 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Strings to Data Science: a Practical Framework for Automated String Handling
Nov 04, 2021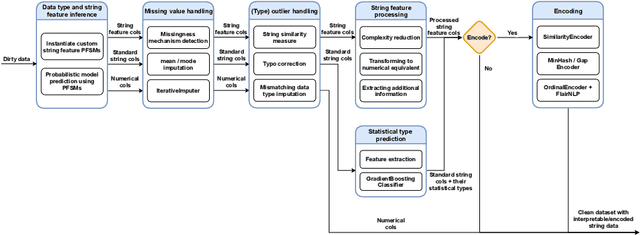
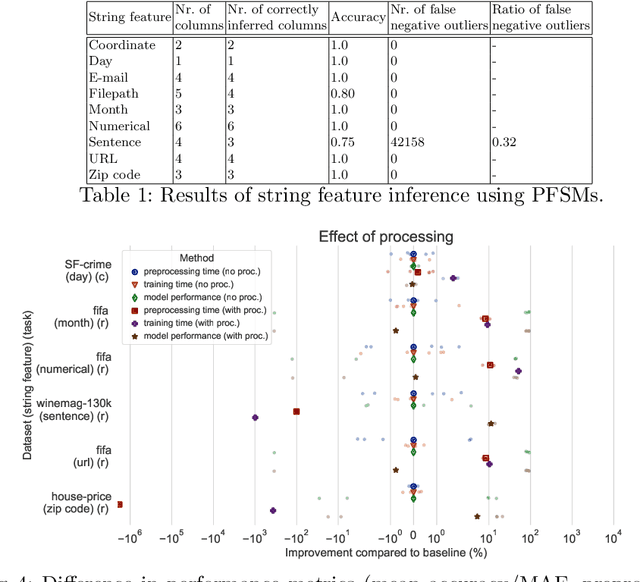
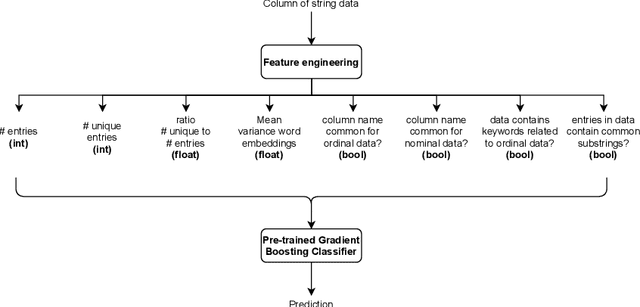
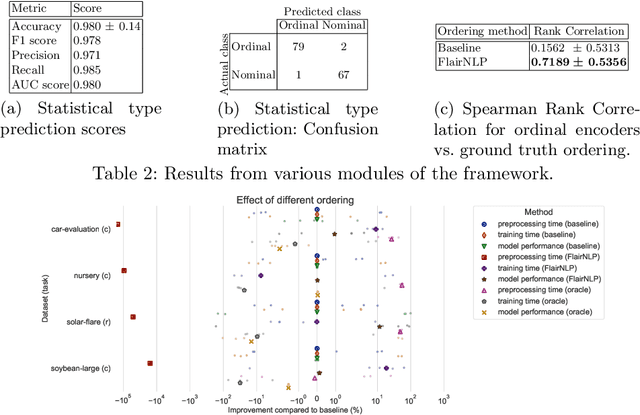
Many machine learning libraries require that string features be converted to a numerical representation for the models to work as intended. Categorical string features can represent a wide variety of data (e.g., zip codes, names, marital status), and are notoriously difficult to preprocess automatically. In this paper, we propose a framework to do so based on best practices, domain knowledge, and novel techniques. It automatically identifies different types of string features, processes them accordingly, and encodes them into numerical representations. We also provide an open source Python implementation to automatically preprocess categorical string data in tabular datasets and demonstrate promising results on a wide range of datasets.
