novel classes while neglecting the performance of base classes. To overcome this limitation, the task of generalized few-shot semantic segmentation (GFSSeg) has been introduced, aiming to predict segmentation masks for both base and novel classes. However, the current prototype-based methods do not explicitly consider the relationship between base and novel classes when updating prototypes, leading to a limited performance in identifying true categories. To address this challenge, we propose a class contrastive loss and a class relationship loss to regulate prototype updates and encourage a large distance between prototypes from different classes, thus distinguishing the classes from each other while maintaining the performance of the base classes. Our proposed approach achieves new state-of-the-art performance for the generalized few-shot segmentation task on PASCAL VOC and MS COCO datasets.
CbwLoss: Constrained Bidirectional Weighted Loss for Self-supervised Learning of Depth and Pose
Dec 12, 2022Photometric differences are widely used as supervision signals to train neural networks for estimating depth and camera pose from unlabeled monocular videos. However, this approach is detrimental for model optimization because occlusions and moving objects in a scene violate the underlying static scenario assumption. In addition, pixels in textureless regions or less discriminative pixels hinder model training. To solve these problems, in this paper, we deal with moving objects and occlusions utilizing the difference of the flow fields and depth structure generated by affine transformation and view synthesis, respectively. Secondly, we mitigate the effect of textureless regions on model optimization by measuring differences between features with more semantic and contextual information without adding networks. In addition, although the bidirectionality component is used in each sub-objective function, a pair of images are reasoned about only once, which helps reduce overhead. Extensive experiments and visual analysis demonstrate the effectiveness of the proposed method, which outperform existing state-of-the-art self-supervised methods under the same conditions and without introducing additional auxiliary information.
$\textbf{P$^2$A}$: A Dataset and Benchmark for Dense Action Detection from Table Tennis Match Broadcasting Videos
Jul 26, 2022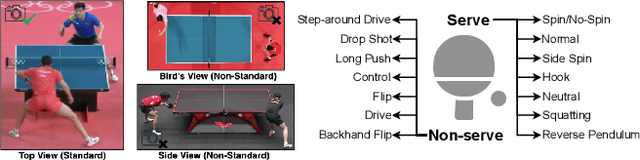
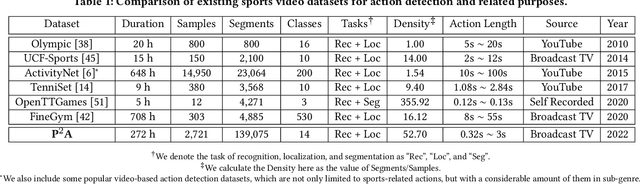

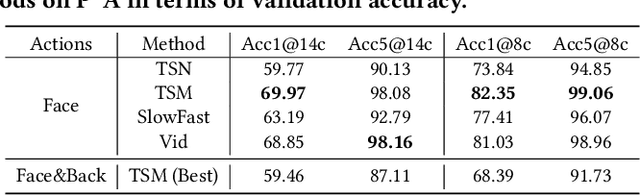
While deep learning has been widely used for video analytics, such as video classification and action detection, dense action detection with fast-moving subjects from sports videos is still challenging. In this work, we release yet another sports video dataset $\textbf{P$^2$A}$ for $\underline{P}$ing $\underline{P}$ong-$\underline{A}$ction detection, which consists of 2,721 video clips collected from the broadcasting videos of professional table tennis matches in World Table Tennis Championships and Olympiads. We work with a crew of table tennis professionals and referees to obtain fine-grained action labels (in 14 classes) for every ping-pong action that appeared in the dataset and formulate two sets of action detection problems - action localization and action recognition. We evaluate a number of commonly-seen action recognition (e.g., TSM, TSN, Video SwinTransformer, and Slowfast) and action localization models (e.g., BSN, BSN++, BMN, TCANet), using $\textbf{P$^2$A}$ for both problems, under various settings. These models can only achieve 48% area under the AR-AN curve for localization and 82% top-one accuracy for recognition since the ping-pong actions are dense with fast-moving subjects but broadcasting videos are with only 25 FPS. The results confirm that $\textbf{P$^2$A}$ is still a challenging task and can be used as a benchmark for action detection from videos.
