 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathMixup: Boosting LLM Mathematical Reasoning with Difficulty-Controllable Data Synthesis and Curriculum Learning
Jan 14, 2026In mathematical reasoning tasks, the advancement of Large Language Models (LLMs) relies heavily on high-quality training data with clearly defined and well-graded difficulty levels. However, existing data synthesis methods often suffer from limited diversity and lack precise control over problem difficulty, making them insufficient for supporting efficient training paradigms such as curriculum learning. To address these challenges, we propose MathMixup, a novel data synthesis paradigm that systematically generates high-quality, difficulty-controllable mathematical reasoning problems through hybrid and decomposed strategies. Automated self-checking and manual screening are incorporated to ensure semantic clarity and a well-structured difficulty gradient in the synthesized data. Building on this, we construct the MathMixupQA dataset and design a curriculum learning strategy that leverages these graded problems, supporting flexible integration with other datasets. Experimental results show that MathMixup and its curriculum learning strategy significantly enhance the mathematical reasoning performance of LLMs. Fine-tuned Qwen2.5-7B achieves an average score of 52.6\% across seven mathematical benchmarks, surpassing previous state-of-the-art methods. These results fully validate the effectiveness and broad applicability of MathMixup in improving the mathematical reasoning abilities of LLMs and advancing data-centric curriculum learning.
Beyond Accuracy: Evaluating Grounded Visual Evidence in Thinking with Images
Jan 14, 2026Despite the remarkable progress of Vision-Language Models (VLMs) in adopting "Thinking-with-Images" capabilities, accurately evaluating the authenticity of their reasoning process remains a critical challenge. Existing benchmarks mainly rely on outcome-oriented accuracy, lacking the capability to assess whether models can accurately leverage fine-grained visual cues for multi-step reasoning. To address these limitations, we propose ViEBench, a process-verifiable benchmark designed to evaluate faithful visual reasoning. Comprising 200 multi-scenario high-resolution images with expert-annotated visual evidence, ViEBench uniquely categorizes tasks by difficulty into perception and reasoning dimensions, where reasoning tasks require utilizing localized visual details with prior knowledge. To establish comprehensive evaluation criteria, we introduce a dual-axis matrix that provides fine-grained metrics through four diagnostic quadrants, enabling transparent diagnosis of model behavior across varying task complexities. Our experiments yield several interesting observations: (1) VLMs can sometimes produce correct final answers despite grounding on irrelevant regions, and (2) they may successfully locate the correct evidence but still fail to utilize it to reach accurate conclusions. Our findings demonstrate that ViEBench can serve as a more explainable and practical benchmark for comprehensively evaluating the effectiveness agentic VLMs. The codes will be released at: https://github.com/Xuchen-Li/ViEBench.
MATrack: Efficient Multiscale Adaptive Tracker for Real-Time Nighttime UAV Operations
Oct 24, 2025Nighttime UAV tracking faces significant challenges in real-world robotics operations. Low-light conditions not only limit visual perception capabilities, but cluttered backgrounds and frequent viewpoint changes also cause existing trackers to drift or fail during deployment. To address these difficulties, researchers have proposed solutions based on low-light enhancement and domain adaptation. However, these methods still have notable shortcomings in actual UAV systems: low-light enhancement often introduces visual artifacts, domain adaptation methods are computationally expensive and existing lightweight designs struggle to fully leverage dynamic object information. Based on an in-depth analysis of these key issues, we propose MATrack-a multiscale adaptive system designed specifically for nighttime UAV tracking. MATrack tackles the main technical challenges of nighttime tracking through the collaborative work of three core modules: Multiscale Hierarchy Blende (MHB) enhances feature consistency between static and dynamic templates. Adaptive Key Token Gate accurately identifies object information within complex backgrounds. Nighttime Template Calibrator (NTC) ensures stable tracking performance over long sequences. Extensive experiments show that MATrack achieves a significant performance improvement. On the UAVDark135 benchmark, its precision, normalized precision and AUC surpass state-of-the-art (SOTA) methods by 5.9%, 5.4% and 4.2% respectively, while maintaining a real-time processing speed of 81 FPS. Further tests on a real-world UAV platform validate the system's reliability, demonstrating that MATrack can provide stable and effective nighttime UAV tracking support for critical robotics applications such as nighttime search and rescue and border patrol.