Cats, not CAT scans: a study of dataset similarity in transfer learning for 2D medical image classification
Jul 13, 2021
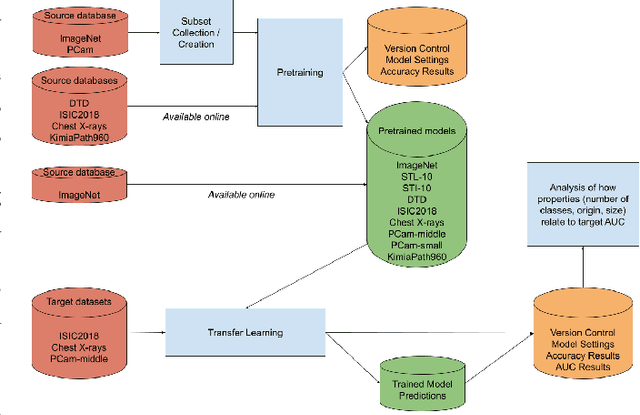
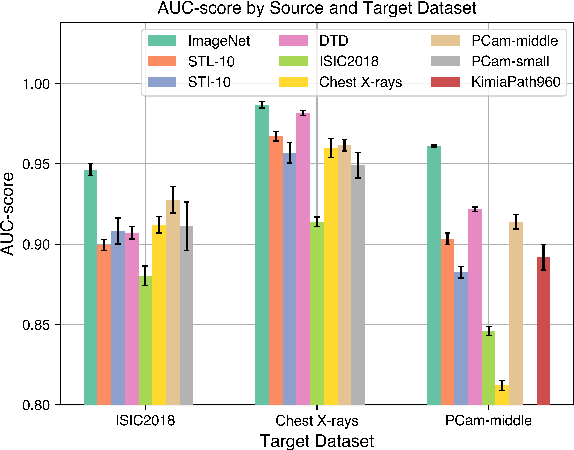
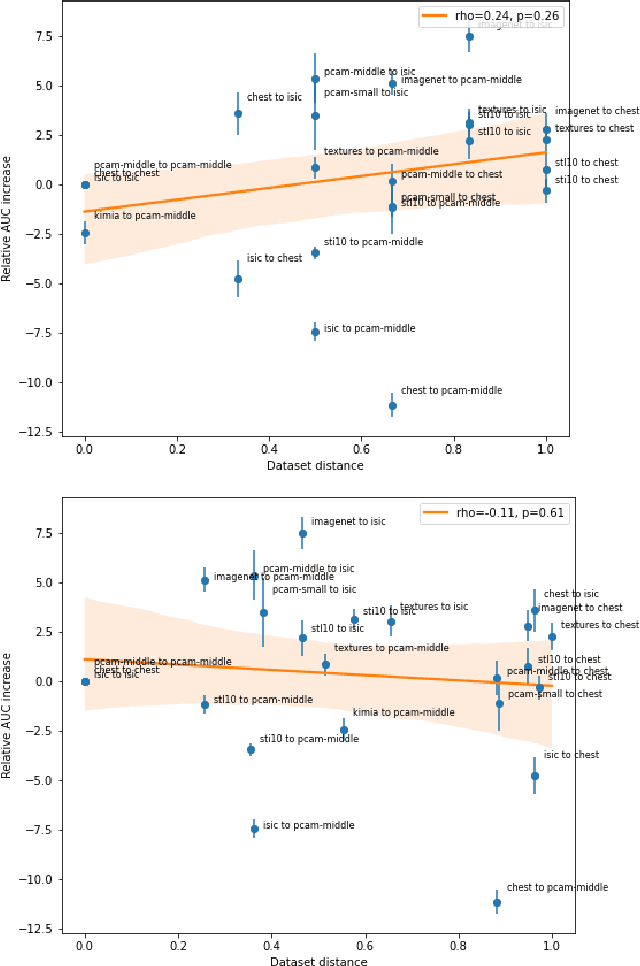
Transfer learning is a commonly used strategy for medical image classification, especially via pretraining on source data and fine-tuning on target data. There is currently no consensus on how to choose appropriate source data, and in the literature we can find both evidence of favoring large natural image datasets such as ImageNet, and evidence of favoring more specialized medical datasets. In this paper we perform a systematic study with nine source datasets with natural or medical images, and three target medical datasets, all with 2D images. We find that ImageNet is the source leading to the highest performances, but also that larger datasets are not necessarily better. We also study different definitions of data similarity. We show that common intuitions about similarity may be inaccurate, and therefore not sufficient to predict an appropriate source a priori. Finally, we discuss several steps needed for further research in this field, especially with regard to other types (for example 3D) medical images. Our experiments and pretrained models are available via \url{https://www.github.com/vcheplygina/cats-scans}