Personalized Diagnostic Tool for Thyroid Cancer Classification using Multi-view Ultrasound
Jul 01, 2022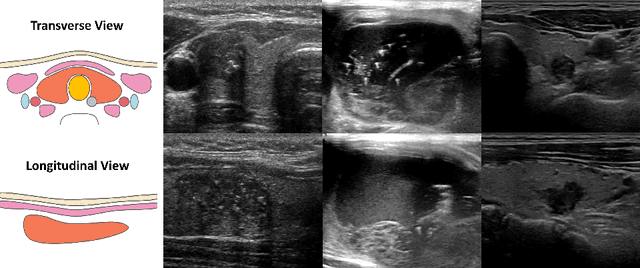
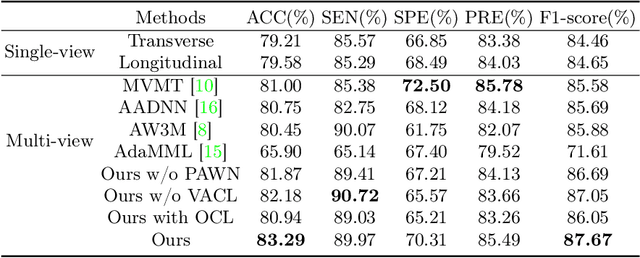
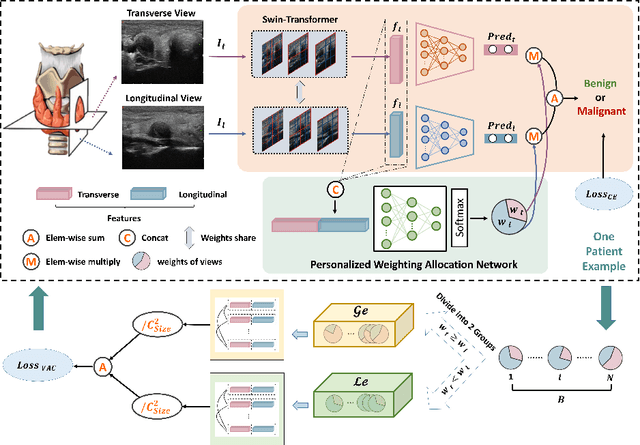
Over the past decades, the incidence of thyroid cancer has been increasing globally. Accurate and early diagnosis allows timely treatment and helps to avoid over-diagnosis. Clinically, a nodule is commonly evaluated from both transverse and longitudinal views using thyroid ultrasound. However, the appearance of the thyroid gland and lesions can vary dramatically across individuals. Identifying key diagnostic information from both views requires specialized expertise. Furthermore, finding an optimal way to integrate multi-view information also relies on the experience of clinicians and adds further difficulty to accurate diagnosis. To address these, we propose a personalized diagnostic tool that can customize its decision-making process for different patients. It consists of a multi-view classification module for feature extraction and a personalized weighting allocation network that generates optimal weighting for different views. It is also equipped with a self-supervised view-aware contrastive loss to further improve the model robustness towards different patient groups. Experimental results show that the proposed framework can better utilize multi-view information and outperform the competing methods.
A Survey on Video Action Recognition in Sports: Datasets, Methods and Applications
Jun 02, 2022
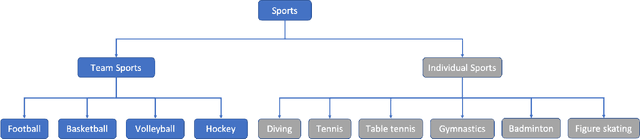
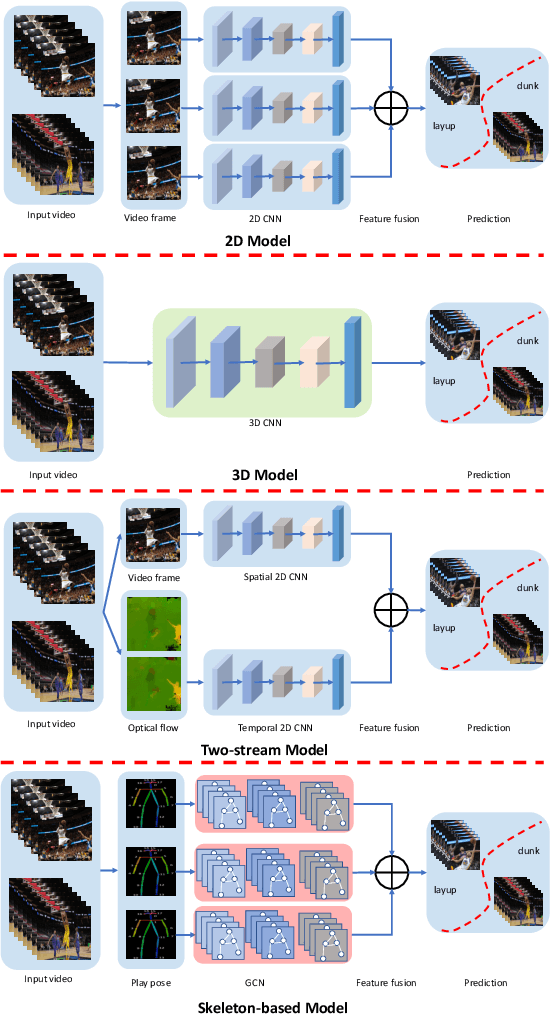
To understand human behaviors, action recognition based on videos is a common approach. Compared with image-based action recognition, videos provide much more information. Reducing the ambiguity of actions and in the last decade, many works focused on datasets, novel models and learning approaches have improved video action recognition to a higher level. However, there are challenges and unsolved problems, in particular in sports analytics where data collection and labeling are more sophisticated, requiring sport professionals