 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRay-Based Characterization of the AMPLE Model from 0.85 to 5 GHz
Apr 12, 2025



In this paper, we characterize the adaptive multiple path loss exponent (AMPLE) radio propagation model under urban macrocell (UMa) and urban microcell (UMi) scenarios from 0.85-5 GHz using Ranplan Professional. We first enhance the original AMPLE model by introducing an additional frequency coefficient to support path loss prediction across multiple carrier frequencies. By using measurement-validated Ranplan Professional simulator, we simulate four cities and validate the simulations for further path loss model characterization. Specifically, we extract the close-in (CI) model parameters from the simulations and compare them with parameters extracted from measurements in other works. Under the ray-based model characterization, we compare the AMPLE model with the 3rd Generation Partnership Project (3GPP) path loss model, the CI model, the alpha-beta-gamma (ABG) model, and those with simulation calibrations. In addition to standard performance metrics, we introduce the prediction-measurement difference error (PMDE) to assess overall prediction alignment with measurement, and mean simulation time per data point to evaluate model complexity. The results show that the AMPLE model outperforms existing models while maintaining similar model complexity.
Distilling Textual Priors from LLM to Efficient Image Fusion
Apr 09, 2025



Multi-modality image fusion aims to synthesize a single, comprehensive image from multiple source inputs. Traditional approaches, such as CNNs and GANs, offer efficiency but struggle to handle low-quality or complex inputs. Recent advances in text-guided methods leverage large model priors to overcome these limitations, but at the cost of significant computational overhead, both in memory and inference time. To address this challenge, we propose a novel framework for distilling large model priors, eliminating the need for text guidance during inference while dramatically reducing model size. Our framework utilizes a teacher-student architecture, where the teacher network incorporates large model priors and transfers this knowledge to a smaller student network via a tailored distillation process. Additionally, we introduce spatial-channel cross-fusion module to enhance the model's ability to leverage textual priors across both spatial and channel dimensions. Our method achieves a favorable trade-off between computational efficiency and fusion quality. The distilled network, requiring only 10\% of the parameters and inference time of the teacher network, retains 90\% of its performance and outperforms existing SOTA methods. Extensive experiments demonstrate the effectiveness of our approach. The implementation will be made publicly available as an open-source resource.
Video-Bench: Human-Aligned Video Generation Benchmark
Apr 07, 2025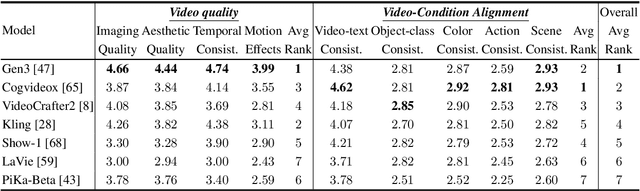
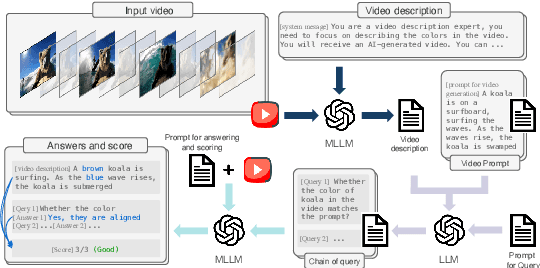
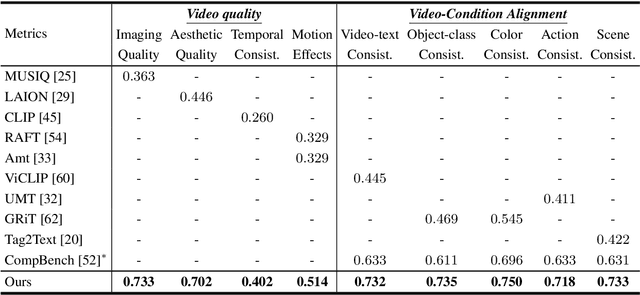
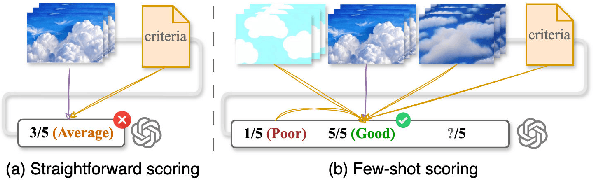
Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework's assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.