Meta-Learning for Symbolic Hyperparameter Defaults
Jun 11, 2021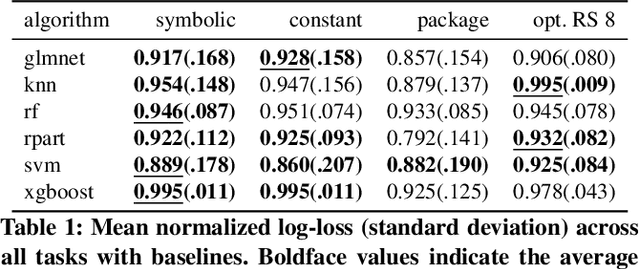
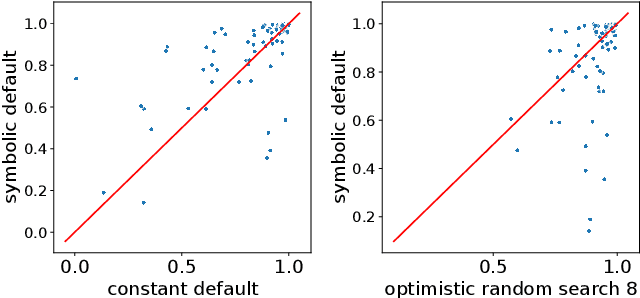
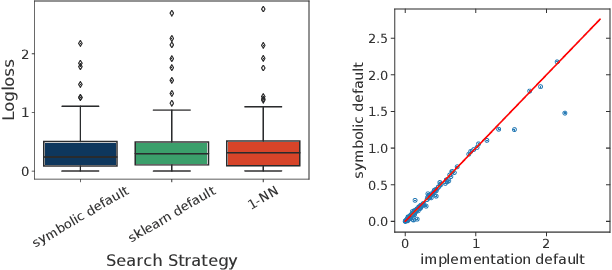
Hyperparameter optimization in machine learning (ML) deals with the problem of empirically learning an optimal algorithm configuration from data, usually formulated as a black-box optimization problem. In this work, we propose a zero-shot method to meta-learn symbolic default hyperparameter configurations that are expressed in terms of the properties of the dataset. This enables a much faster, but still data-dependent, configuration of the ML algorithm, compared to standard hyperparameter optimization approaches. In the past, symbolic and static default values have usually been obtained as hand-crafted heuristics. We propose an approach of learning such symbolic configurations as formulas of dataset properties from a large set of prior evaluations on multiple datasets by optimizing over a grammar of expressions using an evolutionary algorithm. We evaluate our method on surrogate empirical performance models as well as on real data across 6 ML algorithms on more than 100 datasets and demonstrate that our method indeed finds viable symbolic defaults.