to annotate data. In addition, the actions could be extremely fast and it becomes difficult to recognize them. Moreover, in team sports like football and basketball, one action could involve multiple players, and to correctly recognize them, we need to analyse all players, which is relatively complicated. In this paper, we present a survey on video action recognition for sports analytics. We introduce more than ten types of sports, including team sports, such as football, basketball, volleyball, hockey and individual sports, such as figure skating, gymnastics, table tennis, tennis, diving and badminton. Then we compare numerous existing frameworks for sports analysis to present status quo of video action recognition in both team sports and individual sports. Finally, we discuss the challenges and unsolved problems in this area and to facilitate sports analytics, we develop a toolbox using PaddlePaddle, which supports football, basketball, table tennis and figure skating action recognition.
Structure Unbiased Adversarial Model for Medical Image Segmentation
May 26, 2022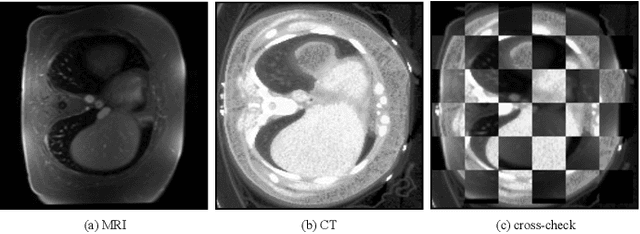
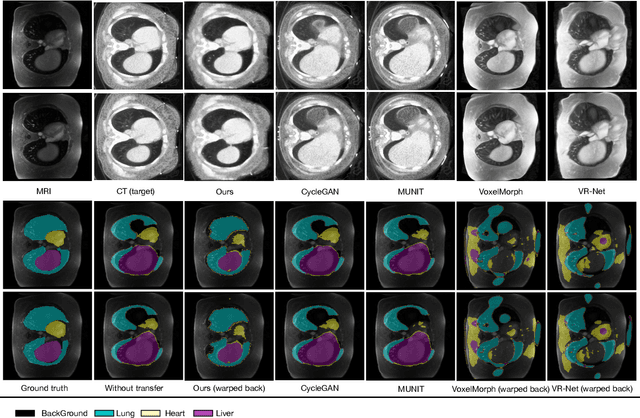
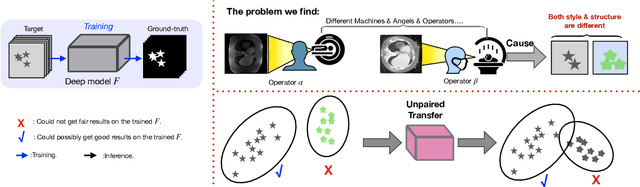
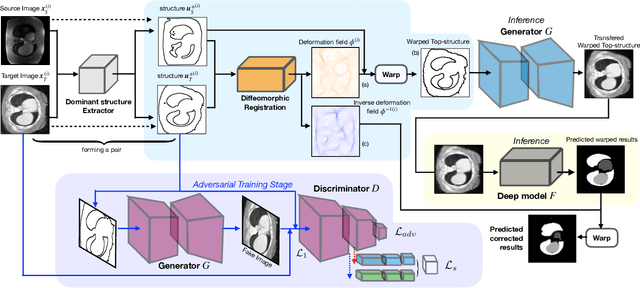
Generative models have been widely proposed in image recognition to generate more images where the distribution is similar to that of the real images. It often introduces a discriminator network to discriminate original real data and generated data. However, such discriminator often considers the distribution of the data and did not pay enough attention to the intrinsic gap due to structure. In this paper, we reformulate a new image to image translation problem to reduce structural gap, in addition to the typical intensity distribution gap. We further propose a simple yet important Structure Unbiased Adversarial Model for Medical Image Segmentation (SUAM) with learnable inverse structural deformation for medical image segmentation. It consists of a structure extractor, an attention diffeomorphic registration and a structure \& intensity distribution rendering module. The structure extractor aims