Look Less, Reason More: Rollout-Guided Adaptive Pixel-Space Reasoning
Oct 02, 2025Vision-Language Models (VLMs) excel at many multimodal tasks, yet they frequently struggle with tasks requiring precise understanding and handling of fine-grained visual elements. This is mainly due to information loss during image encoding or insufficient attention to critical regions. Recent work has shown promise by incorporating pixel-level visual information into the reasoning process, enabling VLMs to access high-resolution visual details during their thought process. However, this pixel-level information is often overused, leading to inefficiency and distraction from irrelevant visual details. To address these challenges, we propose the first framework for adaptive pixel reasoning that dynamically determines necessary pixel-level operations based on the input query. Specifically, we first apply operation-aware supervised fine-tuning to establish baseline competence in textual reasoning and visual operations, then design a novel rollout-guided reinforcement learning framework relying on feedback of the model's own responses, which enables the VLM to determine when pixel operations should be invoked based on query difficulty. Experiments on extensive multimodal reasoning benchmarks show that our model achieves superior performance while significantly reducing unnecessary visual operations. Impressively, our model achieves 73.4\% accuracy on HR-Bench 4K while maintaining a tool usage ratio of only 20.1\%, improving accuracy and simultaneously reducing tool usage by 66.5\% compared to the previous methods.
CausalStep: A Benchmark for Explicit Stepwise Causal Reasoning in Videos
Jul 22, 2025Recent advances in large language models (LLMs) have improved reasoning in text and image domains, yet achieving robust video reasoning remains a significant challenge. Existing video benchmarks mainly assess shallow understanding and reasoning and allow models to exploit global context, failing to rigorously evaluate true causal and stepwise reasoning. We present CausalStep, a benchmark designed for explicit stepwise causal reasoning in videos. CausalStep segments videos into causally linked units and enforces a strict stepwise question-answer (QA) protocol, requiring sequential answers and preventing shortcut solutions. Each question includes carefully constructed distractors based on error type taxonomy to ensure diagnostic value. The benchmark features 100 videos across six categories and 1,852 multiple-choice QA pairs. We introduce seven diagnostic metrics for comprehensive evaluation, enabling precise diagnosis of causal reasoning capabilities. Experiments with leading proprietary and open-source models, as well as human baselines, reveal a significant gap between current models and human-level stepwise reasoning. CausalStep provides a rigorous benchmark to drive progress in robust and interpretable video reasoning.
Large Language Models for Planning: A Comprehensive and Systematic Survey
May 26, 2025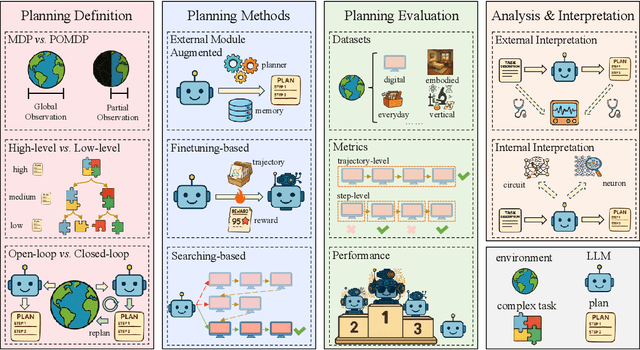
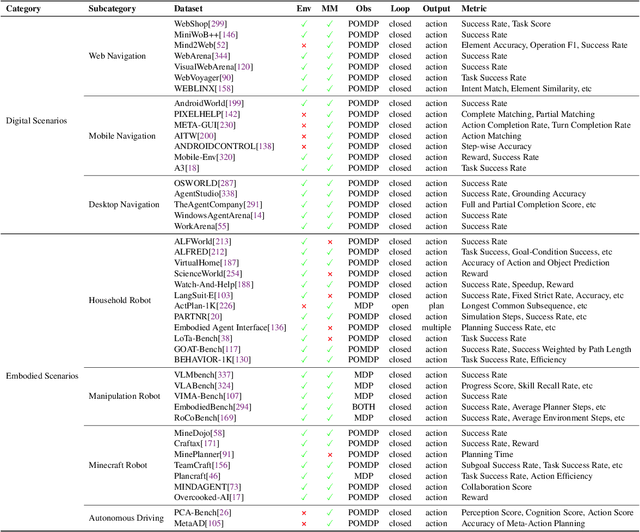
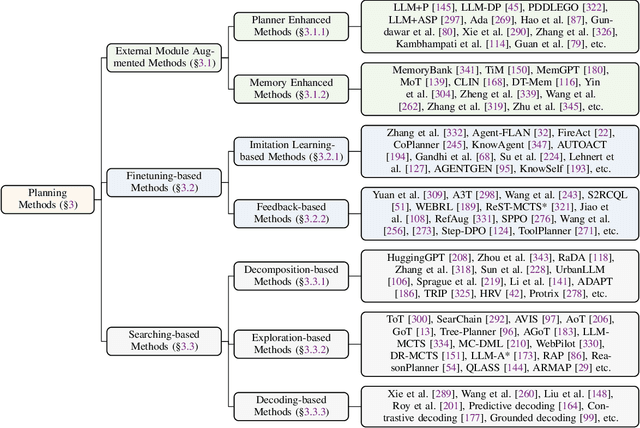
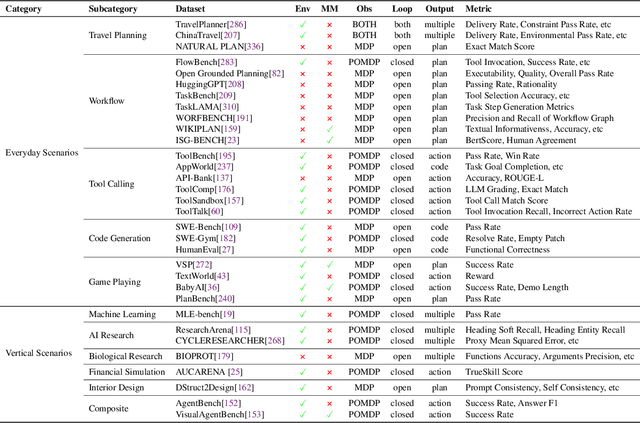
Planning represents a fundamental capability of intelligent agents, requiring comprehensive environmental understanding, rigorous logical reasoning, and effective sequential decision-making. While Large Language Models (LLMs) have demonstrated remarkable performance on certain planning tasks, their broader application in this domain warrants systematic investigation. This paper presents a comprehensive review of LLM-based planning. Specifically, this survey is structured as follows: First, we establish the theoretical foundations by introducing essential definitions and categories about automated planning. Next, we provide a detailed taxonomy and analysis of contemporary LLM-based planning methodologies, categorizing them into three principal approaches: 1) External Module Augmented Methods that combine LLMs with additional components for planning, 2) Finetuning-based Methods that involve using trajectory data and feedback signals to adjust LLMs in order to improve their planning abilities, and 3) Searching-based Methods that break down complex tasks into simpler components, navigate the planning space, or enhance decoding strategies to find the best solutions. Subsequently, we systematically summarize existing evaluation frameworks, including benchmark datasets, evaluation metrics and performance comparisons between representative planning methods. Finally, we discuss the underlying mechanisms enabling LLM-based planning and outline promising research directions for this rapidly evolving field. