 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Has AI Come in Liver Fibrosis Staging? A Large-Scale Real-World Dataset and Benchmark
May 25, 2026Despite years of methodological progress, how far AI has come in liver fibrosis staging has never been systematically evaluated under the heterogeneous, multi-center conditions that define clinical practice. To address this gap, we introduce LiFS, a large-scale dataset and benchmark derived from the MICCAI 2025 CARE-Liver challenge, comprising 610 patients across multiple centers and scanners with multi-sequence MRI. To the best of our knowledge, LiFS is the first benchmark providing complete gadoxetic acid-enhanced sequences with histopathology-confirmed annotations from diverse real-world scanners. Through systematic evaluation of 9 independently developed methods selected from 96 registered teams against in-cohort radiologist reference results, our findings address how far current AI has progressed toward clinical-level liver fibrosis staging from three complementary perspectives. First, against radiologists, the best AI methods were broadly comparable to the senior radiologist and significantly exceeded the junior radiologist in selected settings, while median AI performance generally approached junior-radiologist levels. Second, from a data perspective, cross-center heterogeneity, label imbalance, and contrast-enhanced sequence variability emerge as the dominant challenges for AI methods. Third, from a technical perspective, methodological design choices, including spatial registration, input dimensionality, multi-modal fusion strategy, and backbone architecture, appear to modulate cross-center robustness, although no single choice alone closes the gap. Overall, LiFS provides a rigorous real-world benchmark for positioning the current state of AI in liver fibrosis staging and for enabling future research on the key challenges that limit clinically reliable deployment.
EndoSERV: A Vision-based Endoluminal Robot Navigation System
Mar 09, 2026Robot-assisted endoluminal procedures are increasingly used for early cancer intervention. However, the intricate, narrow and tortuous pathways within the luminal anatomy pose substantial difficulties for robot navigation. Vision-based navigation offers a promising solution, but existing localization approaches are error-prone due to tissue deformation, in vivo artifacts and a lack of distinctive landmarks for consistent localization. This paper presents a novel EndoSERV localization method to address these challenges. It includes two main parts, \textit{i.e.}, \textbf{SE}gment-to-structure and \textbf{R}eal-to-\textbf{V}irtual mapping, and hence the name. For long-range and complex luminal structures, we divide them into smaller sub-segments and estimate the odometry independently. To cater for label insufficiency, an efficient transfer technique maps real image features to the virtual domain to use virtual pose ground truth. The training phases of EndoSERV include an offline pretraining to extract texture-agnostic features, and an online phase that adapts to real-world conditions. Extensive experiments based on both public and clinical datasets have been performed to demonstrate the effectiveness of the method even without any real pose labels.
Long-Short Term Agents for Pure-Vision Bronchoscopy Robotic Autonomy
Mar 09, 2026Accurate intraoperative navigation is essential for robot-assisted endoluminal intervention, but remains difficult because of limited endoscopic field of view and dynamic artifacts. Existing navigation platforms often rely on external localization technologies, such as electromagnetic tracking or shape sensing, which increase hardware complexity and remain vulnerable to intraoperative anatomical mismatch. We present a vision-only autonomy framework that performs long-horizon bronchoscopic navigation using preoperative CT-derived virtual targets and live endoscopic video, without external tracking during navigation. The framework uses hierarchical long-short agents: a short-term reactive agent for continuous low-latency motion control, and a long-term strategic agent for decision support at anatomically ambiguous points. When their recommendations conflict, a world-model critic predicts future visual states for candidate actions and selects the action whose predicted state best matches the target view. We evaluated the system in a high-fidelity airway phantom, three ex vivo porcine lungs, and a live porcine model. The system reached all planned segmental targets in the phantom, maintained 80\% success to the eighth generation ex vivo, and achieved in vivo navigation performance comparable to the expert bronchoscopist. These results support the preclinical feasibility of sensor-free autonomous bronchoscopic navigation.