Fixed-point Quantization of Convolutional Neural Networks for Quantized Inference on Embedded Platforms
Feb 03, 2021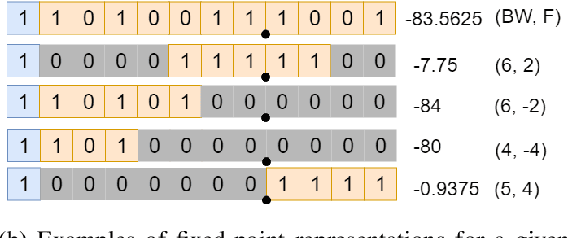
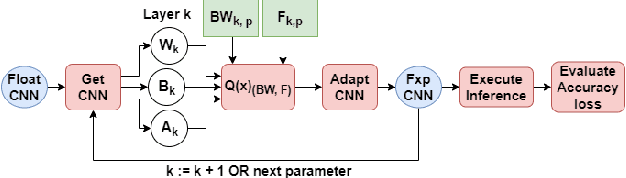
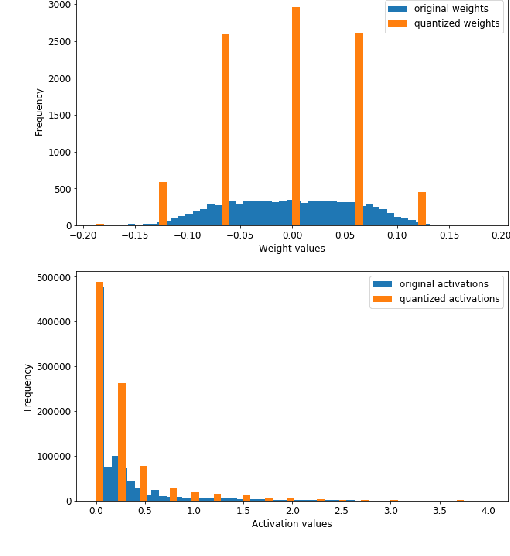
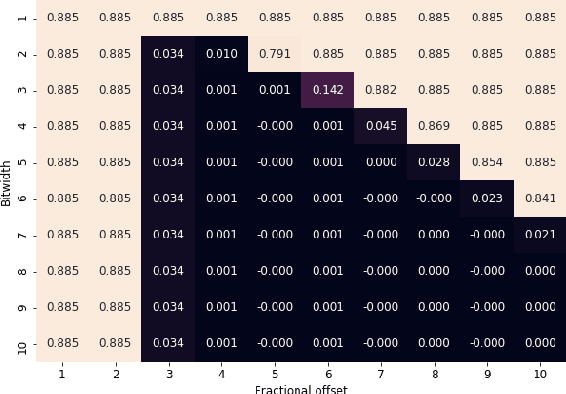
Convolutional Neural Networks (CNNs) have proven to be a powerful state-of-the-art method for image classification tasks. One drawback however is the high computational complexity and high memory consumption of CNNs which makes them unfeasible for execution on embedded platforms which are constrained on physical resources needed to support CNNs. Quantization has often been used to efficiently optimize CNNs for memory and computational complexity at the cost of a loss of prediction accuracy. We therefore propose a method to optimally quantize the weights, biases and activations of each layer of a pre-trained CNN while controlling the loss in inference accuracy to enable quantized inference. We quantize the 32-bit floating-point precision parameters to low bitwidth fixed-point representations thereby finding optimal bitwidths and fractional offsets for parameters of each layer of a given CNN. We quantize parameters of a CNN post-training without re-training it. Our method is designed to quantize parameters of a CNN taking into account how other parameters are quantized because ignoring quantization errors due to other quantized parameters leads to a low precision CNN with accuracy losses of up to 50% which is far beyond what is acceptable. Our final method therefore gives a low precision CNN with accuracy losses of less than 1%. As compared to a method used by commercial tools that quantize all parameters to 8-bits, our approach provides quantized CNN with averages of 53% lower memory consumption and 77.5% lower cost of executing multiplications for the two CNNs trained on the four datasets that we tested our work on. We find that layer-wise quantization of parameters significantly helps in this process.
Hyperboost: Hyperparameter Optimization by Gradient Boosting surrogate models
Jan 06, 2021
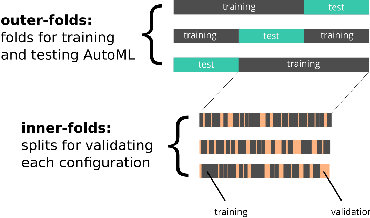

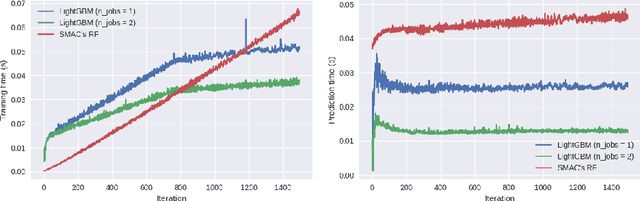
Bayesian Optimization is a popular tool for tuning algorithms in automatic machine learning (AutoML) systems. Current state-of-the-art methods leverage Random Forests or Gaussian processes to build a surrogate model that predicts algorithm performance given a certain set of hyperparameter settings. In this paper, we propose a new surrogate model based on gradient boosting, where we use quantile regression to provide optimistic estimates of the performance of an unobserved hyperparameter setting, and combine this with a distance metric between unobserved and observed hyperparameter settings to help regulate exploration. We demonstrate empirically that the new method is able to outperform some state-of-the art techniques across a reasonable sized set of classification problems.
