 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSID-Coord: Coordinating Semantic IDs for ID-based Ranking in Short-Video Search
Apr 12, 2026Large-scale short-video search ranking models are typically trained on sparse co-occurrence signals over hashed item identifiers (HIDs). While effective at memorizing frequent interactions, such ID-based models struggle to generalize to long-tailed items with limited exposure. This memorization-generalization trade-off remains a longstanding challenge in such industrial systems. We propose SID-Coord, a lightweight Semantic ID framework that incorporates discrete, trainable semantic IDs (SIDs) directly into ID-based ranking models. Instead of treating semantic signals as auxiliary dense features, SID-Coord represents semantics as structured identifiers and coordinates HID-based memorization with SID-based generalization within a unified modeling framework. To enable effective coordination, SID-Coord introduces three components: (1) an attention-based fusion module over hierarchical SIDs to capture multi-level semantics, (2) a target-aware HID-SID gating mechanism that adaptively balances memorization and generalization, and (3) a SID-driven interest alignment module that models the semantic similarity distribution between target items and user histories. SID-Coord can be integrated into existing production ranking systems without modifying the backbone model. Online A/B experiments in a real-world production environment show statistically significant improvements, with a +0.664% gain in long-play rate in search and a +0.369% increase in search playback duration.
Dual-Rerank: Fusing Causality and Utility for Industrial Generative Reranking
Apr 08, 2026Kuaishou serves over 400 million daily active users, processing hundreds of millions of search queries daily against a repository of tens of billions of short videos. As the final decision layer, the reranking stage determines user experience by optimizing whole-page utility. While traditional score-and-sort methods fail to capture combinatorial dependencies, Generative Reranking offers a superior paradigm by directly modeling the permutation probability. However, deploying Generative Reranking in such a high-stakes environment faces a fundamental dual dilemma: 1) the structural trade-off where Autoregressive (AR) models offer superior Sequential modeling but suffer from prohibitive latency, versus Non-Autoregressive (NAR) models that enable efficiency but lack dependency capturing; 2) the optimization gap where Supervised Learning faces challenges in directly optimizing whole-page utility, while Reinforcement Learning (RL) struggles with instability in high-throughput data streams. To resolve this, we propose Dual-Rerank, a unified framework designed for industrial reranking that bridges the structural gap via Sequential Knowledge Distillation and addresses the optimization gap using List-wise Decoupled Reranking Optimization (LDRO) for stable online RL. Extensive A/B testing on production traffic demonstrates that Dual-Rerank achieves State-of-the-Art performance, significantly improving User satisfaction and Watch Time while drastically reducing inference latency compared to AR baselines.
SaFRO: Satisfaction-Aware Fusion via Dual-Relative Policy Optimization for Short-Video Search
Mar 20, 2026Multi-Task Fusion plays a pivotal role in industrial short-video search systems by aggregating heterogeneous prediction signals into a unified ranking score. However, existing approaches predominantly optimize for immediate engagement metrics, which often fail to align with long-term user satisfaction. While Reinforcement Learning (RL) offers a promising avenue for user satisfaction optimization, its direct application to search scenarios is non-trivial due to the inherent data sparsity and intent constraints compared to recommendation feeds. To this end, we propose SaFRO, a novel framework designed to optimize user satisfaction in short-video search. We first construct a satisfaction-aware reward model that utilizes query-level behavioral proxies to capture holistic user satisfaction beyond item-level interactions. Then we introduce Dual-Relative Policy Optimization (DRPO), an efficient policy learning method that updates the fusion policy through relative preference comparisons within groups and across batches. Furthermore, we design a Task-Relation-Aware Fusion module to explicitly model the interdependencies among different objectives, enabling context-sensitive weight adaptation. Extensive offline evaluations and large-scale online A/B tests on Kuaishou short-video search platform demonstrate that SaFRO significantly outperforms state-of-the-art baselines, delivering substantial gains in both short-term ranking quality and long-term user retention.
Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval
Jul 31, 2024



Generative retrieval (GR) has emerged as a transformative paradigm in search and recommender systems, leveraging numeric-based identifier representations to enhance efficiency and generalization. Notably, methods like TIGER employing Residual Quantization-based Semantic Identifiers (RQ-SID), have shown significant promise in e-commerce scenarios by effectively managing item IDs. However, a critical issue termed the "\textbf{Hourglass}" phenomenon, occurs in RQ-SID, where intermediate codebook tokens become overly concentrated, hindering the full utilization of generative retrieval methods. This paper analyses and addresses this problem by identifying data sparsity and long-tailed distribution as the primary causes. Through comprehensive experiments and detailed ablation studies, we analyze the impact of these factors on codebook utilization and data distribution. Our findings reveal that the "Hourglass" phenomenon substantially impacts the performance of RQ-SID in generative retrieval. We propose effective solutions to mitigate this issue, thereby significantly enhancing the effectiveness of generative retrieval in real-world E-commerce applications.
Generative Retrieval with Preference Optimization for E-commerce Search
Jul 29, 2024Generative retrieval introduces a groundbreaking paradigm to document retrieval by directly generating the identifier of a pertinent document in response to a specific query. This paradigm has demonstrated considerable benefits and potential, particularly in representation and generalization capabilities, within the context of large language models. However, it faces significant challenges in E-commerce search scenarios, including the complexity of generating detailed item titles from brief queries, the presence of noise in item titles with weak language order, issues with long-tail queries, and the interpretability of results. To address these challenges, we have developed an innovative framework for E-commerce search, called generative retrieval with preference optimization. This framework is designed to effectively learn and align an autoregressive model with target data, subsequently generating the final item through constraint-based beam search. By employing multi-span identifiers to represent raw item titles and transforming the task of generating titles from queries into the task of generating multi-span identifiers from queries, we aim to simplify the generation process. The framework further aligns with human preferences using click data and employs a constrained search method to identify key spans for retrieving the final item, thereby enhancing result interpretability. Our extensive experiments show that this framework achieves competitive performance on a real-world dataset, and online A/B tests demonstrate the superiority and effectiveness in improving conversion gains.
Learning Multi-Stage Multi-Grained Semantic Embeddings for E-Commerce Search
Mar 20, 2023



Retrieving relevant items that match users' queries from billion-scale corpus forms the core of industrial e-commerce search systems, in which embedding-based retrieval (EBR) methods are prevailing. These methods adopt a two-tower framework to learn embedding vectors for query and item separately and thus leverage efficient approximate nearest neighbor (ANN) search to retrieve relevant items. However, existing EBR methods usually ignore inconsistent user behaviors in industrial multi-stage search systems, resulting in insufficient retrieval efficiency with a low commercial return. To tackle this challenge, we propose to improve EBR methods by learning Multi-level Multi-Grained Semantic Embeddings(MMSE). We propose the multi-stage information mining to exploit the ordered, clicked, unclicked and random sampled items in practical user behavior data, and then capture query-item similarity via a post-fusion strategy. We then propose multi-grained learning objectives that integrate the retrieval loss with global comparison ability and the ranking loss with local comparison ability to generate semantic embeddings. Both experiments on a real-world billion-scale dataset and online A/B tests verify the effectiveness of MMSE in achieving significant performance improvements on metrics such as offline recall and online conversion rate (CVR).
Pre-training Tasks for User Intent Detection and Embedding Retrieval in E-commerce Search
Aug 22, 2022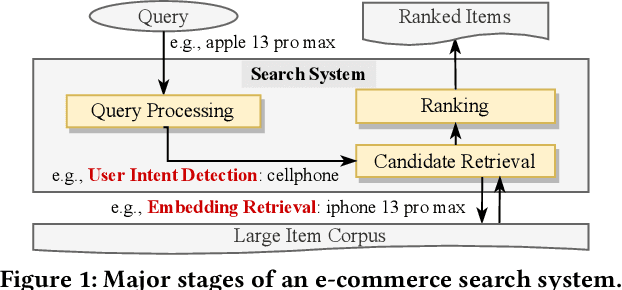

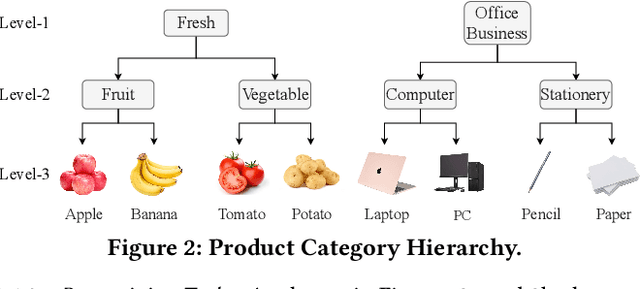
BERT-style models pre-trained on the general corpus (e.g., Wikipedia) and fine-tuned on specific task corpus, have recently emerged as breakthrough techniques in many NLP tasks: question answering, text classification, sequence labeling and so on. However, this technique may not always work, especially for two scenarios: a corpus that contains very different text from the general corpus Wikipedia, or a task that learns embedding spacial distribution for a specific purpose (e.g., approximate nearest neighbor search). In this paper, to tackle the above two scenarios that we have encountered in an industrial e-commerce search system, we propose customized and novel pre-training tasks for two critical modules: user intent detection and semantic embedding retrieval. The customized pre-trained models after fine-tuning, being less than 10% of BERT-base's size in order to be feasible for cost-efficient CPU serving, significantly improve the other baseline models: 1) no pre-training model and 2) fine-tuned model from the official pre-trained BERT using general corpus, on both offline datasets and online system. We have open sourced our datasets for the sake of reproducibility and future works.
