 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCite: Enabling LLMs to Generate Fine-grained Citations in Long-context QA
Sep 04, 2024



Though current long-context large language models (LLMs) have demonstrated impressive capacities in answering user questions based on extensive text, the lack of citations in their responses makes user verification difficult, leading to concerns about their trustworthiness due to their potential hallucinations. In this work, we aim to enable long-context LLMs to generate responses with fine-grained sentence-level citations, improving their faithfulness and verifiability. We first introduce LongBench-Cite, an automated benchmark for assessing current LLMs' performance in Long-Context Question Answering with Citations (LQAC), revealing considerable room for improvement. To this end, we propose CoF (Coarse to Fine), a novel pipeline that utilizes off-the-shelf LLMs to automatically generate long-context QA instances with precise sentence-level citations, and leverage this pipeline to construct LongCite-45k, a large-scale SFT dataset for LQAC. Finally, we train LongCite-8B and LongCite-9B using the LongCite-45k dataset, successfully enabling their generation of accurate responses and fine-grained sentence-level citations in a single output. The evaluation results on LongBench-Cite show that our trained models achieve state-of-the-art citation quality, surpassing advanced proprietary models including GPT-4o.
CogVLM2: Visual Language Models for Image and Video Understanding
Aug 29, 2024



Beginning with VisualGLM and CogVLM, we are continuously exploring VLMs in pursuit of enhanced vision-language fusion, efficient higher-resolution architecture, and broader modalities and applications. Here we propose the CogVLM2 family, a new generation of visual language models for image and video understanding including CogVLM2, CogVLM2-Video and GLM-4V. As an image understanding model, CogVLM2 inherits the visual expert architecture with improved training recipes in both pre-training and post-training stages, supporting input resolution up to $1344 \times 1344$ pixels. As a video understanding model, CogVLM2-Video integrates multi-frame input with timestamps and proposes automated temporal grounding data construction. Notably, CogVLM2 family has achieved state-of-the-art results on benchmarks like MMBench, MM-Vet, TextVQA, MVBench and VCGBench. All models are open-sourced in https://github.com/THUDM/CogVLM2 and https://github.com/THUDM/GLM-4, contributing to the advancement of the field.
OpenEP: Open-Ended Future Event Prediction
Aug 14, 2024Future event prediction (FEP) is a long-standing and crucial task in the world, as understanding the evolution of events enables early risk identification, informed decision-making, and strategic planning. Existing work typically treats event prediction as classification tasks and confines the outcomes of future events to a fixed scope, such as yes/no questions, candidate set, and taxonomy, which is difficult to include all possible outcomes of future events. In this paper, we introduce OpenEP (an Open-Ended Future Event Prediction task), which generates flexible and diverse predictions aligned with real-world scenarios. This is mainly reflected in two aspects: firstly, the predictive questions are diverse, covering different stages of event development and perspectives; secondly, the outcomes are flexible, without constraints on scope or format. To facilitate the study of this task, we construct OpenEPBench, an open-ended future event prediction dataset. For question construction, we pose questions from seven perspectives, including location, time, event development, event outcome, event impact, event response, and other, to facilitate an in-depth analysis and understanding of the comprehensive evolution of events. For outcome construction, we collect free-form text containing the outcomes as ground truth to provide semantically complete and detail-enriched outcomes. Furthermore, we propose StkFEP, a stakeholder-enhanced future event prediction framework, that incorporates event characteristics for open-ended settings. Our method extracts stakeholders involved in events to extend questions to gather diverse information. We also collect historically events that are relevant and similar to the question to reveal potential evolutionary patterns. Experiment results indicate that accurately predicting future events in open-ended settings is challenging for existing LLMs.
LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs
Aug 13, 2024



