 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLawBench: Evaluating LLMs Through Multi-Turn Legal Consultation
Jun 11, 2026Lawyer-client consultation is a critical starting point for legal services. Effective legal assistance hinges on eliciting sufficient and truthful information from clients in order to devise strategies that best protect their interests. This task requires Large Language Models (LLMs) not only to perform robust legal reasoning, but also to strategically elicit material facts through multi-turn interactions and effectively guide clients with diverse personalities. Yet existing legal benchmarks overlook this interactive capability. To fill this gap, we introduce DLawBench, a diagnostic benchmark for real-world legal consultation. Drawing on realistic client behavior, we characterize lawyer-client interactions into four types: Cooperative, Dependent, Withdrawn, and Adversarial. Using dialogues grounded in real cases, DLawBench evaluates whether LLMs can effectively conduct legal consultation under realistic conditions. DLawBench comprises 461 cases from Chinese and U.S. law, 5,532 paired fact entries, 3,411 inquiry rubrics, and 3,348 issue-resolution rubrics, and evaluates 26 representative LLMs. Systematic experiments show substantial headroom: the best-performing model, GPT-5.5, achieves only 0.562 on consultation-grounded legal reasoning. More importantly, DLawBench exposes both sycophancy in legal consultation and a paradox: models perform worse when clients need guidance most.
TCP-MCP: Landscape-Guided Co-Evolution of Prompts and Communication Topologies for Multi-Agent Systems
May 27, 2026Effective multi-agent systems cannot be designed by selecting prompts or communication graphs in isolation. Agent behavior depends on the information an agent receives, while the usefulness of a communication edge depends on how the receiving agent interprets and uses that information. We propose \textbf{TCP-MCP} (Topology-Coupled Prompting for Multi-Agent Collaborative Problem-Solving), a co-evolution framework that searches agent prompts and communication topologies as a unified genome. TCP-MCP uses an initialization-time landscape probe to calibrate early search behavior, and then relies on Pareto-front diagnostics to adapt exploration under three objectives: task performance, token cost, and structural complexity. Using the same DeepSeek-V3.2 backbone across all methods, TCP-MCP achieves 82.66\%, 89.96\%, and 96.61\% accuracy on MMLU-Pro, MMLU, and GSM8K, respectively. Across the three benchmarks, it consistently outperforms automated graph-generation baselines and achieves competitive accuracy relative to debate-style systems, while using up to 5.69$\times$ fewer tokens than those systems at the reported operating points. These results show that jointly evolving prompts and communication structure provides a practical route to cost-aware and task-adaptive multi-agent system design in controlled evaluations.
The Labyrinth and the Thread: Rethinking Regularizations in Sequential Knowledge Editing for Large Language Models
May 26, 2026Sequential editing of structured knowledge in large language models allows targeted factual updates without retraining, yet existing methods often rely on complex regularization or constraint mechanisms whose necessity remains unclear. In this work, we systematically investigate the mechanisms underlying effective and stable sequential editing. Specifically, we first analyze the empirical success of AlphaEdit and establish, via a rigorous optimization analysis, the formal equivalence between one-time and sequential editing. Building on this insight, we generalize the equivalence to a broader class of editing objectives, demonstrating that stability emerges naturally from properly accounting for accumulated editing constraints, rather than from specialized regularization or null-space operations. We empirically confirm that many commonly used regularization strategies are unnecessary for reliable sequential updates. Furthermore, we extend our framework to handle conflicting edits, ensuring robust and consistent behavior under contradictory updates. Ultimately, our work provides Ariadne's thread through the labyrinth of sequential editing, charting a path toward simpler, more interpretable, and dependable knowledge updates. Our code is available at https://github.com/Wangzzzzzzzz/OTE-SE-Alignment.
