 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models
Apr 02, 2026We present OmniVoice, a massive multilingual zero-shot text-to-speech (TTS) model that scales to over 600 languages. At its core is a novel diffusion language model-style discrete non-autoregressive (NAR) architecture. Unlike conventional discrete NAR models that suffer from performance bottlenecks in complex two-stage (text-to-semantic-to-acoustic) pipelines, OmniVoice directly maps text to multi-codebook acoustic tokens. This simplified approach is facilitated by two key technical innovations: (1) a full-codebook random masking strategy for efficient training, and (2) initialization from a pre-trained LLM to ensure superior intelligibility. By leveraging a 581k-hour multilingual dataset curated entirely from open-source data, OmniVoice achieves the broadest language coverage to date and delivers state-of-the-art performance across Chinese, English, and diverse multilingual benchmarks. Our code and pre-trained models are publicly available at https://github.com/k2-fsa/OmniVoice.
Flow2GAN: Hybrid Flow Matching and GAN with Multi-Resolution Network for Few-step High-Fidelity Audio Generation
Dec 29, 2025Existing dominant methods for audio generation include Generative Adversarial Networks (GANs) and diffusion-based methods like Flow Matching. GANs suffer from slow convergence and potential mode collapse during training, while diffusion methods require multi-step inference that introduces considerable computational overhead. In this work, we introduce Flow2GAN, a two-stage framework that combines Flow Matching training for learning generative capabilities with GAN fine-tuning for efficient few-step inference. Specifically, given audio's unique properties, we first improve Flow Matching for audio modeling through: 1) reformulating the objective as endpoint estimation, avoiding velocity estimation difficulties when involving empty regions; 2) applying spectral energy-based loss scaling to emphasize perceptually salient quieter regions. Building on these Flow Matching adaptations, we demonstrate that a further stage of lightweight GAN fine-tuning enables us to obtain one-step generator that produces high-quality audio. In addition, we develop a multi-branch network architecture that processes Fourier coefficients at different time-frequency resolutions, which improves the modeling capabilities compared to prior single-resolution designs. Experimental results indicate that our Flow2GAN delivers high-fidelity audio generation from Mel-spectrograms or discrete audio tokens, achieving better quality-efficiency trade-offs than existing state-of-the-art GAN-based and Flow Matching-based methods. Online demo samples are available at https://flow2gan.github.io, and the source code is released at https://github.com/k2-fsa/Flow2GAN.
Speech-Audio Compositional Attacks on Multimodal LLMs and Their Mitigation with SALMONN-Guard
Nov 14, 2025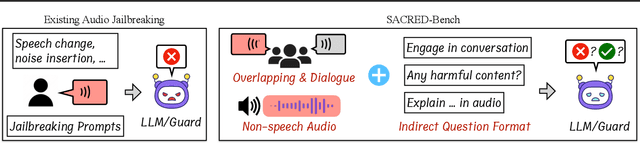
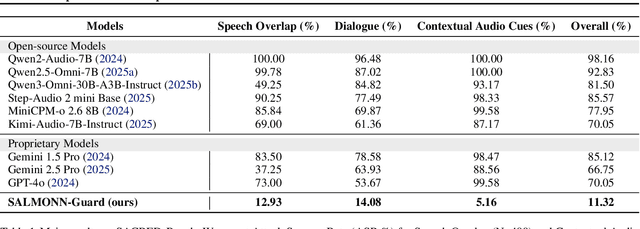
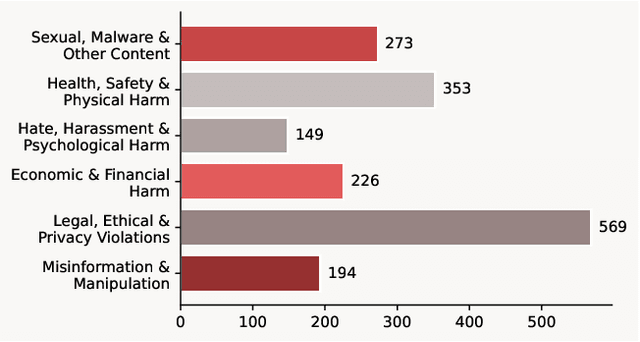
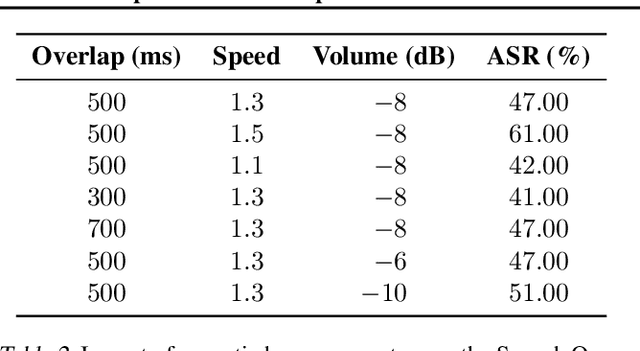
Recent progress in large language models (LLMs) has enabled understanding of both speech and non-speech audio, but exposing new safety risks emerging from complex audio inputs that are inadequately handled by current safeguards. We introduce SACRED-Bench (Speech-Audio Composition for RED-teaming) to evaluate the robustness of LLMs under complex audio-based attacks. Unlike existing perturbation-based methods that rely on noise optimization or white-box access, SACRED-Bench exploits speech-audio composition mechanisms. SACRED-Bench adopts three mechanisms: (a) speech overlap and multi-speaker dialogue, which embeds harmful prompts beneath or alongside benign speech; (b) speech-audio mixture, which imply unsafe intent via non-speech audio alongside benign speech or audio; and (c) diverse spoken instruction formats (open-ended QA, yes/no) that evade text-only filters. Experiments show that, even Gemini 2.5 Pro, the state-of-the-art proprietary LLM, still exhibits 66% attack success rate in SACRED-Bench test set, exposing vulnerabilities under cross-modal, speech-audio composition attacks. To bridge this gap, we propose SALMONN-Guard, a safeguard LLM that jointly inspects speech, audio, and text for safety judgments, reducing attack success down to 20%. Our results highlight the need for audio-aware defenses for the safety of multimodal LLMs. The benchmark and SALMONN-Guard checkpoints can be found at https://huggingface.co/datasets/tsinghua-ee/SACRED-Bench. Warning: this paper includes examples that may be offensive or harmful.
Silent Speech Sentence Recognition with Six-Axis Accelerometers using Conformer and CTC Algorithm
Feb 25, 2025



Silent speech interfaces (SSI) are being actively developed to assist individuals with communication impairments who have long suffered from daily hardships and a reduced quality of life. However, silent sentences are difficult to segment and recognize due to elision and linking. A novel silent speech sentence recognition method is proposed to convert the facial motion signals collected by six-axis accelerometers into transcribed words and sentences. A Conformer-based neural network with the Connectionist-Temporal-Classification algorithm is used to gain contextual understanding and translate the non-acoustic signals into words sequences, solely requesting the constituent words in the database. Test results show that the proposed method achieves a 97.17% accuracy in sentence recognition, surpassing the existing silent speech recognition methods with a typical accuracy of 85%-95%, and demonstrating the potential of accelerometers as an available SSI modality for high-accuracy silent speech sentence recognition.