Current long context large language models (LLMs) can process inputs up to 100,000 tokens, yet struggle to generate outputs exceeding even a modest length of 2,000 words. Through controlled experiments, we find that the model's effective generation length is inherently bounded by the sample it has seen during supervised fine-tuning (SFT). In other words, their output limitation is due to the scarcity of long-output examples in existing SFT datasets. To address this, we introduce AgentWrite, an agent-based pipeline that decomposes ultra-long generation tasks into subtasks, enabling off-the-shelf LLMs to generate coherent outputs exceeding 20,000 words. Leveraging AgentWrite, we construct LongWriter-6k, a dataset containing 6,000 SFT data with output lengths ranging from 2k to 32k words. By incorporating this dataset into model training, we successfully scale the output length of existing models to over 10,000 words while maintaining output quality. We also develop LongBench-Write, a comprehensive benchmark for evaluating ultra-long generation capabilities. Our 9B parameter model, further improved through DPO, achieves state-of-the-art performance on this benchmark, surpassing even much larger proprietary models. In general, our work demonstrates that existing long context LLM already possesses the potential for a larger output window--all you need is data with extended output during model alignment to unlock this capability. Our code & models are at: https://github.com/THUDM/LongWriter.
MAVEN-Fact: A Large-scale Event Factuality Detection Dataset
Jul 22, 2024Event Factuality Detection (EFD) task determines the factuality of textual events, i.e., classifying whether an event is a fact, possibility, or impossibility, which is essential for faithfully understanding and utilizing event knowledge. However, due to the lack of high-quality large-scale data, event factuality detection is under-explored in event understanding research, which limits the development of EFD community. To address these issues and provide faithful event understanding, we introduce MAVEN-Fact, a large-scale and high-quality EFD dataset based on the MAVEN dataset. MAVEN-Fact includes factuality annotations of 112,276 events, making it the largest EFD dataset. Extensive experiments demonstrate that MAVEN-Fact is challenging for both conventional fine-tuned models and large language models (LLMs). Thanks to the comprehensive annotations of event arguments and relations in MAVEN, MAVEN-Fact also supports some further analyses and we find that adopting event arguments and relations helps in event factuality detection for fine-tuned models but does not benefit LLMs. Furthermore, we preliminarily study an application case of event factuality detection and find it helps in mitigating event-related hallucination in LLMs. Our dataset and codes can be obtained from \url{https://github.com/lcy2723/MAVEN-FACT}
LLMAEL: Large Language Models are Good Context Augmenters for Entity Linking
Jul 04, 2024



Entity Linking (EL) models are well-trained at mapping mentions to their corresponding entities according to a given context. However, EL models struggle to disambiguate long-tail entities due to their limited training data. Meanwhile, large language models (LLMs) are more robust at interpreting uncommon mentions. Yet, due to a lack of specialized training, LLMs suffer at generating correct entity IDs. Furthermore, training an LLM to perform EL is cost-intensive. Building upon these insights, we introduce LLM-Augmented Entity Linking LLMAEL, a plug-and-play approach to enhance entity linking through LLM data augmentation. We leverage LLMs as knowledgeable context augmenters, generating mention-centered descriptions as additional input, while preserving traditional EL models for task specific processing. Experiments on 6 standard datasets show that the vanilla LLMAEL outperforms baseline EL models in most cases, while the fine-tuned LLMAEL set the new state-of-the-art results across all 6 benchmarks.
SeaKR: Self-aware Knowledge Retrieval for Adaptive Retrieval Augmented Generation
Jun 27, 2024



This paper introduces Self-aware Knowledge Retrieval (SeaKR), a novel adaptive RAG model that extracts self-aware uncertainty of LLMs from their internal states. SeaKR activates retrieval when the LLMs present high self-aware uncertainty for generation. To effectively integrate retrieved knowledge snippets, SeaKR re-ranks them based on LLM's self-aware uncertainty to preserve the snippet that reduces their uncertainty to the utmost. To facilitate solving complex tasks that require multiple retrievals, SeaKR utilizes their self-aware uncertainty to choose among different reasoning strategies. Our experiments on both complex and simple Question Answering datasets show that SeaKR outperforms existing adaptive RAG methods. We release our code at https://github.com/THU-KEG/SeaKR.
Aligning Teacher with Student Preferences for Tailored Training Data Generation
Jun 27, 2024