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this field.
DARTer: Dynamic Adaptive Representation Tracker for Nighttime UAV Tracking
May 01, 2025Nighttime UAV tracking presents significant challenges due to extreme illumination variations and viewpoint changes, which severely degrade tracking performance. Existing approaches either rely on light enhancers with high computational costs or introduce redundant domain adaptation mechanisms, failing to fully utilize the dynamic features in varying perspectives. To address these issues, we propose \textbf{DARTer} (\textbf{D}ynamic \textbf{A}daptive \textbf{R}epresentation \textbf{T}racker), an end-to-end tracking framework designed for nighttime UAV scenarios. DARTer leverages a Dynamic Feature Blender (DFB) to effectively fuse multi-perspective nighttime features from static and dynamic templates, enhancing representation robustness. Meanwhile, a Dynamic Feature Activator (DFA) adaptively activates Vision Transformer layers based on extracted features, significantly improving efficiency by reducing redundant computations. Our model eliminates the need for complex multi-task loss functions, enabling a streamlined training process. Extensive experiments on multiple nighttime UAV tracking benchmarks demonstrate the superiority of DARTer over state-of-the-art trackers. These results confirm that DARTer effectively balances tracking accuracy and efficiency, making it a promising solution for real-world nighttime UAV tracking applications.
Can LVLMs Describe Videos like Humans? A Five-in-One Video Annotations Benchmark for Better Human-Machine Comparison
Oct 20, 2024



Large vision-language models (LVLMs) have made significant strides in addressing complex video tasks, sparking researchers' interest in their human-like multimodal understanding capabilities. Video description serves as a fundamental task for evaluating video comprehension, necessitating a deep understanding of spatial and temporal dynamics, which presents challenges for both humans and machines. Thus, investigating whether LVLMs can describe videos as comprehensively as humans (through reasonable human-machine comparisons using video captioning as a proxy task) will enhance our understanding and application of these models. However, current benchmarks for video comprehension have notable limitations, including short video durations, brief annotations, and reliance on a single annotator's perspective. These factors hinder a comprehensive assessment of LVLMs' ability to understand complex, lengthy videos and prevent the establishment of a robust human baseline that accurately reflects human video comprehension capabilities. To address these issues, we propose a novel benchmark, FIOVA (Five In One Video Annotations), designed to evaluate the differences between LVLMs and human understanding more comprehensively. FIOVA includes 3,002 long video sequences (averaging 33.6 seconds) that cover diverse scenarios with complex spatiotemporal relationships. Each video is annotated by five distinct annotators, capturing a wide range of perspectives and resulting in captions that are 4-15 times longer than existing benchmarks, thereby establishing a robust baseline that represents human understanding comprehensively for the first time in video description tasks. Using the FIOVA benchmark, we conducted an in-depth evaluation of six state-of-the-art LVLMs, comparing their performance with humans. More detailed information can be found at https://huuuuusy.github.io/fiova/.