Synergistic Development of Perovskite Memristors and Algorithms for Robust Analog Computing
Dec 03, 2024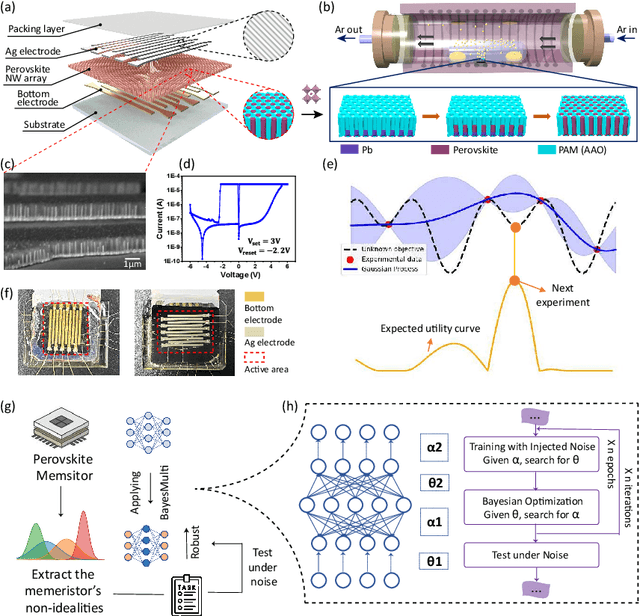

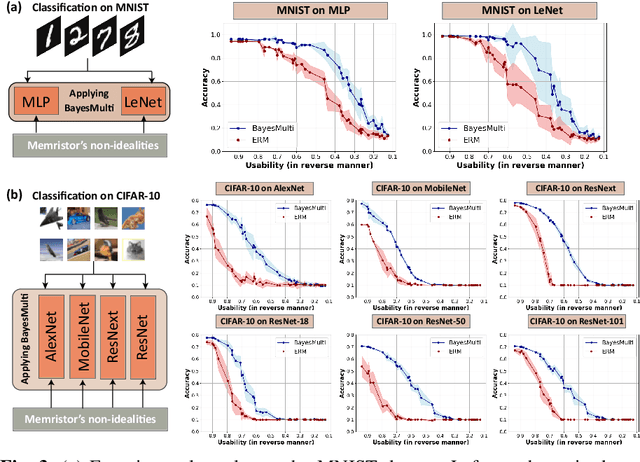
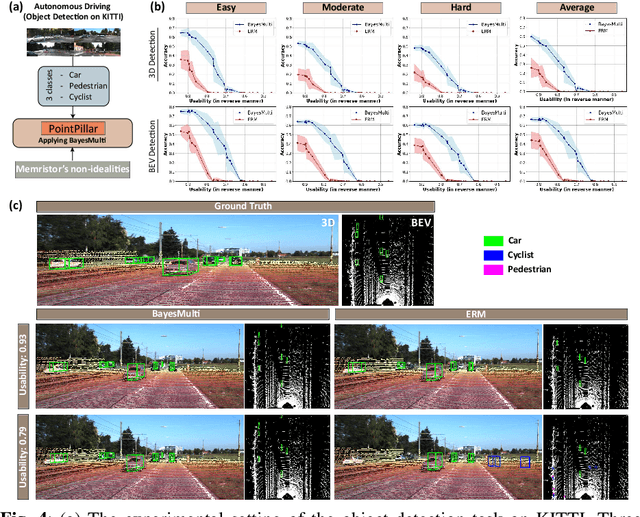
Analog computing using non-volatile memristors has emerged as a promising solution for energy-efficient deep learning. New materials, like perovskites-based memristors are recently attractive due to their cost-effectiveness, energy efficiency and flexibility. Yet, challenges in material diversity and immature fabrications require extensive experimentation for device development. Moreover, significant non-idealities in these memristors often impede them for computing. Here, we propose a synergistic methodology to concurrently optimize perovskite memristor fabrication and develop robust analog DNNs that effectively address the inherent non-idealities of these memristors. Employing Bayesian optimization (BO) with a focus on usability, we efficiently identify optimal materials and fabrication conditions for perovskite memristors. Meanwhile, we developed "BayesMulti", a DNN training strategy utilizing BO-guided noise injection to improve the resistance of analog DNNs to memristor imperfections. Our approach theoretically ensures that within a certain range of parameter perturbations due to memristor non-idealities, the prediction outcomes remain consistent. Our integrated approach enables use of analog computing in much deeper and wider networks, which significantly outperforms existing methods in diverse tasks like image classification, autonomous driving, species identification, and large vision-language models, achieving up to 100-fold improvements. We further validate our methodology on a 10$\times$10 optimized perovskite memristor crossbar, demonstrating high accuracy in a classification task and low energy consumption. This study offers a versatile solution for efficient optimization of various analog computing systems, encompassing both devices and algorithms.