Large Language Models (LLMs) have shown significant promise as copilots in various tasks. Local deployment of LLMs on edge devices is necessary when handling privacy-sensitive data or latency-sensitive tasks. The computational constraints of such devices make direct deployment of powerful large-scale LLMs impractical, necessitating the Knowledge Distillation from large-scale models to lightweight models. Lots of work has been done to elicit diversity and quality training examples from LLMs, but little attention has been paid to aligning teacher instructional content based on student preferences, akin to "responsive teaching" in pedagogy. Thus, we propose ARTE, dubbed Aligning TeacheR with StudenT PreferencEs, a framework that aligns the teacher model with student preferences to generate tailored training examples for Knowledge Distillation. Specifically, we elicit draft questions and rationales from the teacher model, then collect student preferences on these questions and rationales using students' performance with in-context learning as a proxy, and finally align the teacher model with student preferences. In the end, we repeat the first step with the aligned teacher model to elicit tailored training examples for the student model on the target task. Extensive experiments on academic benchmarks demonstrate the superiority of ARTE over existing instruction-tuning datasets distilled from powerful LLMs. Moreover, we thoroughly investigate the generalization of ARTE, including the generalization of fine-tuned student models in reasoning ability and the generalization of aligned teacher models to generate tailored training data across tasks and students. In summary, our contributions lie in proposing a novel framework for tailored training example generation, demonstrating its efficacy in experiments, and investigating the generalization of both student & aligned teacher models in ARTE.
Simulating Classroom Education with LLM-Empowered Agents
Jun 27, 2024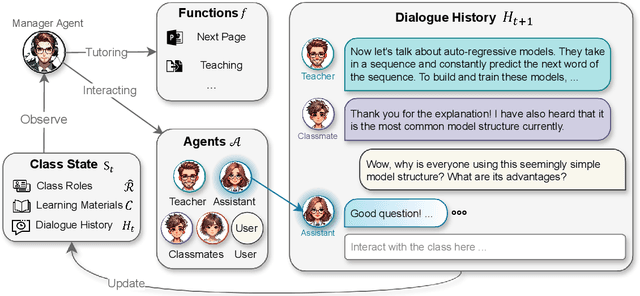

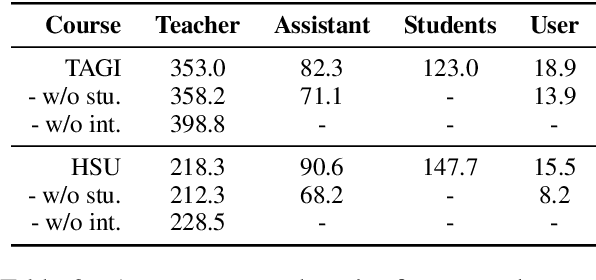
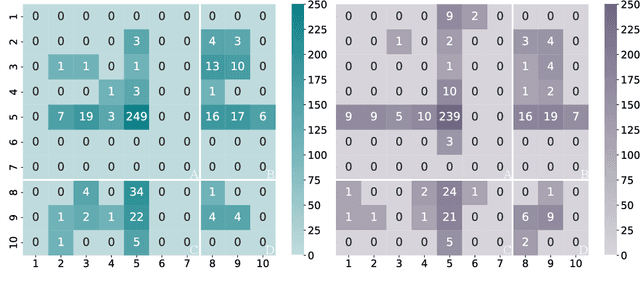
Large language models (LLMs) have been employed in various intelligent educational tasks to assist teaching. While preliminary explorations have focused on independent LLM-empowered agents for specific educational tasks, the potential for LLMs within a multi-agent collaborative framework to simulate a classroom with real user participation remains unexplored. In this work, we propose SimClass, a multi-agent classroom simulation framework involving user participation. We recognize representative class roles and introduce a novel class control mechanism for automatic classroom teaching, and conduct user experiments in two real-world courses. Utilizing the Flanders Interactive Analysis System and Community of Inquiry theoretical frame works from educational analysis, we demonstrate that LLMs can simulate traditional classroom interaction patterns effectively while enhancing user's experience. We also observe emergent group behaviors among agents in SimClass, where agents collaborate to create enlivening interactions in classrooms to improve user learning process. We hope this work pioneers the application of LLM-empowered multi-agent systems in virtual classroom teaching.
Finding Safety Neurons in Large Language Models
Jun 20, 2024



Large language models (LLMs) excel in various capabilities but also pose safety risks such as generating harmful content and misinformation, even after safety alignment. In this paper, we explore the inner mechanisms of safety alignment from the perspective of mechanistic interpretability, focusing on identifying and analyzing safety neurons within LLMs that are responsible for safety behaviors. We propose generation-time activation contrasting to locate these neurons and dynamic activation patching to evaluate their causal effects. Experiments on multiple recent LLMs show that: (1) Safety neurons are sparse and effective. We can restore $90$% safety performance with intervention only on about $5$% of all the neurons. (2) Safety neurons encode transferrable mechanisms. They exhibit consistent effectiveness on different red-teaming datasets. The finding of safety neurons also interprets "alignment tax". We observe that the identified key neurons for safety and helpfulness significantly overlap, but they require different activation patterns of the shared neurons. Furthermore, we demonstrate an application of safety neurons in detecting unsafe outputs before generation. Our findings may promote further research on understanding LLM alignment. The source codes will be publicly released to facilitate future research.