to extract the dominant structure of the input image. The attention diffeomorphic registration is proposed to reduce the structure gap with an inverse deformation field to warp the prediction masks back to their original form. The structure rendering module is to render the deformed structure to an image with targeted intensity distribution. We apply the proposed SUAM on both optical coherence tomography (OCT), magnetic resonance imaging (MRI) and computerized tomography (CT) data. Experimental results show that the proposed method has the capability to transfer both intensity and structure distributions.
HASA: Hybrid Architecture Search with Aggregation Strategy for Echinococcosis Classification and Ovary Segmentation in Ultrasound Images
Apr 20, 2022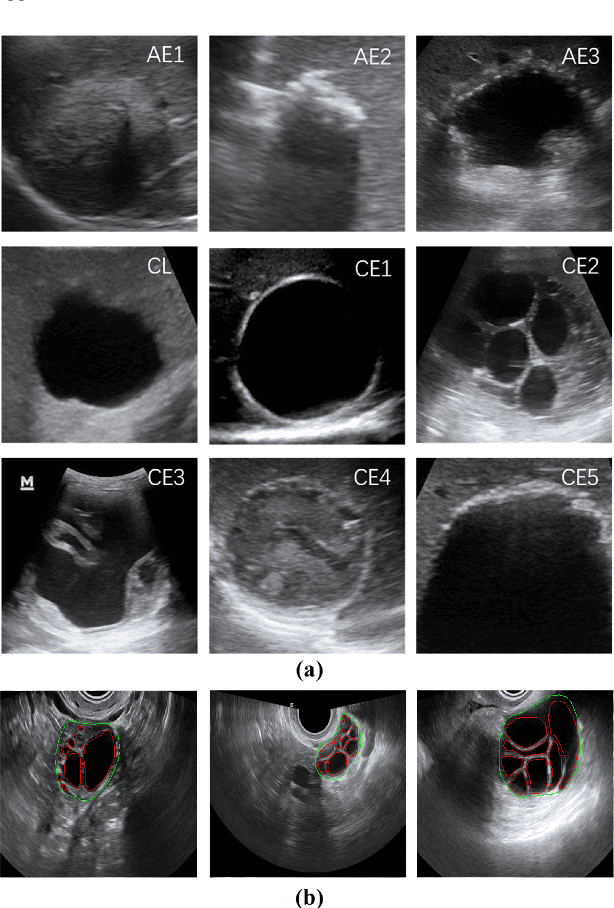
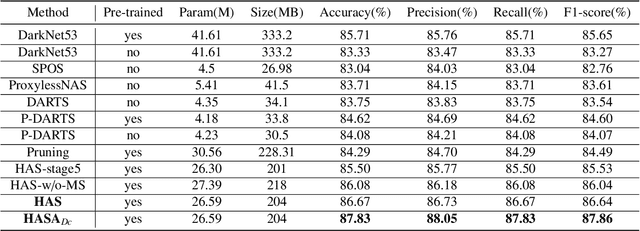
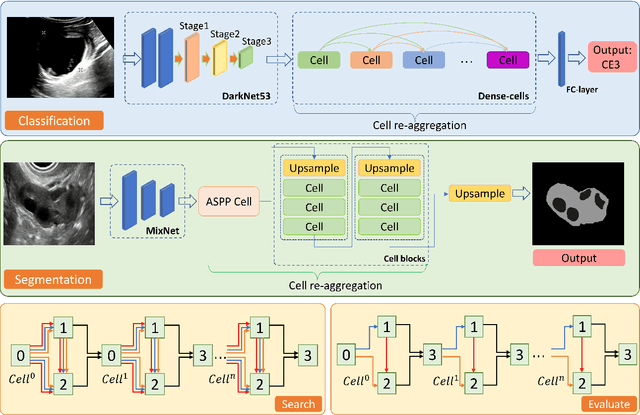
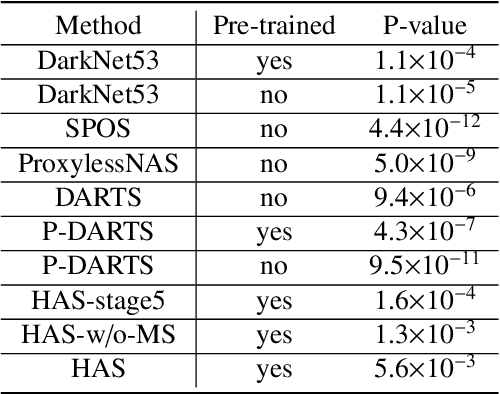
Different from handcrafted features, deep neural networks can automatically learn task-specific features from data. Due to this data-driven nature, they have achieved remarkable success in various areas. However, manual design and selection of suitable network architectures are time-consuming and require substantial effort of human experts. To address this problem, researchers have proposed neural architecture search (NAS) algorithms which can automatically generate network architectures but suffer from heavy computational cost and instability if searching from scratch. In this paper, we propose a hybrid NAS framework for ultrasound (US) image classification and segmentation. The hybrid framework consists of a pre-trained backbone and several searched cells (i.e., network building blocks), which takes advantage of the strengths of both NAS and the expert knowledge from existing convolutional neural networks. Specifically, two effective and lightweight operations, a mixed depth-wise convolution operator and a squeeze-and-excitation block, are introduced into the candidate operations to enhance the variety and capacity of the searched cells. These two operations not only decrease model parameters but also boost network