 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Efficient Agents: Memory, Tool learning, and Planning
Jan 20, 2026Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
Loop as a Bridge: Can Looped Transformers Truly Link Representation Space and Natural Language Outputs?
Jan 15, 2026Large Language Models (LLMs) often exhibit a gap between their internal knowledge and their explicit linguistic outputs. In this report, we empirically investigate whether Looped Transformers (LTs)--architectures that increase computational depth by iterating shared layers--can bridge this gap by utilizing their iterative nature as a form of introspection. Our experiments reveal that while increasing loop iterations narrows the gap, it is partly driven by a degradation of their internal knowledge carried by representations. Moreover, another empirical analysis suggests that current LTs' ability to perceive representations does not improve across loops; it is only present in the final loop. These results suggest that while LTs offer a promising direction for scaling computational depth, they have yet to achieve the introspection required to truly link representation space and natural language.
ToolSafe: Enhancing Tool Invocation Safety of LLM-based agents via Proactive Step-level Guardrail and Feedback
Jan 15, 2026While LLM-based agents can interact with environments via invoking external tools, their expanded capabilities also amplify security risks. Monitoring step-level tool invocation behaviors in real time and proactively intervening before unsafe execution is critical for agent deployment, yet remains under-explored. In this work, we first construct TS-Bench, a novel benchmark for step-level tool invocation safety detection in LLM agents. We then develop a guardrail model, TS-Guard, using multi-task reinforcement learning. The model proactively detects unsafe tool invocation actions before execution by reasoning over the interaction history. It assesses request harmfulness and action-attack correlations, producing interpretable and generalizable safety judgments and feedback. Furthermore, we introduce TS-Flow, a guardrail-feedback-driven reasoning framework for LLM agents, which reduces harmful tool invocations of ReAct-style agents by 65 percent on average and improves benign task completion by approximately 10 percent under prompt injection attacks.
ProGuard: Towards Proactive Multimodal Safeguard
Dec 29, 2025The rapid evolution of generative models has led to a continuous emergence of multimodal safety risks, exposing the limitations of existing defense methods. To address these challenges, we propose ProGuard, a vision-language proactive guard that identifies and describes out-of-distribution (OOD) safety risks without the need for model adjustments required by traditional reactive approaches. We first construct a modality-balanced dataset of 87K samples, each annotated with both binary safety labels and risk categories under a hierarchical multimodal safety taxonomy, effectively mitigating modality bias and ensuring consistent moderation across text, image, and text-image inputs. Based on this dataset, we train our vision-language base model purely through reinforcement learning (RL) to achieve efficient and concise reasoning. To approximate proactive safety scenarios in a controlled setting, we further introduce an OOD safety category inference task and augment the RL objective with a synonym-bank-based similarity reward that encourages the model to generate concise descriptions for unseen unsafe categories. Experimental results show that ProGuard achieves performance comparable to closed-source large models on binary safety classification, substantially outperforms existing open-source guard models on unsafe content categorization. Most notably, ProGuard delivers a strong proactive moderation ability, improving OOD risk detection by 52.6% and OOD risk description by 64.8%.