Theory-based Habit Modeling for Enhancing Behavior Prediction
Jan 05, 2021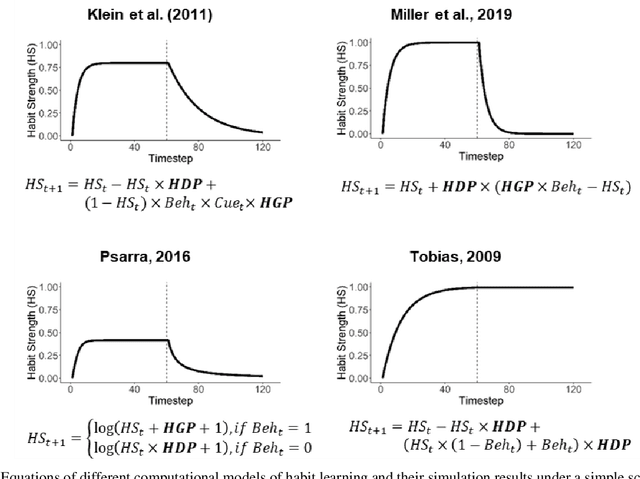

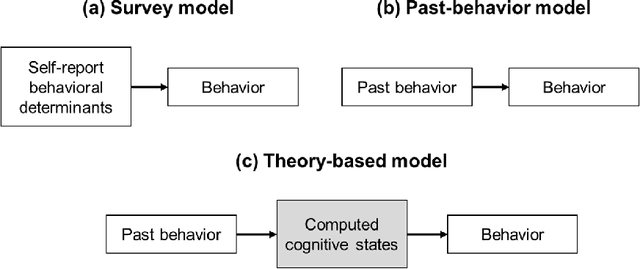
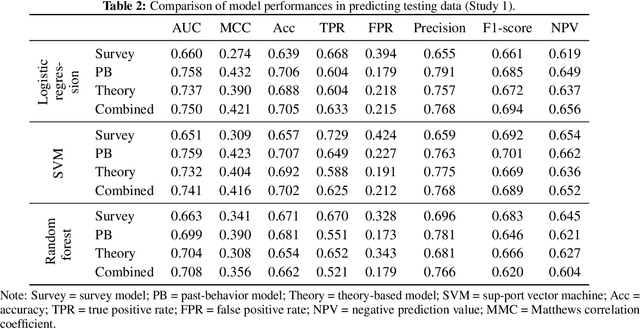
Psychological theories of habit posit that when a strong habit is formed through behavioral repetition, it can trigger behavior automatically in the same environment. Given the reciprocal relationship between habit and behavior, changing lifestyle behaviors (e.g., toothbrushing) is largely a task of breaking old habits and creating new and healthy ones. Thus, representing users' habit strengths can be very useful for behavior change support systems (BCSS), for example, to predict behavior or to decide when an intervention reaches its intended effect. However, habit strength is not directly observable and existing self-report measures are taxing for users. In this paper, built on recent computational models of habit formation, we propose a method to enable intelligent systems to compute habit strength based on observable behavior. The hypothesized advantage of using computed habit strength for behavior prediction was tested using data from two intervention studies, where we trained participants to brush their teeth twice a day for three weeks and monitored their behaviors using accelerometers. Through hierarchical cross-validation, we found that for the task of predicting future brushing behavior, computed habit strength clearly outperformed self-reported habit strength (in both studies) and was also superior to models based on past behavior frequency (in the larger second study). Our findings provide initial support for our theory-based approach of modeling user habits and encourages the use of habit computation to deliver personalized and adaptive interventions.