WSLRec: Weakly Supervised Learning for Neural Sequential Recommendation Models
Feb 28, 2022
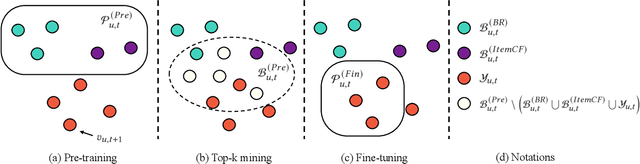
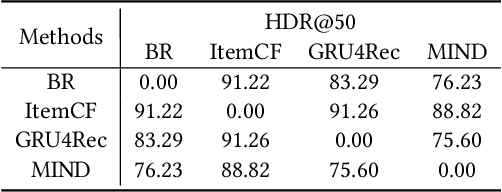
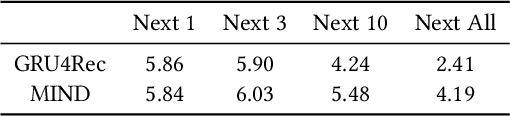
Learning the user-item relevance hidden in implicit feedback data plays an important role in modern recommender systems. Neural sequential recommendation models, which formulates learning the user-item relevance as a sequential classification problem to distinguish items in future behaviors from others based on the user's historical behaviors, have attracted a lot of interest in both industry and academic due to their substantial practical value. Though achieving many practical successes, we argue that the intrinsic {\bf incompleteness} and {\bf inaccuracy} of user behaviors in implicit feedback data is ignored and conduct preliminary experiments for supporting our claims. Motivated by the observation that model-free methods like behavioral retargeting (BR) and item-based collaborative filtering (ItemCF) hit different parts of the user-item relevance compared to neural sequential recommendation models, we propose a novel model-agnostic training approach called WSLRec, which adopts a three-stage framework: pre-training, top-$k$ mining, and fine-tuning. WSLRec resolves the incompleteness problem by pre-training models on extra weak supervisions from model-free methods like BR and ItemCF, while resolves the inaccuracy problem by leveraging the top-$k$ mining to screen out reliable user-item relevance from weak supervisions for fine-tuning. Experiments on two benchmark datasets and online A/B tests verify the rationality of our claims and demonstrate the effectiveness of WSLRec.
