 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical study on hyperparameter tuning of decision trees
Paper and Code
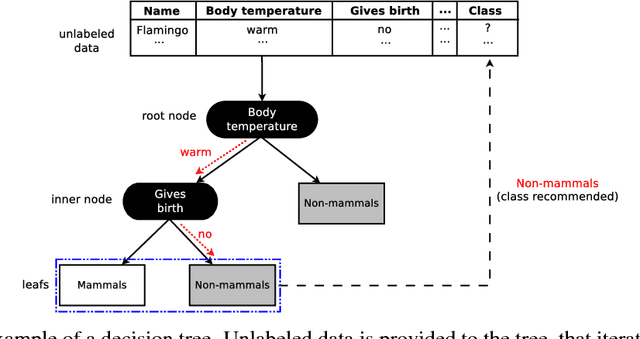
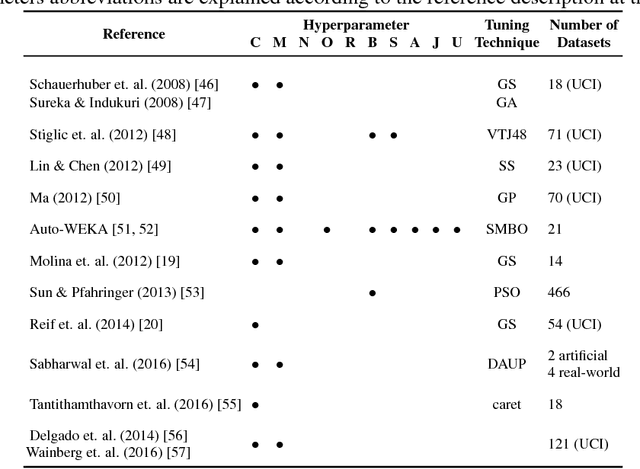
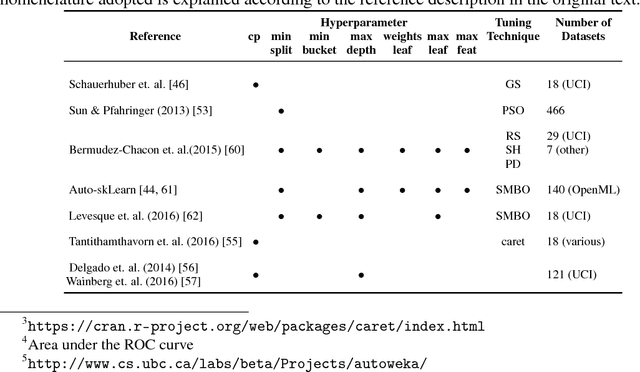
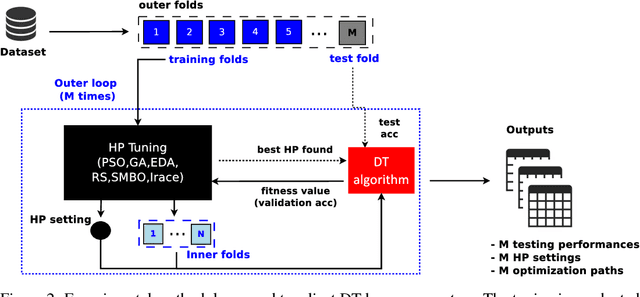
Machine learning algorithms often contain many hyperparameters whose values affect the predictive performance of the induced models in intricate ways. Due to the high number of possibilities for these hyperparameter configurations, and their complex interactions, it is common to use optimization techniques to find settings that lead to high predictive accuracy. However, we lack insight into how to efficiently explore this vast space of configurations: which are the best optimization techniques, how should we use them, and how significant is their effect on predictive or runtime performance? This paper provides a comprehensive approach for investigating the effects of hyperparameter tuning on three Decision Tree induction algorithms, CART, C4.5 and CTree. These algorithms were selected because they are based on similar principles, have presented a high predictive performance in several previous works and induce interpretable classification models. Additionally, they contain many interacting hyperparameters to be adjusted. Experiments were carried out with different tuning strategies to induce models and evaluate the relevance of hyperparameters using 94 classification datasets from OpenML. Experimental results indicate that hyperparameter tuning provides statistically significant improvements for C4.5 and CTree in only one-third of the datasets, and in most of the datasets for CART. Different tree algorithms may present different tuning scenarios, but in general, the tuning techniques required relatively few iterations to find accurate solutions. Furthermore, the best technique for all the algorithms was the Irace. Finally, we find that tuning a specific small subset of hyperparameters contributes most of the achievable optimal predictive performance.