Aerial Imagery Pixel-level Segmentation
Dec 03, 2020
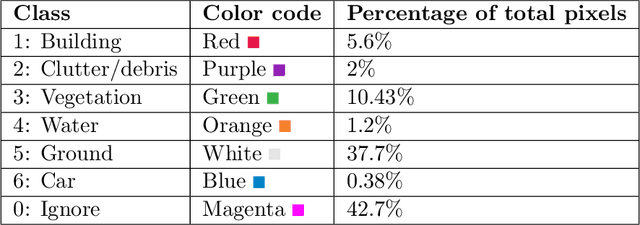

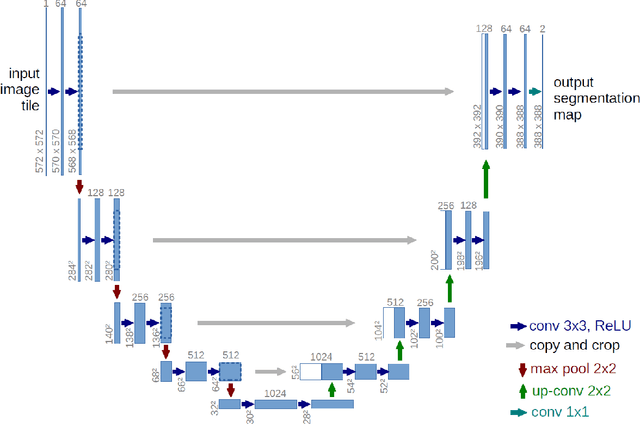
Aerial imagery can be used for important work on a global scale. Nevertheless, the analysis of this data using neural network architectures lags behind the current state-of-the-art on popular datasets such as PASCAL VOC, CityScapes and Camvid. In this paper we bridge the performance-gap between these popular datasets and aerial imagery data. Little work is done on aerial imagery with state-of-the-art neural network architectures in a multi-class setting. Our experiments concerning data augmentation, normalisation, image size and loss functions give insight into a high performance setup for aerial imagery segmentation datasets. Our work, using the state-of-the-art DeepLabv3+ Xception65 architecture, achieves a mean IOU of 70% on the DroneDeploy validation set. With this result, we clearly outperform the current publicly available state-of-the-art validation set mIOU (65%) performance with 5%. Furthermore, to our knowledge, there is no mIOU benchmark for the test set. Hence, we also propose a new benchmark on the DroneDeploy test set using the best performing DeepLabv3+ Xception65 architecture, with a mIOU score of 52.5%.
Importance of Tuning Hyperparameters of Machine Learning Algorithms
Jul 15, 2020
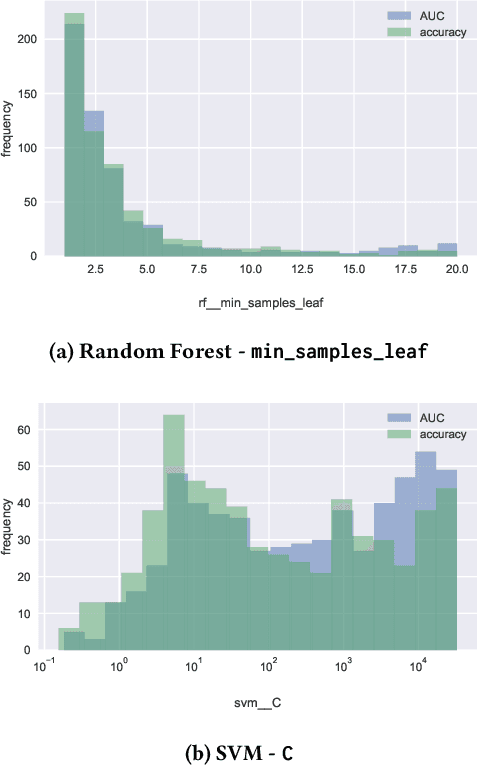

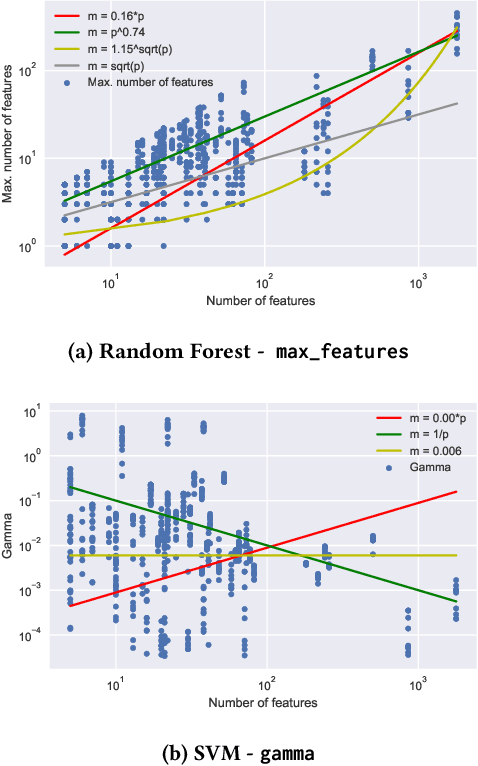
The performance of many machine learning algorithms depends on their hyperparameter settings. The goal of this study is to determine whether it is important to tune a hyperparameter or whether it can be safely set to a default value. We present a methodology to determine the importance of tuning a hyperparameter based on a non-inferiority test and tuning risk: the performance loss that is incurred when a hyperparameter is not tuned, but set to a default value. Because our methods require the notion of a default parameter, we present a simple procedure that can be used to determine reasonable default parameters. We apply our methods in a benchmark study using 59 datasets from OpenML. Our results show that leaving particular hyperparameters at their default value is non-inferior to tuning these hyperparameters. In some cases, leaving the hyperparameter at its default value even outperforms tuning it using a search procedure with a limited number of iterations.
