 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Human-Object Interaction Detection with Text-to-Image Diffusion Model
May 20, 2023This paper investigates the problem of the current HOI detection methods and introduces DiffHOI, a novel HOI detection scheme grounded on a pre-trained text-image diffusion model, which enhances the detector's performance via improved data diversity and HOI representation. We demonstrate that the internal representation space of a frozen text-to-image diffusion model is highly relevant to verb concepts and their corresponding context. Accordingly, we propose an adapter-style tuning method to extract the various semantic associated representation from a frozen diffusion model and CLIP model to enhance the human and object representations from the pre-trained detector, further reducing the ambiguity in interaction prediction. Moreover, to fill in the gaps of HOI datasets, we propose SynHOI, a class-balance, large-scale, and high-diversity synthetic dataset containing over 140K HOI images with fully triplet annotations. It is built using an automatic and scalable pipeline designed to scale up the generation of diverse and high-precision HOI-annotated data. SynHOI could effectively relieve the long-tail issue in existing datasets and facilitate learning interaction representations. Extensive experiments demonstrate that DiffHOI significantly outperforms the state-of-the-art in regular detection (i.e., 41.50 mAP) and zero-shot detection. Furthermore, SynHOI can improve the performance of model-agnostic and backbone-agnostic HOI detection, particularly exhibiting an outstanding 11.55% mAP improvement in rare classes.
Qualifying Chinese Medical Licensing Examination with Knowledge Enhanced Generative Pre-training Model
May 17, 2023Generative Pre-Training (GPT) models like ChatGPT have demonstrated exceptional performance in various Natural Language Processing (NLP) tasks. Although ChatGPT has been integrated into the overall workflow to boost efficiency in many domains, the lack of flexibility in the finetuning process hinders its applications in areas that demand extensive domain expertise and semantic knowledge, such as healthcare. In this paper, we evaluate ChatGPT on the China National Medical Licensing Examination (CNMLE) and propose a novel approach to improve ChatGPT from two perspectives: integrating medical domain knowledge and enabling few-shot learning. By using a simple but effective retrieval method, medical background knowledge is extracted as semantic instructions to guide the inference of ChatGPT. Similarly, relevant medical questions are identified and fed as demonstrations to ChatGPT. Experimental results show that directly applying ChatGPT fails to qualify the CNMLE at a score of 51 (i.e., only 51\% of questions are answered correctly). While our knowledge-enhanced model achieves a high score of 70 on CNMLE-2022 which not only passes the qualification but also surpasses the average score of humans (61). This research demonstrates the potential of knowledge-enhanced ChatGPT to serve as versatile medical assistants, capable of analyzing real-world medical problems in a more accessible, user-friendly, and adaptable manner.
CDFI: Cross Domain Feature Interaction for Robust Bronchi Lumen Detection
Apr 18, 2023



Endobronchial intervention is increasingly used as a minimally invasive means for the treatment of pulmonary diseases. In order to reduce the difficulty of manipulation in complex airway networks, robust lumen detection is essential for intraoperative guidance. However, these methods are sensitive to visual artifacts which are inevitable during the surgery. In this work, a cross domain feature interaction (CDFI) network is proposed to extract the structural features of lumens, as well as to provide artifact cues to characterize the visual features. To effectively extract the structural and artifact features, the Quadruple Feature Constraints (QFC) module is designed to constrain the intrinsic connections of samples with various imaging-quality. Furthermore, we design a Guided Feature Fusion (GFF) module to supervise the model for adaptive feature fusion based on different types of artifacts. Results show that the features extracted by the proposed method can preserve the structural information of lumen in the presence of large visual variations, bringing much-improved lumen detection accuracy.
RF-GNN: Random Forest Boosted Graph Neural Network for Social Bot Detection
Apr 14, 2023



