 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformative Machine Learning
Paper and Code
Nov 08, 2018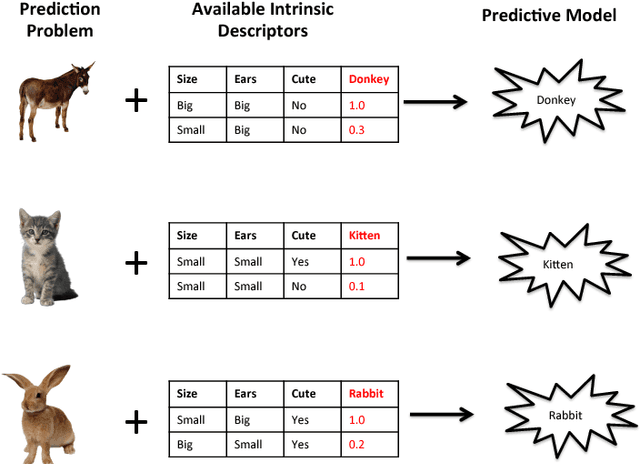
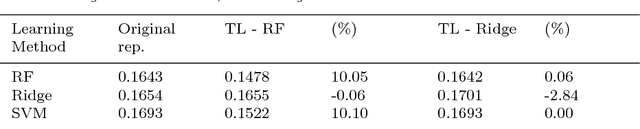
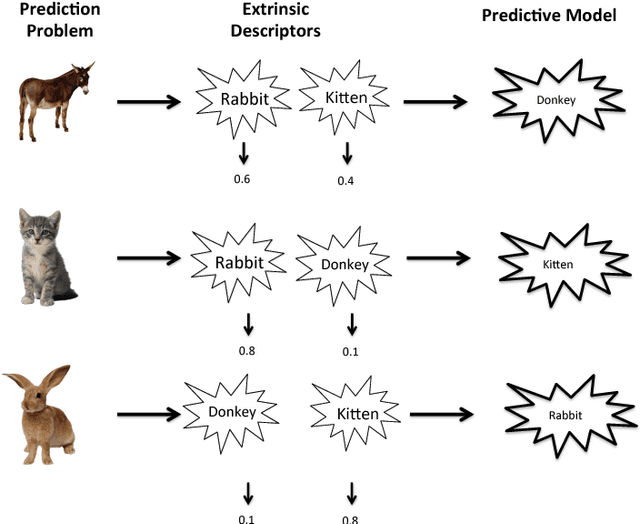

The key to success in machine learning (ML) is the use of effective data representations. Traditionally, data representations were hand-crafted. Recently it has been demonstrated that, given sufficient data, deep neural networks can learn effective implicit representations from simple input representations. However, for most scientific problems, the use of deep learning is not appropriate as the amount of available data is limited, and/or the output models must be explainable. Nevertheless, many scientific problems do have significant amounts of data available on related tasks, which makes them amenable to multi-task learning, i.e. learning many related problems simultaneously. Here we propose a novel and general representation learning approach for multi-task learning that works successfully with small amounts of data. The fundamental new idea is to transform an input intrinsic data representation (i.e., handcrafted features), to an extrinsic representation based on what a pre-trained set of models predict about the examples. This transformation has the dual advantages of producing significantly more accurate predictions, and providing explainable models. To demonstrate the utility of this transformative learning approach, we have applied it to three real-world scientific problems: drug-design (quantitative structure activity relationship learning), predicting human gene expression (across different tissue types and drug treatments), and meta-learning for machine learning (predicting which machine learning methods work best for a given problem). In all three problems, transformative machine learning significantly outperforms the best intrinsic representation.