A Computational Model of Message Sensation Value in Short Video Multimodal Features that Predicts Sensory and Behavioral Engagement
Apr 21, 2026The contemporary media landscape is characterized by sensational short videos. While prior research examines the effects of individual multimodal features, the collective impact of multimodal features on viewer engagement with short videos remains unknown. Grounded in the theoretical framework of Message Sensation Value (MSV), this study develops and tests a computational model of MSV with multimodal feature analysis and human evaluation of 1,200 short videos. This model that predicts sensory and behavioral engagement was further validated across two unseen datasets from three short video platforms (combined N = 14,492). While MSV is positively associated with sensory engagement, it shows an inverted U-shaped relationship with behavioral engagement: Higher MSV elicits stronger sensory stimulation, but moderate MSV optimizes behavioral engagement. This research advances the theoretical understanding of short video engagement and introduces a robust computational tool for short video research.
Dynamic Whole-Body Dancing with Humanoid Robots -- A Model-Based Control Approach
Apr 05, 2026This paper presents an integrated model-based framework for generating and executing dynamic whole-body dance motions on humanoid robots. The framework operates in two stages: offline motion generation and online motion execution, both leveraging future state prediction to enable robust and dynamic dance motions in real-world environments. In the offline motion generation stage, human dance demonstrations are captured via a motion capture (MoCap) system, retargeted to the robot by solving a Quadratic Programming (QP) problem, and further refined using Trajectory Optimization (TO) to ensure dynamic feasibility. In the online motion execution stage, a centroidal dynamics-based Model Predictive Control (MPC) framework tracks the planned motions in real time and proactively adjusts swing foot placement to adapt to real world disturbances. We validate our framework on the full-size humanoid robot Kuavo 4Pro, demonstrating the dynamic dance motions both in simulation and in a four-minute live public performance with a team of four robots. Experimental results show that longer prediction horizons improve both motion expressiveness in planning and stability in execution.
WiSLAT: A Simultaneous Device Localization and Target Tracking Method for Wi-Fi Systems
Mar 18, 2026It has been shown that the channel state information (CSI) of a Wi-Fi system can be exploited to localize Wi-Fi devices or track trajectory of a moving target. In the existing literature, both sensing tasks are treated separately and some prior information is usually requested, including the signal fingerprints, the locations of some anchor devices in the Wi-Fi system, and etc. In the proposed WiSLAT method, however, it is shown that both sensing tasks can assist each other, such that the request on prior system information can be eliminated. Particularly, in a Wi-Fi system with an access point (AP) and at least three stations, where the locations of the stations are unknown, the WiSLAT is designed to detect the Doppler frequencies of the downlink CSI at the stations, such that their locations and the trajectory of the target with respect to the AP can be inferred. The joint detection can be conducted by searching the optimal stations' locations and target's trajectory, such that their corresponding Doppler frequencies fit the observed ones best. Due to the tremendous non-convex search space, a low-complexity sub-optimal algorithm integrating alternate optimization, extended Kalman filter and density-based clustering is proposed in WiSLAT. Experiments conducted in indoor environments demonstrate the effectiveness of WiSLAT, achieving a median trajectory-tracking error of 0.68 m.
ECO: Energy-Constrained Optimization with Reinforcement Learning for Humanoid Walking
Feb 06, 2026Achieving stable and energy-efficient locomotion is essential for humanoid robots to operate continuously in real-world applications. Existing MPC and RL approaches often rely on energy-related metrics embedded within a multi-objective optimization framework, which require extensive hyperparameter tuning and often result in suboptimal policies. To address these challenges, we propose ECO (Energy-Constrained Optimization), a constrained RL framework that separates energy-related metrics from rewards, reformulating them as explicit inequality constraints. This method provides a clear and interpretable physical representation of energy costs, enabling more efficient and intuitive hyperparameter tuning for improved energy efficiency. ECO introduces dedicated constraints for energy consumption and reference motion, enforced by the Lagrangian method, to achieve stable, symmetric, and energy-efficient walking for humanoid robots. We evaluated ECO against MPC, standard RL with reward shaping, and four state-of-the-art constrained RL methods. Experiments, including sim-to-sim and sim-to-real transfers on the kid-sized humanoid robot BRUCE, demonstrate that ECO significantly reduces energy consumption compared to baselines while maintaining robust walking performance. These results highlight a substantial advancement in energy-efficient humanoid locomotion. All experimental demonstrations can be found on the project website: https://sites.google.com/view/eco-humanoid.