From Real Artifacts to Virtual Reference: A Robust Framework for Translating Endoscopic Images
Oct 23, 2024Domain adaptation, which bridges the distributions across different modalities, plays a crucial role in multimodal medical image analysis. In endoscopic imaging, combining pre-operative data with intra-operative imaging is important for surgical planning and navigation. However, existing domain adaptation methods are hampered by distribution shift caused by in vivo artifacts, necessitating robust techniques for aligning noisy and artifact abundant patient endoscopic videos with clean virtual images reconstructed from pre-operative tomographic data for pose estimation during intraoperative guidance. This paper presents an artifact-resilient image translation method and an associated benchmark for this purpose. The method incorporates a novel ``local-global'' translation framework and a noise-resilient feature extraction strategy. For the former, it decouples the image translation process into a local step for feature denoising, and a global step for global style transfer. For feature extraction, a new contrastive learning strategy is proposed, which can extract noise-resilient features for establishing robust correspondence across domains. Detailed validation on both public and in-house clinical datasets has been conducted, demonstrating significantly improved performance compared to the current state-of-the-art.
LNQ 2023 challenge: Benchmark of weakly-supervised techniques for mediastinal lymph node quantification
Aug 19, 2024



Accurate assessment of lymph node size in 3D CT scans is crucial for cancer staging, therapeutic management, and monitoring treatment response. Existing state-of-the-art segmentation frameworks in medical imaging often rely on fully annotated datasets. However, for lymph node segmentation, these datasets are typically small due to the extensive time and expertise required to annotate the numerous lymph nodes in 3D CT scans. Weakly-supervised learning, which leverages incomplete or noisy annotations, has recently gained interest in the medical imaging community as a potential solution. Despite the variety of weakly-supervised techniques proposed, most have been validated only on private datasets or small publicly available datasets. To address this limitation, the Mediastinal Lymph Node Quantification (LNQ) challenge was organized in conjunction with the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023). This challenge aimed to advance weakly-supervised segmentation methods by providing a new, partially annotated dataset and a robust evaluation framework. A total of 16 teams from 5 countries submitted predictions to the validation leaderboard, and 6 teams from 3 countries participated in the evaluation phase. The results highlighted both the potential and the current limitations of weakly-supervised approaches. On one hand, weakly-supervised approaches obtained relatively good performance with a median Dice score of $61.0\%$. On the other hand, top-ranked teams, with a median Dice score exceeding $70\%$, boosted their performance by leveraging smaller but fully annotated datasets to combine weak supervision and full supervision. This highlights both the promise of weakly-supervised methods and the ongoing need for high-quality, fully annotated data to achieve higher segmentation performance.
Efficient Domain Adaptation for Endoscopic Visual Odometry
Mar 16, 2024



Visual odometry plays a crucial role in endoscopic imaging, yet the scarcity of realistic images with ground truth poses poses a significant challenge. Therefore, domain adaptation offers a promising approach to bridge the pre-operative planning domain with the intra-operative real domain for learning odometry information. However, existing methodologies suffer from inefficiencies in the training time. In this work, an efficient neural style transfer framework for endoscopic visual odometry is proposed, which compresses the time from pre-operative planning to testing phase to less than five minutes. For efficient traing, this work focuses on training modules with only a limited number of real images and we exploit pre-operative prior information to dramatically reduce training duration. Moreover, during the testing phase, we propose a novel Test Time Adaptation (TTA) method to mitigate the gap in lighting conditions between training and testing datasets. Experimental evaluations conducted on two public endoscope datasets showcase that our method achieves state-of-the-art accuracy in visual odometry tasks while boasting the fastest training speeds. These results demonstrate significant promise for intra-operative surgery applications.
