 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONOPOLY: Learning to Price Public Facilities for Revaluing Private Properties with Large-Scale Urban Data
Nov 27, 2024The value assessment of private properties is an attractive but challenging task which is widely concerned by a majority of people around the world. A prolonged topic among us is ``\textit{how much is my house worth?}''. To answer this question, most experienced agencies would like to price a property given the factors of its attributes as well as the demographics and the public facilities around it. However, no one knows the exact prices of these factors, especially the values of public facilities which may help assess private properties. In this paper, we introduce our newly launched project ``Monopoly'' (named after a classic board game) in which we propose a distributed approach for revaluing private properties by learning to price public facilities (such as hospitals etc.) with the large-scale urban data we have accumulated via Baidu Maps. To be specific, our method organizes many points of interest (POIs) into an undirected weighted graph and formulates multiple factors including the virtual prices of surrounding public facilities as adaptive variables to parallelly estimate the housing prices we know. Then the prices of both public facilities and private properties can be iteratively updated according to the loss of prediction until convergence. We have conducted extensive experiments with the large-scale urban data of several metropolises in China. Results show that our approach outperforms several mainstream methods with significant margins. Further insights from more in-depth discussions demonstrate that the ``Monopoly'' is an innovative application in the interdisciplinary field of business intelligence and urban computing, and it will be beneficial to tens of millions of our users for investments and to the governments for urban planning as well as taxation.
DuMapper: Towards Automatic Verification of Large-Scale POIs with Street Views at Baidu Maps
Nov 27, 2024



With the increased popularity of mobile devices, Web mapping services have become an indispensable tool in our daily lives. To provide user-satisfied services, such as location searches, the point of interest (POI) database is the fundamental infrastructure, as it archives multimodal information on billions of geographic locations closely related to people's lives, such as a shop or a bank. Therefore, verifying the correctness of a large-scale POI database is vital. To achieve this goal, many industrial companies adopt volunteered geographic information (VGI) platforms that enable thousands of crowdworkers and expert mappers to verify POIs seamlessly; but to do so, they have to spend millions of dollars every year. To save the tremendous labor costs, we devised DuMapper, an automatic system for large-scale POI verification with the multimodal street-view data at Baidu Maps. DuMapper takes the signboard image and the coordinates of a real-world place as input to generate a low-dimensional vector, which can be leveraged by ANN algorithms to conduct a more accurate search through billions of archived POIs in the database for verification within milliseconds. It can significantly increase the throughput of POI verification by $50$ times. DuMapper has already been deployed in production since \DuMPOnline, which dramatically improves the productivity and efficiency of POI verification at Baidu Maps. As of December 31, 2021, it has enacted over $405$ million iterations of POI verification within a 3.5-year period, representing an approximate workload of $800$ high-performance expert mappers.
HGAMN: Heterogeneous Graph Attention Matching Network for Multilingual POI Retrieval at Baidu Maps
Sep 05, 2024



The increasing interest in international travel has raised the demand of retrieving point of interests in multiple languages. This is even superior to find local venues such as restaurants and scenic spots in unfamiliar languages when traveling abroad. Multilingual POI retrieval, enabling users to find desired POIs in a demanded language using queries in numerous languages, has become an indispensable feature of today's global map applications such as Baidu Maps. This task is non-trivial because of two key challenges: (1) visiting sparsity and (2) multilingual query-POI matching. To this end, we propose a Heterogeneous Graph Attention Matching Network (HGAMN) to concurrently address both challenges. Specifically, we construct a heterogeneous graph that contains two types of nodes: POI node and query node using the search logs of Baidu Maps. To alleviate challenge \#1, we construct edges between different POI nodes to link the low-frequency POIs with the high-frequency ones, which enables the transfer of knowledge from the latter to the former. To mitigate challenge \#2, we construct edges between POI and query nodes based on the co-occurrences between queries and POIs, where queries in different languages and formulations can be aggregated for individual POIs. Moreover, we develop an attention-based network to jointly learn node representations of the heterogeneous graph and further design a cross-attention module to fuse the representations of both types of nodes for query-POI relevance scoring. Extensive experiments conducted on large-scale real-world datasets from Baidu Maps demonstrate the superiority and effectiveness of HGAMN. In addition, HGAMN has already been deployed in production at Baidu Maps, and it successfully keeps serving hundreds of millions of requests every day.
Exploring the Causality of End-to-End Autonomous Driving
Jul 09, 2024