The presence of a large number of bots on social media leads to adverse effects. Although Random forest algorithm is widely used in bot detection and can significantly enhance the performance of weak classifiers, it cannot utilize the interaction between accounts. This paper proposes a Random Forest boosted Graph Neural Network for social bot detection, called RF-GNN, which employs graph neural networks (GNNs) as the base classifiers to construct a random forest, effectively combining the advantages of ensemble learning and GNNs to improve the accuracy and robustness of the model. Specifically, different subgraphs are constructed as different training sets through node sampling, feature selection, and edge dropout. Then, GNN base classifiers are trained using various subgraphs, and the remaining features are used for training Fully Connected Netural Network (FCN). The outputs of GNN and FCN are aligned in each branch. Finally, the outputs of all branches are aggregated to produce the final result. Moreover, RF-GNN is compatible with various widely-used GNNs for node classification. Extensive experimental results demonstrate that the proposed method obtains better performance than other state-of-the-art methods.
Semantic Human Parsing via Scalable Semantic Transfer over Multiple Label Domains
Apr 09, 2023This paper presents Scalable Semantic Transfer (SST), a novel training paradigm, to explore how to leverage the mutual benefits of the data from different label domains (i.e. various levels of label granularity) to train a powerful human parsing network. In practice, two common application scenarios are addressed, termed universal parsing and dedicated parsing, where the former aims to learn homogeneous human representations from multiple label domains and switch predictions by only using different segmentation heads, and the latter aims to learn a specific domain prediction while distilling the semantic knowledge from other domains. The proposed SST has the following appealing benefits: (1) it can capably serve as an effective training scheme to embed semantic associations of human body parts from multiple label domains into the human representation learning process; (2) it is an extensible semantic transfer framework without predetermining the overall relations of multiple label domains, which allows continuously adding human parsing datasets to promote the training. (3) the relevant modules are only used for auxiliary training and can be removed during inference, eliminating the extra reasoning cost. Experimental results demonstrate SST can effectively achieve promising universal human parsing performance as well as impressive improvements compared to its counterparts on three human parsing benchmarks (i.e., PASCAL-Person-Part, ATR, and CIHP). Code is available at https://github.com/yangjie-cv/SST.
Learning with Explicit Shape Priors for Medical Image Segmentation
Mar 31, 2023



Medical image segmentation is considered as the basic step for medical image analysis and surgical intervention. And many previous works attempted to incorporate shape priors for designing segmentation models, which is beneficial to attain finer masks with anatomical shape information. Here in our work, we detailedly discuss three types of segmentation models with shape priors, which consist of atlas-based models, statistical-based models and UNet-based models. On the ground that the former two kinds of methods show a poor generalization ability, UNet-based models have dominated the field of medical image segmentation in recent years. However, existing UNet-based models tend to employ implicit shape priors, which do not have a good interpretability and generalization ability on different organs with distinctive shapes. Thus, we proposed a novel shape prior module (SPM), which could explicitly introduce shape priors to promote the segmentation performance of UNet-based models. To evaluate the effectiveness of SPM, we conduct experiments on three challenging public datasets. And our proposed model achieves state-of-the-art performance. Furthermore, SPM shows an outstanding generalization ability on different classic convolution-neural-networks (CNNs) and recent Transformer-based backbones, which can serve as a plug-and-play structure for the segmentation task of different datasets.
SoftCLIP: Softer Cross-modal Alignment Makes CLIP Stronger
Mar 30, 2023



During the preceding biennium, vision-language pre-training has achieved noteworthy success on several downstream tasks. Nevertheless, acquiring high-quality image-text pairs, where the pairs are entirely exclusive of each other, remains a challenging task, and noise exists in the commonly used datasets. To address this issue, we propose SoftCLIP, a novel approach that relaxes the strict one-to-one constraint and achieves a soft cross-modal alignment by introducing a softened target, which is generated from the fine-grained intra-modal self-similarity. The intra-modal guidance is indicative to enable two pairs have some local similarities and model many-to-many relationships between the two modalities. Besides, since the positive still dominates in the softened target distribution, we disentangle the negatives in the distribution to further boost the relation alignment with the negatives in the cross-modal learning. Extensive experiments demonstrate the effectiveness of SoftCLIP. In particular, on ImageNet zero-shot classification task, using CC3M/CC12M as pre-training dataset, SoftCLIP brings a top-1 accuracy improvement of 6.8%/7.2% over the CLIP baseline.
Inherent Consistent Learning for Accurate Semi-supervised Medical Image Segmentation
Mar 28, 2023



