 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
May 28, 2026Modern open-world agents such as OpenClaw exhibit powerful cross-environment execution capabilities yet introduce broad new safety risk sources. Meanwhile, advanced frontier AI models drastically lower attack barriers, rendering current agent alignment frameworks inadequate for real-world deployment. To tackle these emerging threats, we propose a lightweight and scalable agent safety alignment framework. Specifically, we update the agent safety taxonomy to accommodate emergent risks from Codex and OpenClaw execution scenarios. We further build a taxonomy-guided data engine with influence-function purification to train lightweight AgentDoG 1.5 variants (0.8B, 2B, 4B, and 8B parameters) using only around 1k samples, achieving comparable performance with leading closed-source models (e.g., GPT-5.4). Based on AgentDoG 1.5, we construct a highly efficient agentic safety SFT and RL training environment, which reduces deployment overhead in Docker-level environments by two orders of magnitude. Finally, we deploy AgentDoG 1.5 as a training-free online guardrail for real-time safety moderation. Extensive experimental results indicate that AgentDoG 1.5 achieves state-of-the-art performance in diverse and complex interactive agentic scenarios. All models and datasets are openly released.
DeepSight: An All-in-One LM Safety Toolkit
Feb 12, 2026As the development of Large Models (LMs) progresses rapidly, their safety is also a priority. In current Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) safety workflow, evaluation, diagnosis, and alignment are often handled by separate tools. Specifically, safety evaluation can only locate external behavioral risks but cannot figure out internal root causes. Meanwhile, safety diagnosis often drifts from concrete risk scenarios and remains at the explainable level. In this way, safety alignment lack dedicated explanations of changes in internal mechanisms, potentially degrading general capabilities. To systematically address these issues, we propose an open-source project, namely DeepSight, to practice a new safety evaluation-diagnosis integrated paradigm. DeepSight is low-cost, reproducible, efficient, and highly scalable large-scale model safety evaluation project consisting of a evaluation toolkit DeepSafe and a diagnosis toolkit DeepScan. By unifying task and data protocols, we build a connection between the two stages and transform safety evaluation from black-box to white-box insight. Besides, DeepSight is the first open source toolkit that support the frontier AI risk evaluation and joint safety evaluation and diagnosis.
TTSA3R: Training-Free Temporal-Spatial Adaptive Persistent State for Streaming 3D Reconstruction
Jan 30, 2026Streaming recurrent models enable efficient 3D reconstruction by maintaining persistent state representations. However, they suffer from catastrophic memory forgetting over long sequences due to balancing historical information with new observations. Recent methods alleviate this by deriving adaptive signals from attention perspective, but they operate on single dimensions without considering temporal and spatial consistency. To this end, we propose a training-free framework termed TTSA3R that leverages both temporal state evolution and spatial observation quality for adaptive state updates in 3D reconstruction. In particular, we devise a Temporal Adaptive Update Module that regulates update magnitude by analyzing temporal state evolution patterns. Then, a Spatial Contextual Update Module is introduced to localize spatial regions that require updates through observation-state alignment and scene dynamics. These complementary signals are finally fused to determine the state updating strategies. Extensive experiments demonstrate the effectiveness of TTSA3R in diverse 3D tasks. Moreover, our method exhibits only 15% error increase compared to over 200% degradation in baseline models on extended sequences, significantly improving long-term reconstruction stability. Our codes will be available soon.
Revisiting the Data Sampling in Multimodal Post-training from a Difficulty-Distinguish View
Nov 10, 2025Recent advances in Multimodal Large Language Models (MLLMs) have spurred significant progress in Chain-of-Thought (CoT) reasoning. Building on the success of Deepseek-R1, researchers extended multimodal reasoning to post-training paradigms based on reinforcement learning (RL), focusing predominantly on mathematical datasets. However, existing post-training paradigms tend to neglect two critical aspects: (1) The lack of quantifiable difficulty metrics capable of strategically screening samples for post-training optimization. (2) Suboptimal post-training paradigms that fail to jointly optimize perception and reasoning capabilities. To address this gap, we propose two novel difficulty-aware sampling strategies: Progressive Image Semantic Masking (PISM) quantifies sample hardness through systematic image degradation, while Cross-Modality Attention Balance (CMAB) assesses cross-modal interaction complexity via attention distribution analysis. Leveraging these metrics, we design a hierarchical training framework that incorporates both GRPO-only and SFT+GRPO hybrid training paradigms, and evaluate them across six benchmark datasets. Experiments demonstrate consistent superiority of GRPO applied to difficulty-stratified samples compared to conventional SFT+GRPO pipelines, indicating that strategic data sampling can obviate the need for supervised fine-tuning while improving model accuracy. Our code will be released at https://github.com/qijianyu277/DifficultySampling.