BoxSeg: Quality-Aware and Peer-Assisted Learning for Box-supervised Instance Segmentation
Apr 07, 2025Box-supervised instance segmentation methods aim to achieve instance segmentation with only box annotations. Recent methods have demonstrated the effectiveness of acquiring high-quality pseudo masks under the teacher-student framework. Building upon this foundation, we propose a BoxSeg framework involving two novel and general modules named the Quality-Aware Module (QAM) and the Peer-assisted Copy-paste (PC). The QAM obtains high-quality pseudo masks and better measures the mask quality to help reduce the effect of noisy masks, by leveraging the quality-aware multi-mask complementation mechanism. The PC imitates Peer-Assisted Learning to further improve the quality of the low-quality masks with the guidance of the obtained high-quality pseudo masks. Theoretical and experimental analyses demonstrate the proposed QAM and PC are effective. Extensive experimental results show the superiority of our BoxSeg over the state-of-the-art methods, and illustrate the QAM and PC can be applied to improve other models.
Clean Image May be Dangerous: Data Poisoning Attacks Against Deep Hashing
Mar 27, 2025Large-scale image retrieval using deep hashing has become increasingly popular due to the exponential growth of image data and the remarkable feature extraction capabilities of deep neural networks (DNNs). However, deep hashing methods are vulnerable to malicious attacks, including adversarial and backdoor attacks. It is worth noting that these attacks typically involve altering the query images, which is not a practical concern in real-world scenarios. In this paper, we point out that even clean query images can be dangerous, inducing malicious target retrieval results, like undesired or illegal images. To the best of our knowledge, we are the first to study data \textbf{p}oisoning \textbf{a}ttacks against \textbf{d}eep \textbf{hash}ing \textbf{(\textit{PADHASH})}. Specifically, we first train a surrogate model to simulate the behavior of the target deep hashing model. Then, a strict gradient matching strategy is proposed to generate the poisoned images. Extensive experiments on different models, datasets, hash methods, and hash code lengths demonstrate the effectiveness and generality of our attack method.
REVAL: A Comprehension Evaluation on Reliability and Values of Large Vision-Language Models
Mar 20, 2025



The rapid evolution of Large Vision-Language Models (LVLMs) has highlighted the necessity for comprehensive evaluation frameworks that assess these models across diverse dimensions. While existing benchmarks focus on specific aspects such as perceptual abilities, cognitive capabilities, and safety against adversarial attacks, they often lack the breadth and depth required to provide a holistic understanding of LVLMs' strengths and limitations. To address this gap, we introduce REVAL, a comprehensive benchmark designed to evaluate the \textbf{RE}liability and \textbf{VAL}ue of LVLMs. REVAL encompasses over 144K image-text Visual Question Answering (VQA) samples, structured into two primary sections: Reliability, which assesses truthfulness (\eg, perceptual accuracy and hallucination tendencies) and robustness (\eg, resilience to adversarial attacks, typographic attacks, and image corruption), and Values, which evaluates ethical concerns (\eg, bias and moral understanding), safety issues (\eg, toxicity and jailbreak vulnerabilities), and privacy problems (\eg, privacy awareness and privacy leakage). We evaluate 26 models, including mainstream open-source LVLMs and prominent closed-source models like GPT-4o and Gemini-1.5-Pro. Our findings reveal that while current LVLMs excel in perceptual tasks and toxicity avoidance, they exhibit significant vulnerabilities in adversarial scenarios, privacy preservation, and ethical reasoning. These insights underscore critical areas for future improvements, guiding the development of more secure, reliable, and ethically aligned LVLMs. REVAL provides a robust framework for researchers to systematically assess and compare LVLMs, fostering advancements in the field.