Towards Bridging the Gap between Large-Scale Pretraining and Efficient Finetuning for Humanoid Control
Jan 29, 2026Reinforcement learning (RL) is widely used for humanoid control, with on-policy methods such as Proximal Policy Optimization (PPO) enabling robust training via large-scale parallel simulation and, in some cases, zero-shot deployment to real robots. However, the low sample efficiency of on-policy algorithms limits safe adaptation to new environments. Although off-policy RL and model-based RL have shown improved sample efficiency, the gap between large-scale pretraining and efficient finetuning on humanoids still exists. In this paper, we find that off-policy Soft Actor-Critic (SAC), with large-batch update and a high Update-To-Data (UTD) ratio, reliably supports large-scale pretraining of humanoid locomotion policies, achieving zero-shot deployment on real robots. For adaptation, we demonstrate that these SAC-pretrained policies can be finetuned in new environments and out-of-distribution tasks using model-based methods. Data collection in the new environment executes a deterministic policy while stochastic exploration is instead confined to a physics-informed world model. This separation mitigates the risks of random exploration during adaptation while preserving exploratory coverage for improvement. Overall, the approach couples the wall-clock efficiency of large-scale simulation during pretraining with the sample efficiency of model-based learning during fine-tuning.
PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice
Jan 23, 2026As large language models (LLMs) are increasingly applied to legal domain-specific tasks, evaluating their ability to perform legal work in real-world settings has become essential. However, existing legal benchmarks rely on simplified and highly standardized tasks, failing to capture the ambiguity, complexity, and reasoning demands of real legal practice. Moreover, prior evaluations often adopt coarse, single-dimensional metrics and do not explicitly assess fine-grained legal reasoning. To address these limitations, we introduce PLawBench, a Practical Law Benchmark designed to evaluate LLMs in realistic legal practice scenarios. Grounded in real-world legal workflows, PLawBench models the core processes of legal practitioners through three task categories: public legal consultation, practical case analysis, and legal document generation. These tasks assess a model's ability to identify legal issues and key facts, perform structured legal reasoning, and generate legally coherent documents. PLawBench comprises 850 questions across 13 practical legal scenarios, with each question accompanied by expert-designed evaluation rubrics, resulting in approximately 12,500 rubric items for fine-grained assessment. Using an LLM-based evaluator aligned with human expert judgments, we evaluate 10 state-of-the-art LLMs. Experimental results show that none achieves strong performance on PLawBench, revealing substantial limitations in the fine-grained legal reasoning capabilities of current LLMs and highlighting important directions for future evaluation and development of legal LLMs. Data is available at: https://github.com/skylenage/PLawbench.