performance. Moreover, we propose a re-aggregation strategy for the searched cells, aiming to further improve the performance for different vision tasks. We tested our method on two large US image datasets, including a 9-class echinococcosis dataset containing 9566 images for classification and an ovary dataset containing 3204 images for segmentation. Ablation experiments and comparison with other handcrafted or automatically searched architectures demonstrate that our method can generate more powerful and lightweight models for the above US image classification and segmentation tasks.
Sketch guided and progressive growing GAN for realistic and editable ultrasound image synthesis
Apr 19, 2022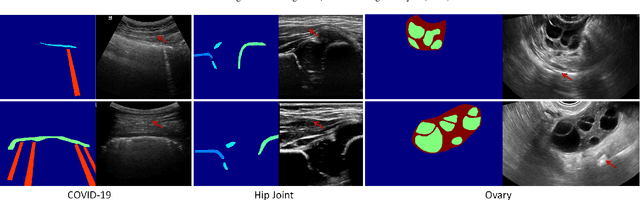
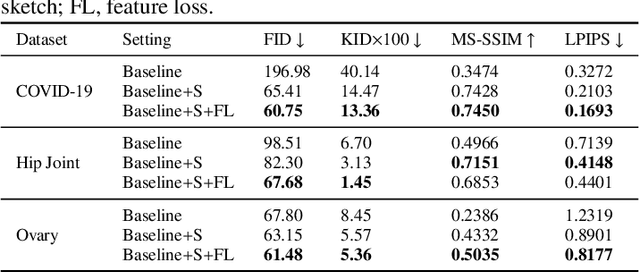
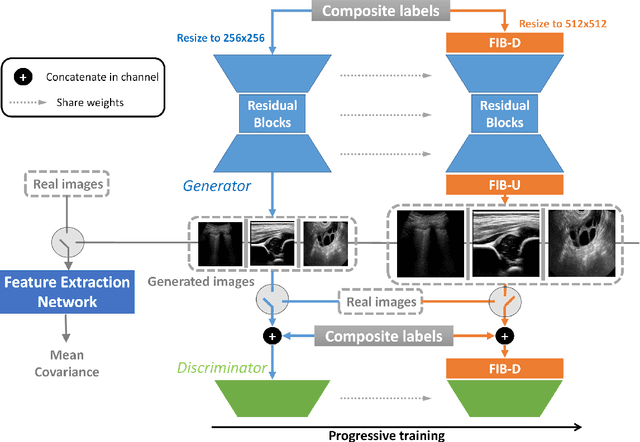

Ultrasound (US) imaging is widely used for anatomical structure inspection in clinical diagnosis. The training of new sonographers and deep learning based algorithms for US image analysis usually requires a large amount of data. However, obtaining and labeling large-scale US imaging data are not easy tasks, especially for diseases with low incidence. Realistic US image synthesis can alleviate this problem to a great extent. In this paper, we propose a generative adversarial network (GAN) based image synthesis framework. Our main contributions include: 1) we present the first work that can synthesize realistic B-mode US images with high-resolution and customized texture editing features; 2) to enhance structural details of generated images, we propose to introduce auxiliary sketch guidance into a conditional GAN. We superpose the edge sketch onto the object mask and use the composite mask as the network input; 3) to generate high-resolution US images, we adopt a progressive training strategy to gradually generate high-resolution images from low-resolution images. In addition, a feature loss is proposed to minimize the difference of high-level features between the generated and real images, which further improves the quality of generated images; 4) the proposed US image synthesis method is quite universal and can