Deep learning-based models are widely deployed in autonomous driving areas, especially the increasingly noticed end-to-end solutions. However, the black-box property of these models raises concerns about their trustworthiness and safety for autonomous driving, and how to debug the causality has become a pressing concern. Despite some existing research on the explainability of autonomous driving, there is currently no systematic solution to help researchers debug and identify the key factors that lead to the final predicted action of end-to-end autonomous driving. In this work, we propose a comprehensive approach to explore and analyze the causality of end-to-end autonomous driving. First, we validate the essential information that the final planning depends on by using controlled variables and counterfactual interventions for qualitative analysis. Then, we quantitatively assess the factors influencing model decisions by visualizing and statistically analyzing the response of key model inputs. Finally, based on the comprehensive study of the multi-factorial end-to-end autonomous driving system, we have developed a strong baseline and a tool for exploring causality in the close-loop simulator CARLA. It leverages the essential input sources to obtain a well-designed model, resulting in highly competitive capabilities. As far as we know, our work is the first to unveil the mystery of end-to-end autonomous driving and turn the black box into a white one. Thorough close-loop experiments demonstrate that our method can be applied to end-to-end autonomous driving solutions for causality debugging. Code will be available at https://github.com/bdvisl/DriveInsight.
BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space
Jul 08, 2024



World models are receiving increasing attention in autonomous driving for their ability to predict potential future scenarios. In this paper, we present BEVWorld, a novel approach that tokenizes multimodal sensor inputs into a unified and compact Bird's Eye View (BEV) latent space for environment modeling. The world model consists of two parts: the multi-modal tokenizer and the latent BEV sequence diffusion model. The multi-modal tokenizer first encodes multi-modality information and the decoder is able to reconstruct the latent BEV tokens into LiDAR and image observations by ray-casting rendering in a self-supervised manner. Then the latent BEV sequence diffusion model predicts future scenarios given action tokens as conditions. Experiments demonstrate the effectiveness of BEVWorld in autonomous driving tasks, showcasing its capability in generating future scenes and benefiting downstream tasks such as perception and motion prediction. Code will be available at https://github.com/zympsyche/BevWorld.
DuMapNet: An End-to-End Vectorization System for City-Scale Lane-Level Map Generation
Jun 20, 2024



Generating city-scale lane-level maps faces significant challenges due to the intricate urban environments, such as blurred or absent lane markings. Additionally, a standard lane-level map requires a comprehensive organization of lane groupings, encompassing lane direction, style, boundary, and topology, yet has not been thoroughly examined in prior research. These obstacles result in labor-intensive human annotation and high maintenance costs. This paper overcomes these limitations and presents an industrial-grade solution named DuMapNet that outputs standardized, vectorized map elements and their topology in an end-to-end paradigm. To this end, we propose a group-wise lane prediction (GLP) system that outputs vectorized results of lane groups by meticulously tailoring a transformer-based network. Meanwhile, to enhance generalization in challenging scenarios, such as road wear and occlusions, as well as to improve global consistency, a contextual prompts encoder (CPE) module is proposed, which leverages the predicted results of spatial neighborhoods as contextual information. Extensive experiments conducted on large-scale real-world datasets demonstrate the superiority and effectiveness of DuMapNet. Additionally, DuMap-Net has already been deployed in production at Baidu Maps since June 2023, supporting lane-level map generation tasks for over 360 cities while bringing a 95% reduction in costs. This demonstrates that DuMapNet serves as a practical and cost-effective industrial solution for city-scale lane-level map generation.
Polynomial time auditing of statistical subgroup fairness for Gaussian data
Jan 27, 2024
We study the problem of auditing classifiers with the notion of statistical subgroup fairness. Kearns et al. (2018) has shown that the problem of auditing combinatorial subgroups fairness is as hard as agnostic learning. Essentially all work on remedying statistical measures of discrimination against subgroups assumes access to an oracle for this problem, despite the fact that no efficient algorithms are known for it. If we assume the data distribution is Gaussian, or even merely log-concave, then a recent line of work has discovered efficient agnostic learning algorithms for halfspaces. Unfortunately, the boosting-style reductions given by Kearns et al. required the agnostic learning algorithm to succeed on reweighted distributions that may not be log-concave, even if the original data distribution was. In this work, we give positive and negative results on auditing for the Gaussian distribution: On the positive side, we an alternative approach to leverage these advances in agnostic learning and thereby obtain the first polynomial-time approximation scheme (PTAS) for auditing nontrivial combinatorial subgroup fairness: we show how to audit statistical notions of fairness over homogeneous halfspace subgroups when the features are Gaussian. On the negative side, we find that under cryptographic assumptions, no polynomial-time algorithm can guarantee any nontrivial auditing, even under Gaussian feature distributions, for general halfspace subgroups.
Spatial Heterophily Aware Graph Neural Networks
Jun 21, 2023