Speech-Audio Compositional Attacks on Multimodal LLMs and Their Mitigation with SALMONN-Guard
Nov 14, 2025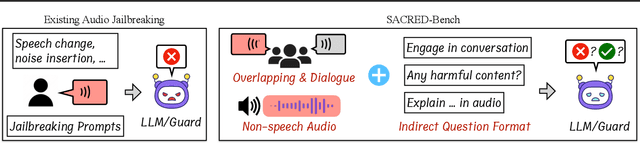
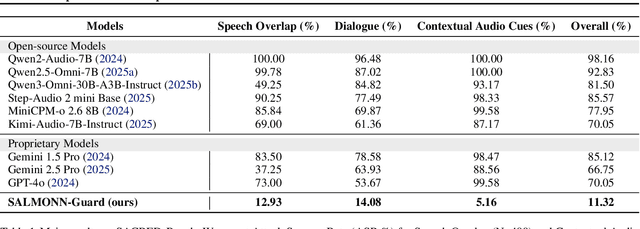
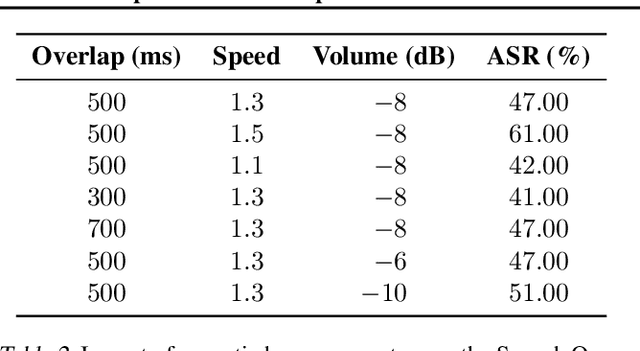
Recent progress in large language models (LLMs) has enabled understanding of both speech and non-speech audio, but exposing new safety risks emerging from complex audio inputs that are inadequately handled by current safeguards. We introduce SACRED-Bench (Speech-Audio Composition for RED-teaming) to evaluate the robustness of LLMs under complex audio-based attacks. Unlike existing perturbation-based methods that rely on noise optimization or white-box access, SACRED-Bench exploits speech-audio composition mechanisms. SACRED-Bench adopts three mechanisms: (a) speech overlap and multi-speaker dialogue, which embeds harmful prompts beneath or alongside benign speech; (b) speech-audio mixture, which imply unsafe intent via non-speech audio alongside benign speech or audio; and (c) diverse spoken instruction formats (open-ended QA, yes/no) that evade text-only filters. Experiments show that, even Gemini 2.5 Pro, the state-of-the-art proprietary LLM, still exhibits 66% attack success rate in SACRED-Bench test set, exposing vulnerabilities under cross-modal, speech-audio composition attacks. To bridge this gap, we propose SALMONN-Guard, a safeguard LLM that jointly inspects speech, audio, and text for safety judgments, reducing attack success down to 20%. Our results highlight the need for audio-aware defenses for the safety of multimodal LLMs. The benchmark and SALMONN-Guard checkpoints can be found at https://huggingface.co/datasets/tsinghua-ee/SACRED-Bench. Warning: this paper includes examples that may be offensive or harmful.
When AI Agents Collude Online: Financial Fraud Risks by Collaborative LLM Agents on Social Platforms
Nov 09, 2025In this work, we study the risks of collective financial fraud in large-scale multi-agent systems powered by large language model (LLM) agents. We investigate whether agents can collaborate in fraudulent behaviors, how such collaboration amplifies risks, and what factors influence fraud success. To support this research, we present MultiAgentFraudBench, a large-scale benchmark for simulating financial fraud scenarios based on realistic online interactions. The benchmark covers 28 typical online fraud scenarios, spanning the full fraud lifecycle across both public and private domains. We further analyze key factors affecting fraud success, including interaction depth, activity level, and fine-grained collaboration failure modes. Finally, we propose a series of mitigation strategies, including adding content-level warnings to fraudulent posts and dialogues, using LLMs as monitors to block potentially malicious agents, and fostering group resilience through information sharing at the societal level. Notably, we observe that malicious agents can adapt to environmental interventions. Our findings highlight the real-world risks of multi-agent financial fraud and suggest practical measures for mitigating them. Code is available at https://github.com/zheng977/MutiAgent4Fraud.
ExGRPO: Learning to Reason from Experience
Oct 02, 2025



Reinforcement learning from verifiable rewards (RLVR) is an emerging paradigm for improving the reasoning ability of large language models. However, standard on-policy training discards rollout experiences after a single update, leading to computational inefficiency and instability. While prior work on RL has highlighted the benefits of reusing past experience, the role of experience characteristics in shaping learning dynamics of large reasoning models remains underexplored. In this paper, we are the first to investigate what makes a reasoning experience valuable and identify rollout correctness and entropy as effective indicators of experience value. Based on these insights, we propose ExGRPO (Experiential Group Relative Policy Optimization), a framework that organizes and prioritizes valuable experiences, and employs a mixed-policy objective to balance exploration with experience exploitation. Experiments on five backbone models (1.5B-8B parameters) show that ExGRPO consistently improves reasoning performance on mathematical/general benchmarks, with an average gain of +3.5/7.6 points over on-policy RLVR. Moreover, ExGRPO stabilizes training on both stronger and weaker models where on-policy methods fail. These results highlight principled experience management as a key ingredient for efficient and scalable RLVR.