When AI Agents Collude Online: Financial Fraud Risks by Collaborative LLM Agents on Social Platforms
Nov 09, 2025In this work, we study the risks of collective financial fraud in large-scale multi-agent systems powered by large language model (LLM) agents. We investigate whether agents can collaborate in fraudulent behaviors, how such collaboration amplifies risks, and what factors influence fraud success. To support this research, we present MultiAgentFraudBench, a large-scale benchmark for simulating financial fraud scenarios based on realistic online interactions. The benchmark covers 28 typical online fraud scenarios, spanning the full fraud lifecycle across both public and private domains. We further analyze key factors affecting fraud success, including interaction depth, activity level, and fine-grained collaboration failure modes. Finally, we propose a series of mitigation strategies, including adding content-level warnings to fraudulent posts and dialogues, using LLMs as monitors to block potentially malicious agents, and fostering group resilience through information sharing at the societal level. Notably, we observe that malicious agents can adapt to environmental interventions. Our findings highlight the real-world risks of multi-agent financial fraud and suggest practical measures for mitigating them. Code is available at https://github.com/zheng977/MutiAgent4Fraud.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025



To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
Structure Information is the Key: Self-Attention RoI Feature Extractor in 3D Object Detection
Nov 15, 2021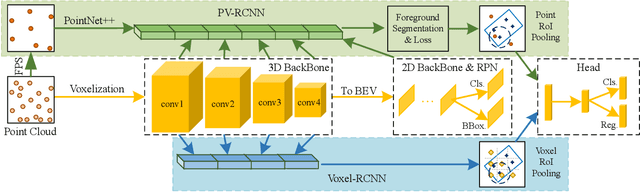
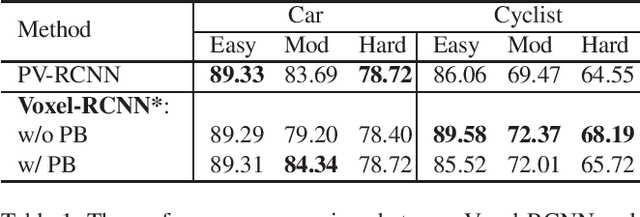

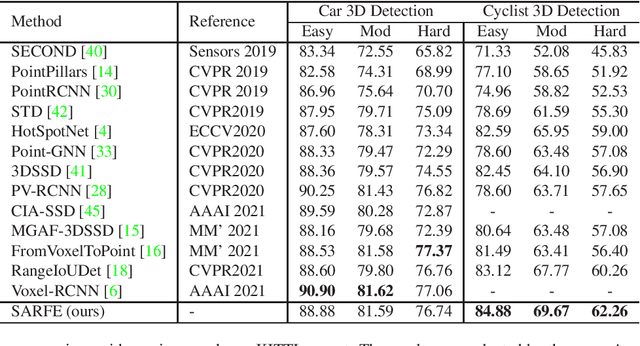
Unlike 2D object detection where all RoI features come from grid pixels, the RoI feature extraction of 3D point cloud object detection is more diverse. In this paper, we first compare and analyze the differences in structure and performance between the two state-of-the-art models PV-RCNN and Voxel-RCNN. Then, we find that the performance gap between the two models does not come from point information, but structural information. The voxel features contain more structural information because they do quantization instead of downsampling to point cloud so that they can contain basically the complete information of the whole point cloud. The stronger structural information in voxel features makes the detector have higher performance in our experiments even if the voxel features don't have accurate location information. Then, we propose that structural information is the key to 3D object detection. Based on the above conclusion, we propose a Self-Attention RoI Feature Extractor (SARFE) to enhance structural information of the feature extracted from 3D proposals. SARFE is a plug-and-play module that can be easily used on existing 3D detectors. Our SARFE is evaluated on both KITTI dataset and Waymo Open dataset. With the newly introduced SARFE, we improve the performance of the state-of-the-art 3D detectors by a large margin in cyclist on KITTI dataset while keeping real-time capability.