Learning Optimal Tree Models Under Beam Search
Jun 27, 2020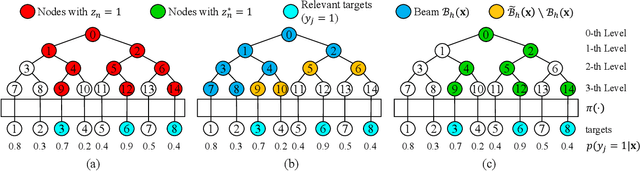
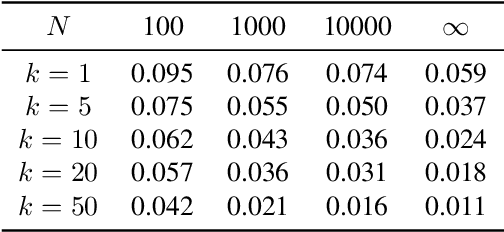
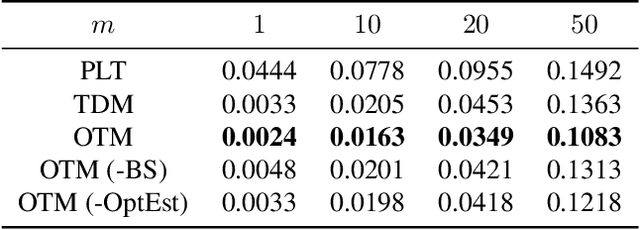
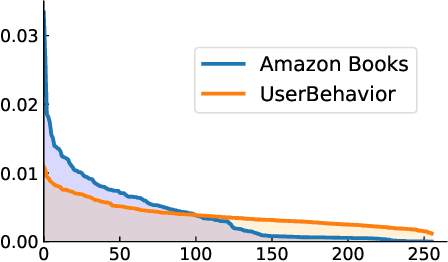
Retrieving relevant targets from an extremely large target set under computational limits is a common challenge for information retrieval and recommendation systems. Tree models, which formulate targets as leaves of a tree with trainable node-wise scorers, have attracted a lot of interests in tackling this challenge due to their logarithmic computational complexity in both training and testing. Tree-based deep models (TDMs) and probabilistic label trees (PLTs) are two representative kinds of them. Though achieving many practical successes, existing tree models suffer from the training-testing discrepancy, where the retrieval performance deterioration caused by beam search in testing is not considered in training. This leads to an intrinsic gap between the most relevant targets and those retrieved by beam search with even the optimally trained node-wise scorers. We take a first step towards understanding and analyzing this problem theoretically, and develop the concept of Bayes optimality under beam search and calibration under beam search as general analyzing tools for this purpose. Moreover, to eliminate the discrepancy, we propose a novel algorithm for learning optimal tree models under beam search. Experiments on both synthetic and real data verify the rationality of our theoretical analysis and demonstrate the superiority of our algorithm compared to state-of-the-art methods.
Understanding MCMC Dynamics as Flows on the Wasserstein Space
Feb 01, 2019
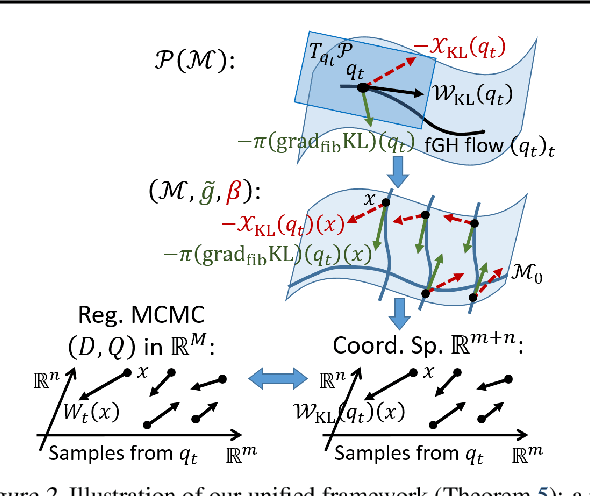

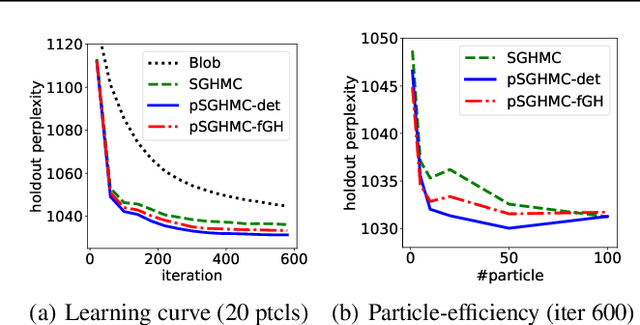
It is known that the Langevin dynamics used in MCMC is the gradient flow of the KL divergence on the Wasserstein space, which helps convergence analysis and inspires recent particle-based variational inference methods (ParVIs). But no more MCMC dynamics is understood in this way. In this work, by developing novel concepts, we propose a theoretical framework that recognizes a general MCMC dynamics as the fiber-gradient Hamiltonian flow on the Wasserstein space of a fiber-Riemannian Poisson manifold. The "conservation + convergence" structure of the flow gives a clear picture on the behavior of general MCMC dynamics. We analyse existing MCMC instances under the framework. The framework also enables ParVI simulation of MCMC dynamics, which enriches the ParVI family with more efficient dynamics, and also adapts ParVI advantages to MCMCs. We develop two ParVI methods for a particular MCMC dynamics and demonstrate the benefits in experiments.