GAMA: a General Automated Machine learning Assistant
Jul 09, 2020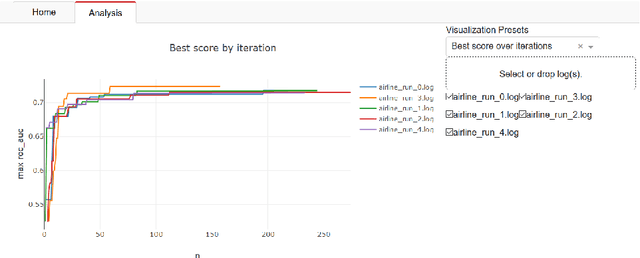
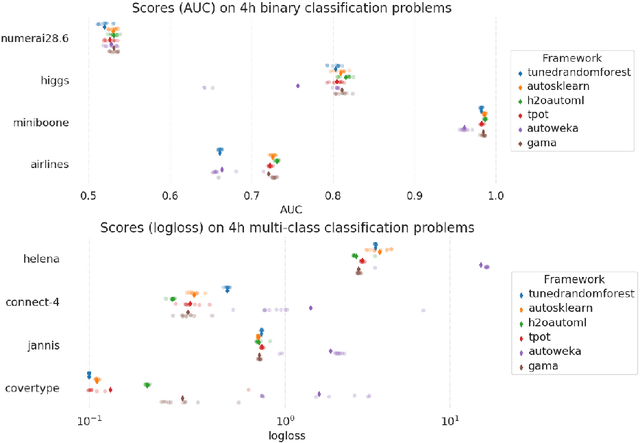
The General Automated Machine learning Assistant (GAMA) is a modular AutoML system developed to empower users to track and control how AutoML algorithms search for optimal machine learning pipelines, and facilitate AutoML research itself. In contrast to current, often black-box systems, GAMA allows users to plug in different AutoML and post-processing techniques, logs and visualizes the search process, and supports easy benchmarking. It currently features three AutoML search algorithms, two model post-processing steps, and is designed to allow for more components to be added.