also be generalized to the US images of other anatomical structures besides the three ones tested in our study (lung, hip joint, and ovary); 5) extensive experiments on three large US image datasets are conducted to validate our method. Ablation studies, customized texture editing, user studies, and segmentation tests demonstrate promising results of our method in synthesizing realistic US images.
MOS: A Low Latency and Lightweight Framework for Face Detection, Landmark Localization, and Head Pose Estimation
Nov 01, 2021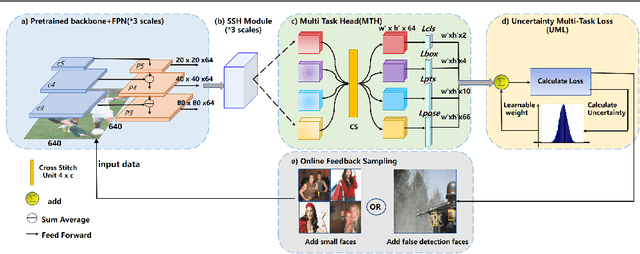
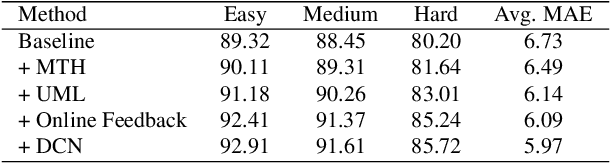
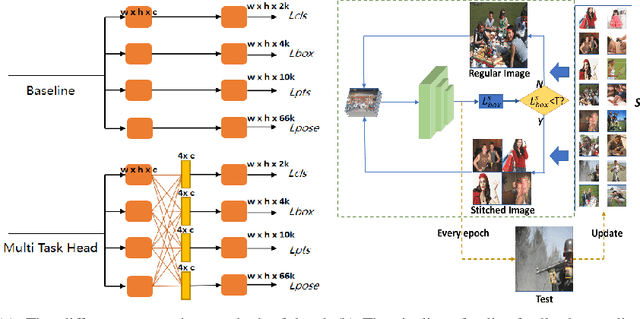
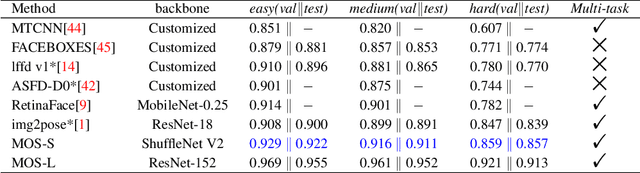
With the emergence of service robots and surveillance cameras, dynamic face recognition (DFR) in wild has received much attention in recent years. Face detection and head pose estimation are two important steps for DFR. Very often, the pose is estimated after the face detection. However, such sequential computations lead to higher latency. In this paper, we propose a low latency and lightweight network for simultaneous face detection, landmark localization and head pose estimation. Inspired by the observation that it is more challenging to locate the facial landmarks for faces with large angles, a pose loss is proposed to constrain the learning. Moreover, we also propose an uncertainty multi-task loss to learn the weights of individual tasks automatically. Another challenge is that robots often use low computational units like ARM based computing core and we often need to use lightweight networks instead of the heavy ones, which lead to performance drop especially for small and hard faces. In this paper, we propose online feedback sampling to augment the training samples across different scales, which increases the diversity of training data automatically. Through validation in commonly used WIDER FACE, AFLW and AFLW2000 datasets, the results show that the proposed method achieves the state-of-the-art performance in low computational resources. The code and data will be available at https://github.com/lyp-deeplearning/MOS-Multi-Task-Face-Detect.