Large Language Models for Planning: A Comprehensive and Systematic Survey
May 26, 2025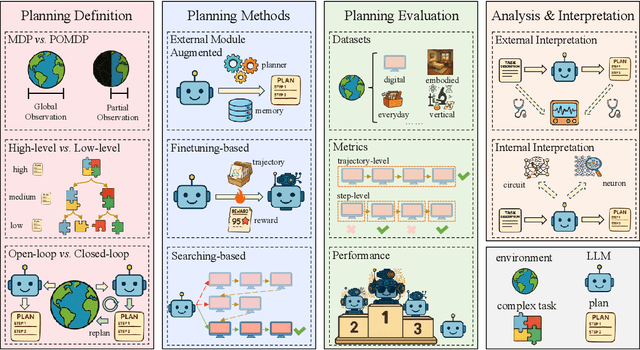
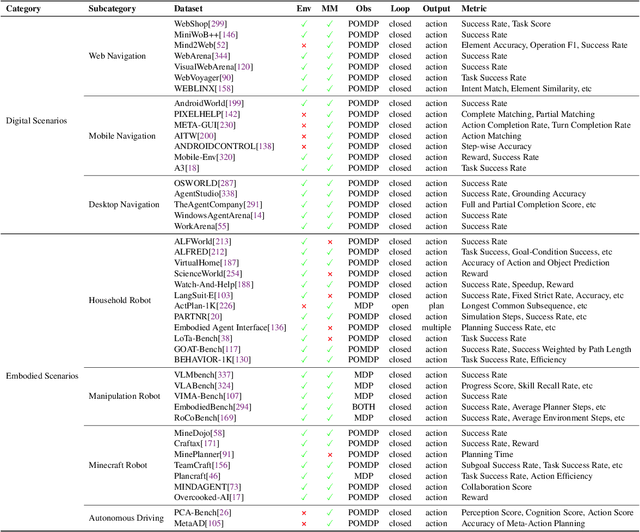
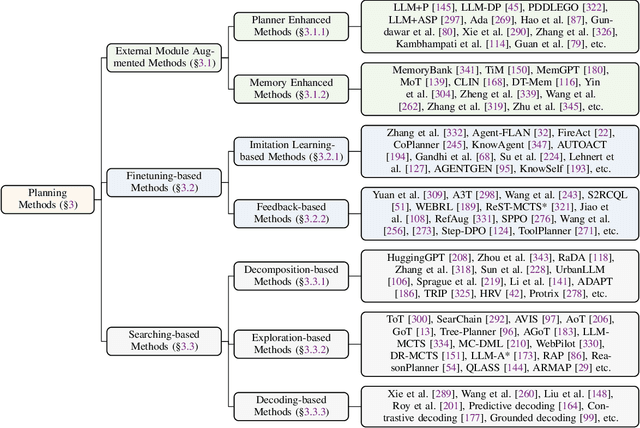
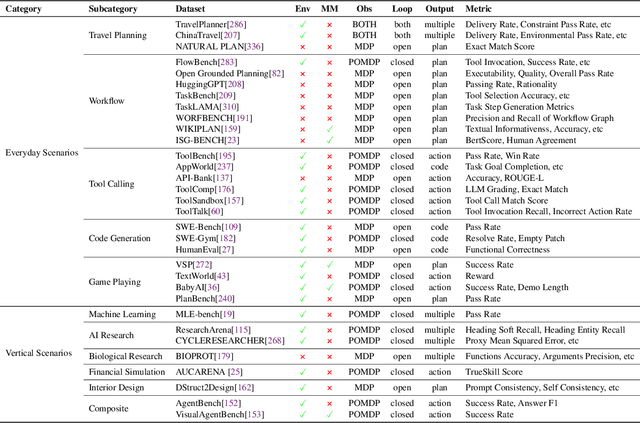
Planning represents a fundamental capability of intelligent agents, requiring comprehensive environmental understanding, rigorous logical reasoning, and effective sequential decision-making. While Large Language Models (LLMs) have demonstrated remarkable performance on certain planning tasks, their broader application in this domain warrants systematic investigation. This paper presents a comprehensive review of LLM-based planning. Specifically, this survey is structured as follows: First, we establish the theoretical foundations by introducing essential definitions and categories about automated planning. Next, we provide a detailed taxonomy and analysis of contemporary LLM-based planning methodologies, categorizing them into three principal approaches: 1) External Module Augmented Methods that combine LLMs with additional components for planning, 2) Finetuning-based Methods that involve using trajectory data and feedback signals to adjust LLMs in order to improve their planning abilities, and 3) Searching-based Methods that break down complex tasks into simpler components, navigate the planning space, or enhance decoding strategies to find the best solutions. Subsequently, we systematically summarize existing evaluation frameworks, including benchmark datasets, evaluation metrics and performance comparisons between representative planning methods. Finally, we discuss the underlying mechanisms enabling LLM-based planning and outline promising research directions for this rapidly evolving field. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this field.