 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering GUI Agents via Autonomous Experience Exploration and Hindsight Experience Utilization for Task Planning
Jun 25, 2026Multimodal web agents can assist humans in operating repetitive GUI tasks, where effective task planning is essential for decomposing complex tasks into executable actions. While small open source MLLMs are cost efficient and privacy preserving compared with commercial large models, they suffer from weak planning and limited cross website generalization. To address these limitations, we introduce the planning experience exploration and utilization (PEEU) method, which autonomously explores environments to discover experiences and utilizes hindsight experience to synthesize strictly aligned, high level training data. To quantitatively analyze the generalization behaviors driving this performance, we propose the task decomposition hierarchical analysis framework (TDHAF) to systematically study compositional generalization across three task granularities: low, middle and high levels. Our analysis reveals that mastering low level atomic skills does not guarantee high level planning competence, while high level task training yields stronger OOD generalization. Experiments on real world benchmarks demonstrate PEEU's superior effectiveness: our 7B model achieves 30.6% accuracy, outperforming the much larger Qwen2.5-VL-32B model. These demonstrate constructing hindsight high level tasks and leveraging experiences is crucial for OOD planning abilities of small MLLMs.
Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application
Jun 10, 2026Environments serve as interactive systems for large language model (LLM) based agents across diverse scenarios and play a crucial role in driving the continual evolution of model capabilities. Despite this importance, existing work lacks a systematic categorization and deep analysis. This paper systematically studies current researches on agentic environments from the perspective of the environment engineering lifecycle, covering their modeling, synthesis, evaluation and application. Specifically, the paper first introduces representative environments from the perspectives of eight attributes and eight domains, providing detailed analyses of their development paths and highlighting their core capabilities. Second, for automated environment synthesis, two paradigms are introduced, such as symbolic synthesis and neural synthesis. This paper also shows different environment evaluation methods in each paradigm. Thirdly, the corresponding environment applications from the perspective of agent-environment co-evolution are discussed. In specific, the paper characterizes the primary pathways for agent evolution in dynamic environments from four complementary perspectives: memory-centric experience evolution, orchestration-centric workflow evolution, trajectory-centric offline evolution, and exploration-centric online evolution. And three paradigms of environment evolution are identified, namely neural-driven, difficulty-driven, and scaling-driven approaches. At last, several promising future directions are discussed, including Environment-as-a-Service, Multi-agent Environments, and Neural-Symbolic Environments.
Large Language Models for Planning: A Comprehensive and Systematic Survey
May 26, 2025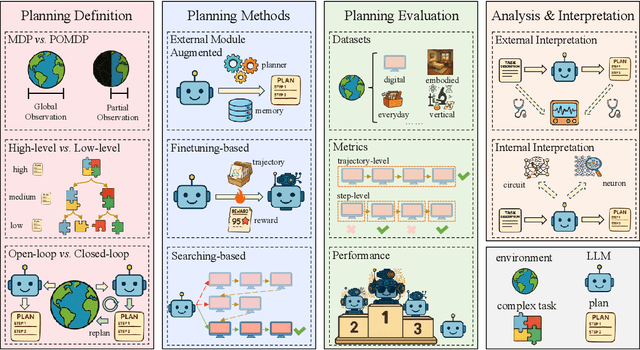
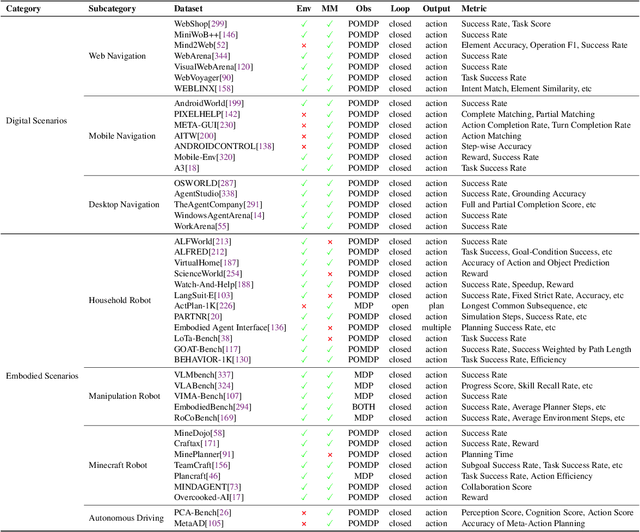
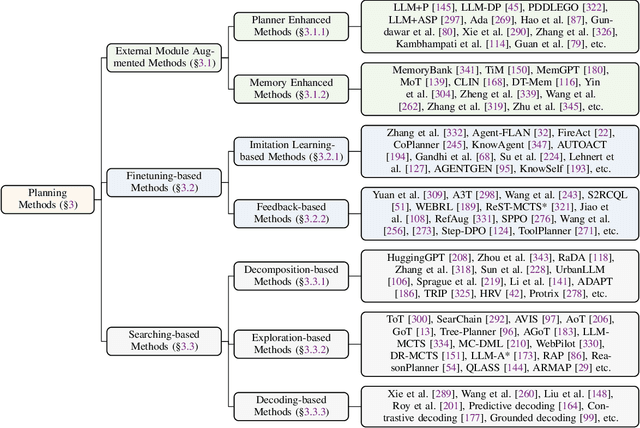
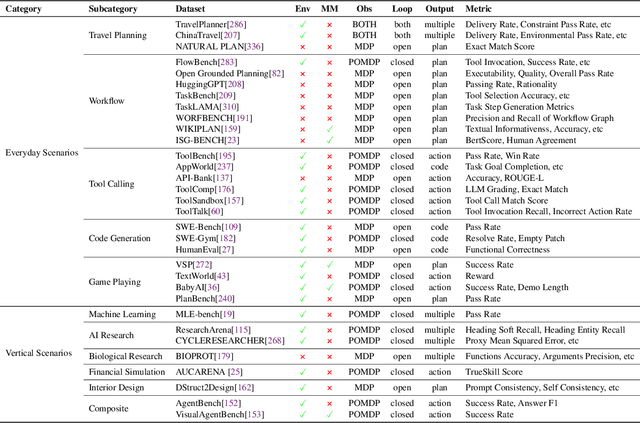
Planning represents a fundamental capability of intelligent agents, requiring comprehensive environmental understanding, rigorous logical reasoning, and effective sequential decision-making. While Large Language Models (LLMs) have demonstrated remarkable performance on certain planning tasks, their broader application in this domain warrants systematic investigation. This paper presents a comprehensive review of LLM-based planning. Specifically, this survey is structured as follows: First, we establish the theoretical foundations by introducing essential definitions and categories about automated planning. Next, we provide a detailed taxonomy and analysis of contemporary LLM-based planning methodologies, categorizing them into three principal approaches: 1) External Module Augmented Methods that combine LLMs with additional components for planning, 2) Finetuning-based Methods that involve using trajectory data and feedback signals to adjust LLMs in order to improve their planning abilities, and 3) Searching-based Methods that break down complex tasks into simpler components, navigate the planning space, or enhance decoding strategies to find the best solutions. Subsequently, we systematically summarize existing evaluation frameworks, including benchmark datasets, evaluation metrics and performance comparisons between representative planning methods. Finally, we discuss the underlying mechanisms enabling LLM-based planning and outline promising research directions for this rapidly evolving field. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this field.
