 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Data Sciences with Natural Language and SageCopilot: Practices and Lessons Learned
Jul 21, 2024



While the field of NL2SQL has made significant advancements in translating natural language instructions into executable SQL scripts for data querying and processing, achieving full automation within the broader data science pipeline - encompassing data querying, analysis, visualization, and reporting - remains a complex challenge. This study introduces SageCopilot, an advanced, industry-grade system system that automates the data science pipeline by integrating Large Language Models (LLMs), Autonomous Agents (AutoAgents), and Language User Interfaces (LUIs). Specifically, SageCopilot incorporates a two-phase design: an online component refining users' inputs into executable scripts through In-Context Learning (ICL) and running the scripts for results reporting & visualization, and an offline preparing demonstrations requested by ICL in the online phase. A list of trending strategies such as Chain-of-Thought and prompt-tuning have been used to augment SageCopilot for enhanced performance. Through rigorous testing and comparative analysis against prompt-based solutions, SageCopilot has been empirically validated to achieve superior end-to-end performance in generating or executing scripts and offering results with visualization, backed by real-world datasets. Our in-depth ablation studies highlight the individual contributions of various components and strategies used by SageCopilot to the end-to-end correctness for data sciences.
Cross-Model Consensus of Explanations and Beyond for Image Classification Models: An Empirical Study
Sep 02, 2021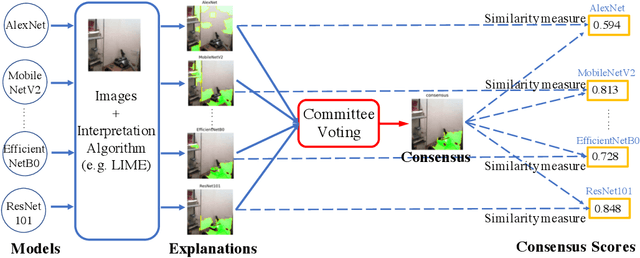

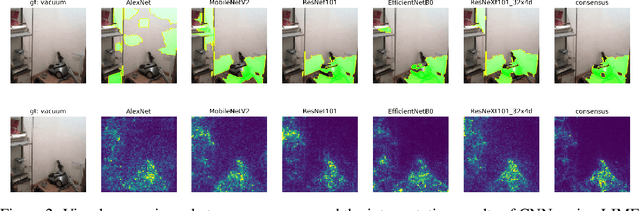
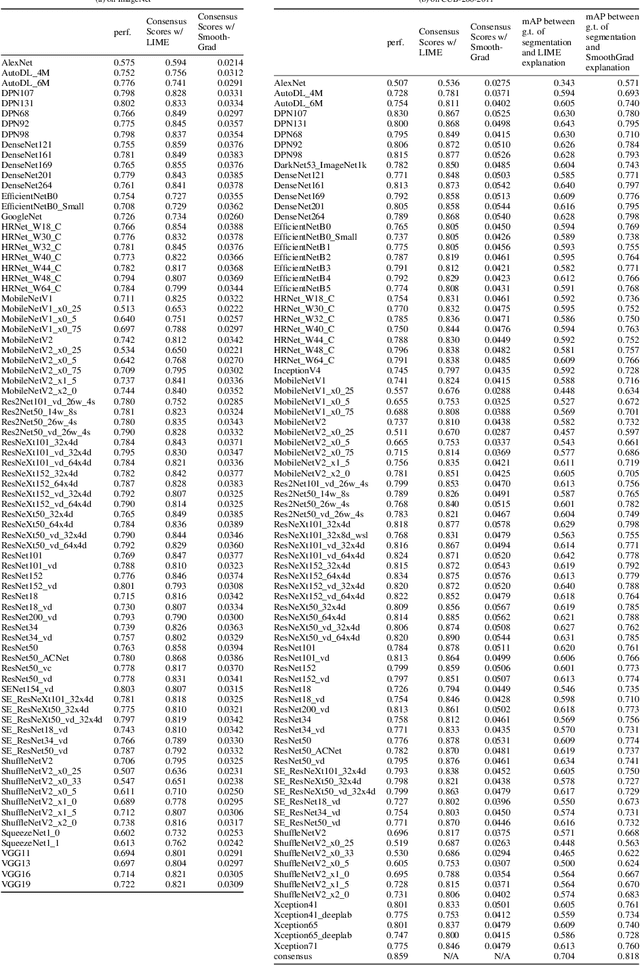
Existing interpretation algorithms have found that, even deep models make the same and right predictions on the same image, they might rely on different sets of input features for classification. However, among these sets of features, some common features might be used by the majority of models. In this paper, we are wondering what are the common features used by various models for classification and whether the models with better performance may favor those common features. For this purpose, our works uses an interpretation algorithm to attribute the importance of features (e.g., pixels or superpixels) as explanations, and proposes the cross-model consensus of explanations to capture the common features. Specifically, we first prepare a set of deep models as a committee, then deduce the explanation for every model, and obtain the consensus of explanations across the entire committee through voting. With the cross-model consensus of explanations, we conduct extensive experiments using 80+ models on 5 datasets/tasks. We find three interesting phenomena as follows: (1) the consensus obtained from image classification models is aligned with the ground truth of semantic segmentation; (2) we measure the similarity of the explanation result of each model in the committee to the consensus (namely consensus score), and find positive correlations between the consensus score and model performance; and (3) the consensus score coincidentally correlates to the interpretability.
From Distributed Machine Learning to Federated Learning: A Survey
May 10, 2021



In recent years, data and computing resources are typically distributed in the devices of end users, various regions or organizations. Because of laws or regulations, the distributed data and computing resources cannot be directly shared among different regions or organizations for machine learning tasks. Federated learning emerges as an efficient approach to exploit distributed data and computing resources, so as to collaboratively train machine learning models, while obeying the laws and regulations and ensuring data security and data privacy. In this paper, we provide a comprehensive survey of existing works for federated learning. We propose a functional architecture of federated learning systems and a taxonomy of related techniques. Furthermore, we present the distributed training, data communication, and security of FL systems. Finally, we analyze their limitations and propose future research directions.