CDFI: Cross Domain Feature Interaction for Robust Bronchi Lumen Detection
Apr 18, 2023



Endobronchial intervention is increasingly used as a minimally invasive means for the treatment of pulmonary diseases. In order to reduce the difficulty of manipulation in complex airway networks, robust lumen detection is essential for intraoperative guidance. However, these methods are sensitive to visual artifacts which are inevitable during the surgery. In this work, a cross domain feature interaction (CDFI) network is proposed to extract the structural features of lumens, as well as to provide artifact cues to characterize the visual features. To effectively extract the structural and artifact features, the Quadruple Feature Constraints (QFC) module is designed to constrain the intrinsic connections of samples with various imaging-quality. Furthermore, we design a Guided Feature Fusion (GFF) module to supervise the model for adaptive feature fusion based on different types of artifacts. Results show that the features extracted by the proposed method can preserve the structural information of lumen in the presence of large visual variations, bringing much-improved lumen detection accuracy.
Multi-site, Multi-domain Airway Tree Modeling : A Public Benchmark for Pulmonary Airway Segmentation
Mar 10, 2023



Open international challenges are becoming the de facto standard for assessing computer vision and image analysis algorithms. In recent years, new methods have extended the reach of pulmonary airway segmentation that is closer to the limit of image resolution. Since EXACT'09 pulmonary airway segmentation, limited effort has been directed to quantitative comparison of newly emerged algorithms driven by the maturity of deep learning based approaches and clinical drive for resolving finer details of distal airways for early intervention of pulmonary diseases. Thus far, public annotated datasets are extremely limited, hindering the development of data-driven methods and detailed performance evaluation of new algorithms. To provide a benchmark for the medical imaging community, we organized the Multi-site, Multi-domain Airway Tree Modeling (ATM'22), which was held as an official challenge event during the MICCAI 2022 conference. ATM'22 provides large-scale CT scans with detailed pulmonary airway annotation, including 500 CT scans (300 for training, 50 for validation, and 150 for testing). The dataset was collected from different sites and it further included a portion of noisy COVID-19 CTs with ground-glass opacity and consolidation. Twenty-three teams participated in the entire phase of the challenge and the algorithms for the top ten teams are reviewed in this paper. Quantitative and qualitative results revealed that deep learning models embedded with the topological continuity enhancement achieved superior performance in general. ATM'22 challenge holds as an open-call design, the training data and the gold standard evaluation are available upon successful registration via its homepage.
MR Elastography with Optimization-Based Phase Unwrapping and Traveling Wave Expansion-based Neural Network (TWENN)
Jan 06, 2023



Magnetic Resonance Elastography (MRE) can characterize biomechanical properties of soft tissue for disease diagnosis and treatment planning. However, complicated wavefields acquired from MRE coupled with noise pose challenges for accurate displacement extraction and modulus estimation. Here we propose a pipeline for processing MRE images using optimization-based displacement extraction and Traveling Wave Expansion-based Neural Network (TWENN) modulus estimation. Phase unwrapping and displacement extraction were achieved by optimization of an objective function with Dual Data Consistency (Dual-DC). A complex-valued neural network using displacement covariance as input has been constructed for the estimation of complex wavenumbers. A model of traveling wave expansion is used to generate training datasets with different levels of noise for the network. The complex shear modulus map is obtained by a fusion of multifrequency and multidirectional data. Validation using images of brain and liver simulation demonstrates the practical value of the proposed pipeline, which can estimate the biomechanical properties with minimum root-mean-square-errors compared with state-of-the-art methods. Applications of the proposed method for processing MRE images of phantom, brain, and liver show clear anatomical features and that the pipeline is robust to noise and has a good generalization capability.