Semi-supervised medical image segmentation has attracted much attention in recent years because of the high cost of medical image annotations. In this paper, we propose a novel Inherent Consistent Learning (ICL) method, which aims to learn robust semantic category representations through the semantic consistency guidance of labeled and unlabeled data to help segmentation. In practice, we introduce two external modules namely Supervised Semantic Proxy Adaptor (SSPA) and Unsupervised Semantic Consistent Learner (USCL) that based on the attention mechanism to align the semantic category representations of labeled and unlabeled data, as well as update the global semantic representations over the entire training set. The proposed ICL is a plug-and-play scheme for various network architectures and the two modules are not involved in the testing stage. Experimental results on three public benchmarks show that the proposed method can outperform the state-of-the-art especially when the number of annotated data is extremely limited. Code is available at: https://github.com/zhuye98/ICL.git.
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Mar 20, 2023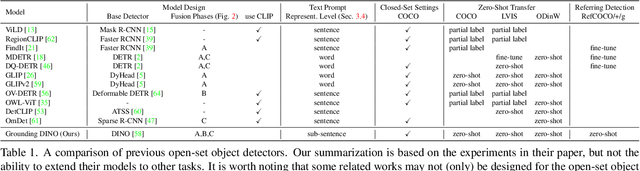
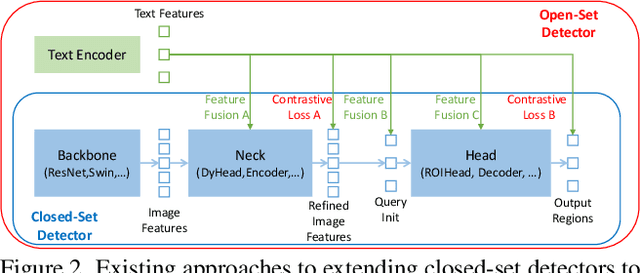
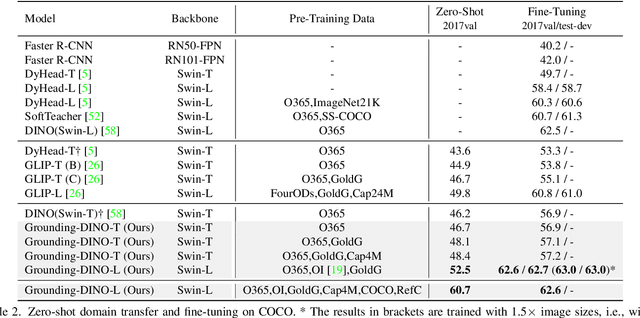
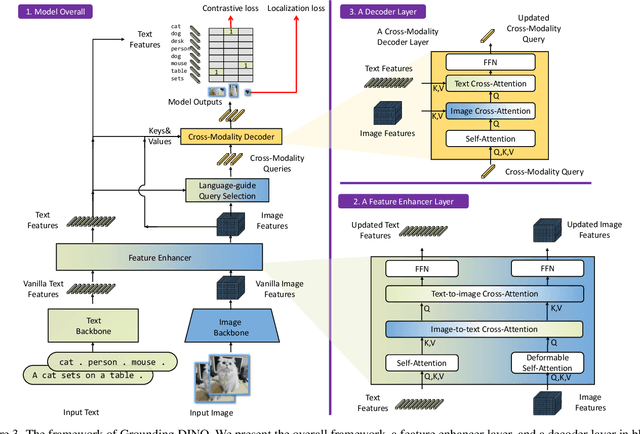
In this paper, we present an open-set object detector, called Grounding DINO, by marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. The key solution of open-set object detection is introducing language to a closed-set detector for open-set concept generalization. To effectively fuse language and vision modalities, we conceptually divide a closed-set detector into three phases and propose a tight fusion solution, which includes a feature enhancer, a language-guided query selection, and a cross-modality decoder for cross-modality fusion. While previous works mainly evaluate open-set object detection on novel categories, we propose to also perform evaluations on referring expression comprehension for objects specified with attributes. Grounding DINO performs remarkably well on all three settings, including benchmarks on COCO, LVIS, ODinW, and RefCOCO/+/g. Grounding DINO achieves a $52.5$ AP on the COCO detection zero-shot transfer benchmark, i.e., without any training data from COCO. It sets a new record on the ODinW zero-shot benchmark with a mean $26.1$ AP. Code will be available at \url{https://github.com/IDEA-Research/GroundingDINO}.
Exploring Social Media for Early Detection of Depression in COVID-19 Patients
Feb 23, 2023



The COVID-19 pandemic has caused substantial damage to global health. Even though three years have passed, the world continues to struggle with the virus. Concerns are growing about the impact of COVID-19 on the mental health of infected individuals, who are more likely to experience depression, which can have long-lasting consequences for both the affected individuals and the world. Detection and intervention at an early stage can reduce the risk of depression in COVID-19 patients. In this paper, we investigated the relationship between COVID-19 infection and depression through social media analysis. Firstly, we managed a dataset of COVID-19 patients that contains information about their social media activity both before and after infection. Secondly,We conducted an extensive analysis of this dataset to investigate the characteristic of COVID-19 patients with a higher risk of depression. Thirdly, we proposed a deep neural network for early prediction of depression risk. This model considers daily mood swings as a psychiatric signal and incorporates textual and emotional characteristics via knowledge distillation. Experimental results demonstrate that our proposed framework outperforms baselines in detecting depression risk, with an AUROC of 0.9317 and an AUPRC of 0.8116. Our model has the potential to enable public health organizations to initiate prompt intervention with high-risk patients