Graph Neural Networks (GNNs) have been broadly applied in many urban applications upon formulating a city as an urban graph whose nodes are urban objects like regions or points of interest. Recently, a few enhanced GNN architectures have been developed to tackle heterophily graphs where connected nodes are dissimilar. However, urban graphs usually can be observed to possess a unique spatial heterophily property; that is, the dissimilarity of neighbors at different spatial distances can exhibit great diversity. This property has not been explored, while it often exists. To this end, in this paper, we propose a metric, named Spatial Diversity Score, to quantitatively measure the spatial heterophily and show how it can influence the performance of GNNs. Indeed, our experimental investigation clearly shows that existing heterophilic GNNs are still deficient in handling the urban graph with high spatial diversity score. This, in turn, may degrade their effectiveness in urban applications. Along this line, we propose a Spatial Heterophily Aware Graph Neural Network (SHGNN), to tackle the spatial diversity of heterophily of urban graphs. Based on the key observation that spatially close neighbors on the urban graph present a more similar mode of difference to the central node, we first design a rotation-scaling spatial aggregation module, whose core idea is to properly group the spatially close neighbors and separately process each group with less diversity inside. Then, a heterophily-sensitive spatial interaction module is designed to adaptively capture the commonality and diverse dissimilarity in different spatial groups. Extensive experiments on three real-world urban datasets demonstrate the superiority of our SHGNN over several its competitors.
A Contextual Master-Slave Framework on Urban Region Graph for Urban Village Detection
Nov 26, 2022