WarmFed: Federated Learning with Warm-Start for Globalization and Personalization Via Personalized Diffusion Models
Mar 05, 2025Federated Learning (FL) stands as a prominent distributed learning paradigm among multiple clients to achieve a unified global model without privacy leakage. In contrast to FL, Personalized federated learning aims at serving for each client in achieving persoanlized model. However, previous FL frameworks have grappled with a dilemma: the choice between developing a singular global model at the server to bolster globalization or nurturing personalized model at the client to accommodate personalization. Instead of making trade-offs, this paper commences its discourse from the pre-trained initialization, obtaining resilient global information and facilitating the development of both global and personalized models. Specifically, we propose a novel method called WarmFed to achieve this. WarmFed customizes Warm-start through personalized diffusion models, which are generated by local efficient fine-tunining (LoRA). Building upon the Warm-Start, we advance a server-side fine-tuning strategy to derive the global model, and propose a dynamic self-distillation (DSD) to procure more resilient personalized models simultaneously. Comprehensive experiments underscore the substantial gains of our approach across both global and personalized models, achieved within just one-shot and five communication(s).
Exploiting Vulnerabilities in Speech Translation Systems through Targeted Adversarial Attacks
Mar 05, 2025As speech translation (ST) systems become increasingly prevalent, understanding their vulnerabilities is crucial for ensuring robust and reliable communication. However, limited work has explored this issue in depth. This paper explores methods of compromising these systems through imperceptible audio manipulations. Specifically, we present two innovative approaches: (1) the injection of perturbation into source audio, and (2) the generation of adversarial music designed to guide targeted translation, while also conducting more practical over-the-air attacks in the physical world. Our experiments reveal that carefully crafted audio perturbations can mislead translation models to produce targeted, harmful outputs, while adversarial music achieve this goal more covertly, exploiting the natural imperceptibility of music. These attacks prove effective across multiple languages and translation models, highlighting a systemic vulnerability in current ST architectures. The implications of this research extend beyond immediate security concerns, shedding light on the interpretability and robustness of neural speech processing systems. Our findings underscore the need for advanced defense mechanisms and more resilient architectures in the realm of audio systems. More details and samples can be found at https://adv-st.github.io.
RelaCtrl: Relevance-Guided Efficient Control for Diffusion Transformers
Feb 21, 2025



The Diffusion Transformer plays a pivotal role in advancing text-to-image and text-to-video generation, owing primarily to its inherent scalability. However, existing controlled diffusion transformer methods incur significant parameter and computational overheads and suffer from inefficient resource allocation due to their failure to account for the varying relevance of control information across different transformer layers. To address this, we propose the Relevance-Guided Efficient Controllable Generation framework, RelaCtrl, enabling efficient and resource-optimized integration of control signals into the Diffusion Transformer. First, we evaluate the relevance of each layer in the Diffusion Transformer to the control information by assessing the "ControlNet Relevance Score"-i.e., the impact of skipping each control layer on both the quality of generation and the control effectiveness during inference. Based on the strength of the relevance, we then tailor the positioning, parameter scale, and modeling capacity of the control layers to reduce unnecessary parameters and redundant computations. Additionally, to further improve efficiency, we replace the self-attention and FFN in the commonly used copy block with the carefully designed Two-Dimensional Shuffle Mixer (TDSM), enabling efficient implementation of both the token mixer and channel mixer. Both qualitative and quantitative experimental results demonstrate that our approach achieves superior performance with only 15% of the parameters and computational complexity compared to PixArt-delta.
CORBA: Contagious Recursive Blocking Attacks on Multi-Agent Systems Based on Large Language Models
Feb 20, 2025Large Language Model-based Multi-Agent Systems (LLM-MASs) have demonstrated remarkable real-world capabilities, effectively collaborating to complete complex tasks. While these systems are designed with safety mechanisms, such as rejecting harmful instructions through alignment, their security remains largely unexplored. This gap leaves LLM-MASs vulnerable to targeted disruptions. In this paper, we introduce Contagious Recursive Blocking Attacks (Corba), a novel and simple yet highly effective attack that disrupts interactions between agents within an LLM-MAS. Corba leverages two key properties: its contagious nature allows it to propagate across arbitrary network topologies, while its recursive property enables sustained depletion of computational resources. Notably, these blocking attacks often involve seemingly benign instructions, making them particularly challenging to mitigate using conventional alignment methods. We evaluate Corba on two widely-used LLM-MASs, namely, AutoGen and Camel across various topologies and commercial models. Additionally, we conduct more extensive experiments in open-ended interactive LLM-MASs, demonstrating the effectiveness of Corba in complex topology structures and open-source models. Our code is available at: https://github.com/zhrli324/Corba.