Adaptation Strategies for Automated Machine Learning on Evolving Data
Jun 09, 2020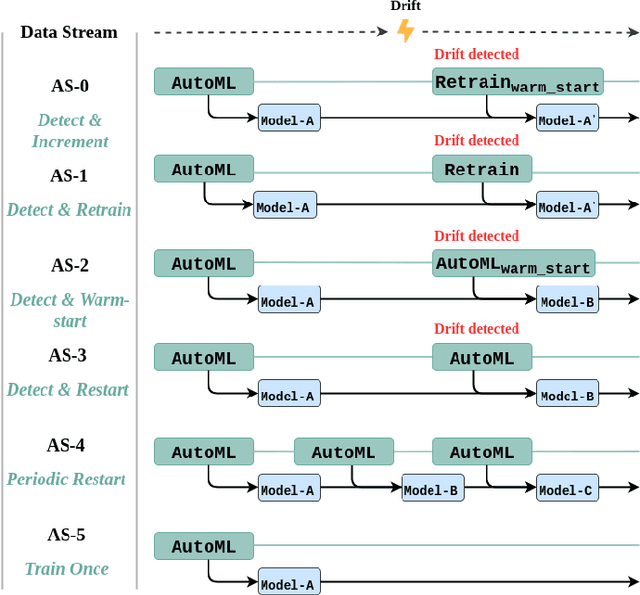
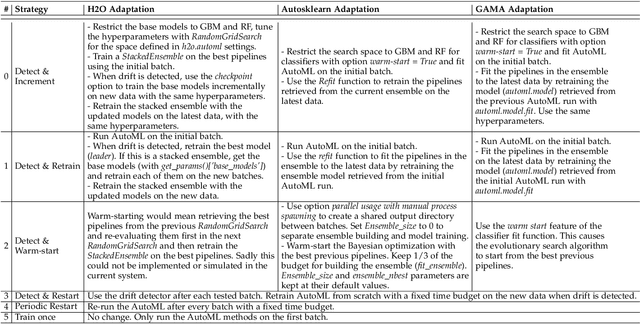
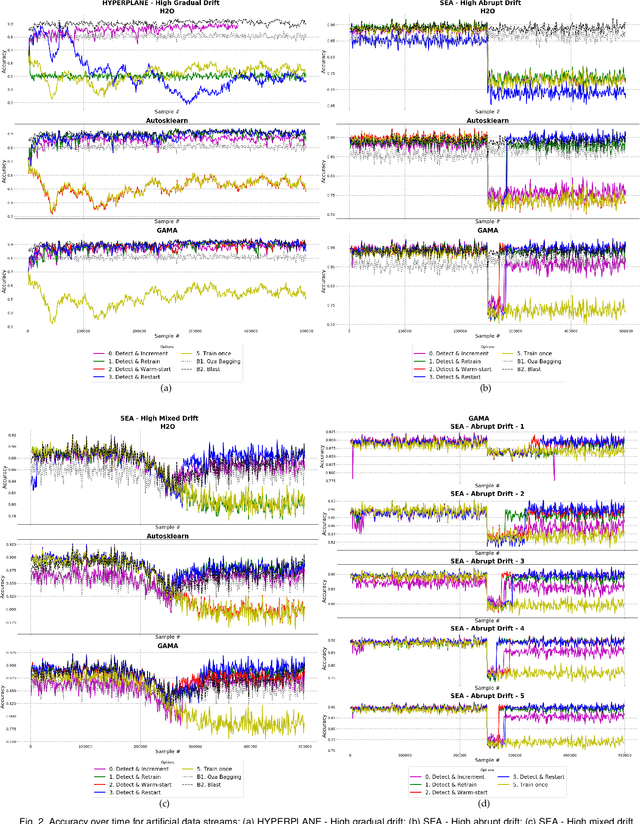
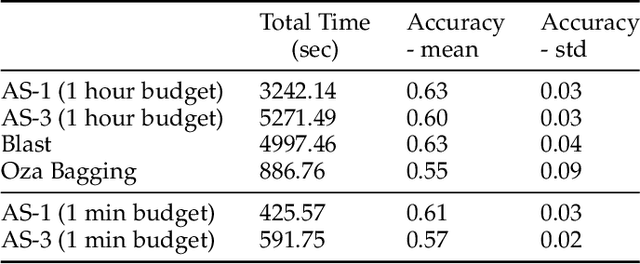
Automated Machine Learning (AutoML) systems have been shown to efficiently build good models for new datasets.However, it is often not clear how well they can adapt when the data evolves over time. The main goal of this study is to understand the effect of data stream challenges such as concept drift on the performance of AutoML methods, and which adaptation strategies can be employed to make them more robust. To that end, we propose 6 concept drift adaptation strategies and evaluate their effectiveness on different AutoML approaches. We do this for a variety of AutoML approaches for building machine learning pipelines, including those that leverage Bayesian optimization, genetic programming, and random search with automated stacking. These are evaluated empirically on real-world and synthetic data streams with different types of concept drift. Based on this analysis, we propose ways to develop more sophisticated and robust AutoML techniques.