RAG-RewardBench: Benchmarking Reward Models in Retrieval Augmented Generation for Preference Alignment
Dec 18, 2024



Despite the significant progress made by existing retrieval augmented language models (RALMs) in providing trustworthy responses and grounding in reliable sources, they often overlook effective alignment with human preferences. In the alignment process, reward models (RMs) act as a crucial proxy for human values to guide optimization. However, it remains unclear how to evaluate and select a reliable RM for preference alignment in RALMs. To this end, we propose RAG-RewardBench, the first benchmark for evaluating RMs in RAG settings. First, we design four crucial and challenging RAG-specific scenarios to assess RMs, including multi-hop reasoning, fine-grained citation, appropriate abstain, and conflict robustness. Then, we incorporate 18 RAG subsets, six retrievers, and 24 RALMs to increase the diversity of data sources. Finally, we adopt an LLM-as-a-judge approach to improve preference annotation efficiency and effectiveness, exhibiting a strong correlation with human annotations. Based on the RAG-RewardBench, we conduct a comprehensive evaluation of 45 RMs and uncover their limitations in RAG scenarios. Additionally, we also reveal that existing trained RALMs show almost no improvement in preference alignment, highlighting the need for a shift towards preference-aligned training.We release our benchmark and code publicly at https://huggingface.co/datasets/jinzhuoran/RAG-RewardBench/ for future work.
A Troublemaker with Contagious Jailbreak Makes Chaos in Honest Towns
Oct 21, 2024With the development of large language models, they are widely used as agents in various fields. A key component of agents is memory, which stores vital information but is susceptible to jailbreak attacks. Existing research mainly focuses on single-agent attacks and shared memory attacks. However, real-world scenarios often involve independent memory. In this paper, we propose the Troublemaker Makes Chaos in Honest Town (TMCHT) task, a large-scale, multi-agent, multi-topology text-based attack evaluation framework. TMCHT involves one attacker agent attempting to mislead an entire society of agents. We identify two major challenges in multi-agent attacks: (1) Non-complete graph structure, (2) Large-scale systems. We attribute these challenges to a phenomenon we term toxicity disappearing. To address these issues, we propose an Adversarial Replication Contagious Jailbreak (ARCJ) method, which optimizes the retrieval suffix to make poisoned samples more easily retrieved and optimizes the replication suffix to make poisoned samples have contagious ability. We demonstrate the superiority of our approach in TMCHT, with 23.51%, 18.95%, and 52.93% improvements in line topology, star topology, and 100-agent settings. Encourage community attention to the security of multi-agent systems.
Unlocking the Future: Exploring Look-Ahead Planning Mechanistic Interpretability in Large Language Models
Jun 23, 2024Planning, as the core module of agents, is crucial in various fields such as embodied agents, web navigation, and tool using. With the development of large language models (LLMs), some researchers treat large language models as intelligent agents to stimulate and evaluate their planning capabilities. However, the planning mechanism is still unclear. In this work, we focus on exploring the look-ahead planning mechanism in large language models from the perspectives of information flow and internal representations. First, we study how planning is done internally by analyzing the multi-layer perception (MLP) and multi-head self-attention (MHSA) components at the last token. We find that the output of MHSA in the middle layers at the last token can directly decode the decision to some extent. Based on this discovery, we further trace the source of MHSA by information flow, and we reveal that MHSA mainly extracts information from spans of the goal states and recent steps. According to information flow, we continue to study what information is encoded within it. Specifically, we explore whether future decisions have been encoded in advance in the representation of flow. We demonstrate that the middle and upper layers encode a few short-term future decisions to some extent when planning is successful. Overall, our research analyzes the look-ahead planning mechanisms of LLMs, facilitating future research on LLMs performing planning tasks.