Proxy-bridged Image Reconstruction Network for Anomaly Detection in Medical Images
Oct 05, 2021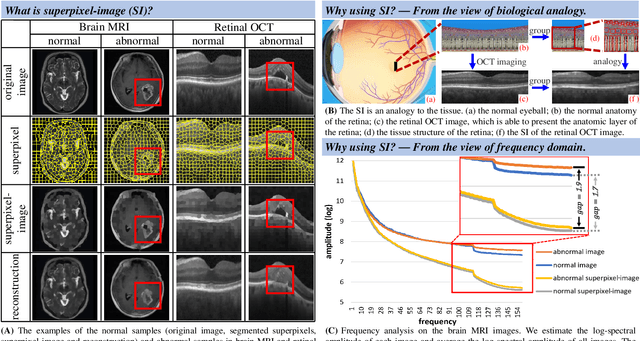
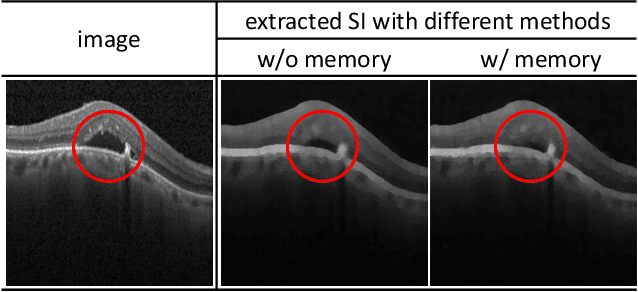
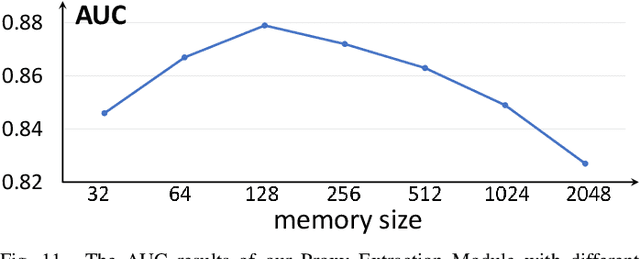
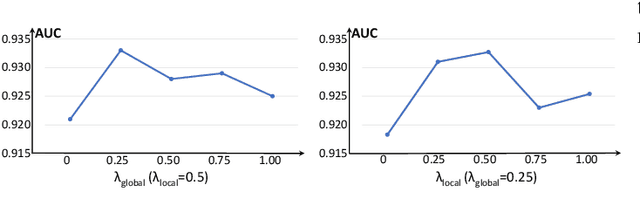
Anomaly detection in medical images refers to the identification of abnormal images with only normal images in the training set. Most existing methods solve this problem with a self-reconstruction framework, which tends to learn an identity mapping and reduces the sensitivity to anomalies. To mitigate this problem, in this paper, we propose a novel Proxy-bridged Image Reconstruction Network (ProxyAno) for anomaly detection in medical images. Specifically, we use an intermediate proxy to bridge the input image and the reconstructed image. We study different proxy types, and we find that the superpixel-image (SI) is the best one. We set all pixels' intensities within each superpixel as their average intensity, and denote this image as SI. The proposed ProxyAno consists of two modules, a Proxy Extraction Module and an Image Reconstruction Module. In the Proxy Extraction Module, a memory is introduced to memorize the feature correspondence for normal image to its corresponding SI, while the memorized correspondence does not apply to the abnormal images, which leads to the information loss for abnormal image and facilitates the anomaly detection. In the Image Reconstruction Module, we map an SI to its reconstructed image. Further, we crop a patch from the image and paste it on the normal SI to mimic the anomalies, and enforce the network to reconstruct the normal image even with the pseudo abnormal SI. In this way, our network enlarges the reconstruction error for anomalies. Extensive experiments on brain MR images, retinal OCT images and retinal fundus images verify the effectiveness of our method for both image-level and pixel-level anomaly detection.