Urban villages (UVs) refer to the underdeveloped informal settlement falling behind the rapid urbanization in a city. Since there are high levels of social inequality and social risks in these UVs, it is critical for city managers to discover all UVs for making appropriate renovation policies. Existing approaches to detecting UVs are labor-intensive or have not fully addressed the unique challenges in UV detection such as the scarcity of labeled UVs and the diverse urban patterns in different regions. To this end, we first build an urban region graph (URG) to model the urban area in a hierarchically structured way. Then, we design a novel contextual master-slave framework to effectively detect the urban village from the URG. The core idea of such a framework is to firstly pre-train a basis (or master) model over the URG, and then to adaptively derive specific (or slave) models from the basis model for different regions. The proposed framework can learn to balance the generality and specificity for UV detection in an urban area. Finally, we conduct extensive experiments in three cities to demonstrate the effectiveness of our approach.
DuETA: Traffic Congestion Propagation Pattern Modeling via Efficient Graph Learning for ETA Prediction at Baidu Maps
Aug 15, 2022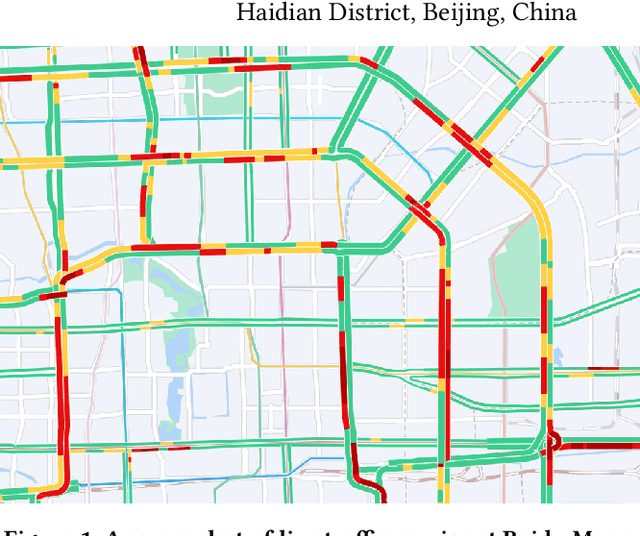
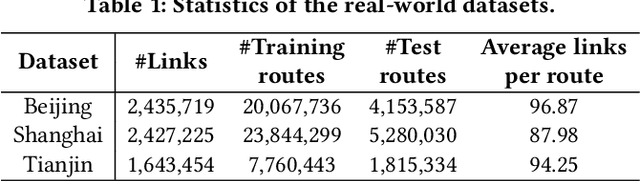
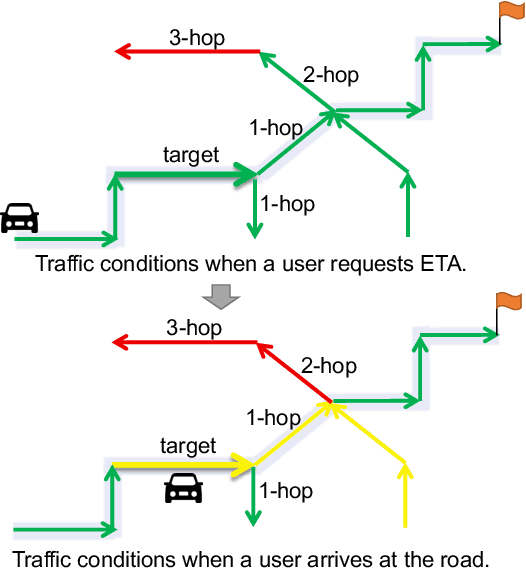
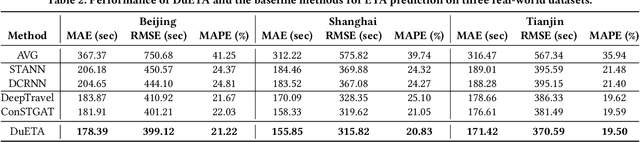
Estimated time of arrival (ETA) prediction, also known as travel time estimation, is a fundamental task for a wide range of intelligent transportation applications, such as navigation, route planning, and ride-hailing services. To accurately predict the travel time of a route, it is essential to take into account both contextual and predictive factors, such as spatial-temporal interaction, driving behavior, and traffic congestion propagation inference. The ETA prediction models previously deployed at Baidu Maps have addressed the factors of spatial-temporal interaction (ConSTGAT) and driving behavior (SSML). In this work, we focus on modeling traffic congestion propagation patterns to improve ETA performance. Traffic congestion propagation pattern modeling is challenging, and it requires accounting for impact regions over time and cumulative effect of delay variations over time caused by traffic events on the road network. In this paper, we present a practical industrial-grade ETA prediction framework named DuETA. Specifically, we construct a congestion-sensitive graph based on the correlations of traffic patterns, and we develop a route-aware graph transformer to directly learn the long-distance correlations of the road segments. This design enables DuETA to capture the interactions between the road segment pairs that are spatially distant but highly correlated with traffic conditions. Extensive experiments are conducted on large-scale, real-world datasets collected from Baidu Maps. Experimental results show that ETA prediction can significantly benefit from the learned traffic congestion propagation patterns. In addition, DuETA has already been deployed in production at Baidu Maps, serving billions of requests every day. This demonstrates that DuETA is an industrial-grade and robust solution for large-scale ETA prediction services.