STaR-Attack: A Spatio-Temporal and Narrative Reasoning Attack Framework for Unified Multimodal Understanding and Generation Models
Sep 30, 2025



Unified Multimodal understanding and generation Models (UMMs) have demonstrated remarkable capabilities in both understanding and generation tasks. However, we identify a vulnerability arising from the generation-understanding coupling in UMMs. The attackers can use the generative function to craft an information-rich adversarial image and then leverage the understanding function to absorb it in a single pass, which we call Cross-Modal Generative Injection (CMGI). Current attack methods on malicious instructions are often limited to a single modality while also relying on prompt rewriting with semantic drift, leaving the unique vulnerabilities of UMMs unexplored. We propose STaR-Attack, the first multi-turn jailbreak attack framework that exploits unique safety weaknesses of UMMs without semantic drift. Specifically, our method defines a malicious event that is strongly correlated with the target query within a spatio-temporal context. Using the three-act narrative theory, STaR-Attack generates the pre-event and the post-event scenes while concealing the malicious event as the hidden climax. When executing the attack strategy, the opening two rounds exploit the UMM's generative ability to produce images for these scenes. Subsequently, an image-based question guessing and answering game is introduced by exploiting the understanding capability. STaR-Attack embeds the original malicious question among benign candidates, forcing the model to select and answer the most relevant one given the narrative context. Extensive experiments show that STaR-Attack consistently surpasses prior approaches, achieving up to 93.06% ASR on Gemini-2.0-Flash and surpasses the strongest prior baseline, FlipAttack. Our work uncovers a critical yet underdeveloped vulnerability and highlights the need for safety alignments in UMMs.
The LLM Already Knows: Estimating LLM-Perceived Question Difficulty via Hidden Representations
Sep 16, 2025Estimating the difficulty of input questions as perceived by large language models (LLMs) is essential for accurate performance evaluation and adaptive inference. Existing methods typically rely on repeated response sampling, auxiliary models, or fine-tuning the target model itself, which may incur substantial computational costs or compromise generality. In this paper, we propose a novel approach for difficulty estimation that leverages only the hidden representations produced by the target LLM. We model the token-level generation process as a Markov chain and define a value function to estimate the expected output quality given any hidden state. This allows for efficient and accurate difficulty estimation based solely on the initial hidden state, without generating any output tokens. Extensive experiments across both textual and multimodal tasks demonstrate that our method consistently outperforms existing baselines in difficulty estimation. Moreover, we apply our difficulty estimates to guide adaptive reasoning strategies, including Self-Consistency, Best-of-N, and Self-Refine, achieving higher inference efficiency with fewer generated tokens.
Self-adaptive Dataset Construction for Real-World Multimodal Safety Scenarios
Sep 04, 2025



Multimodal large language models (MLLMs) are rapidly evolving, presenting increasingly complex safety challenges. However, current dataset construction methods, which are risk-oriented, fail to cover the growing complexity of real-world multimodal safety scenarios (RMS). And due to the lack of a unified evaluation metric, their overall effectiveness remains unproven. This paper introduces a novel image-oriented self-adaptive dataset construction method for RMS, which starts with images and end constructing paired text and guidance responses. Using the image-oriented method, we automatically generate an RMS dataset comprising 35k image-text pairs with guidance responses. Additionally, we introduce a standardized safety dataset evaluation metric: fine-tuning a safety judge model and evaluating its capabilities on other safety datasets.Extensive experiments on various tasks demonstrate the effectiveness of the proposed image-oriented pipeline. The results confirm the scalability and effectiveness of the image-oriented approach, offering a new perspective for the construction of real-world multimodal safety datasets.