 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Enabled Elastic Network Topology for Distributed ISAC Service Provisioning
Dec 23, 2025



Conventional mobile networks, including both localized cell-centric and cooperative cell-free networks (CCN/CFN), are built upon rigid network topologies. However, neither architecture is adequate to flexibly support distributed integrated sensing and communication (ISAC) services, due to the increasing difficulty of aligning spatiotemporally distributed heterogeneous service demands with available radio resources. In this paper, we propose an elastic network topology (ENT) for distributed ISAC service provisioning, where multiple co-existing localized CCNs can be dynamically aggregated into CFNs with expanded boundaries for federated network operation. This topology elastically orchestrates localized CCN and federated CFN boundaries to balance signaling overhead and distributed resource utilization, thereby enabling efficient ISAC service provisioning. A two-phase operation protocol is then developed. In Phase I, each CCN autonomously classifies ISAC services as either local or federated and partitions its resources into dedicated and shared segments. In Phase II, each CCN employs its dedicated resources for local ISAC services, while the aggregated CFN consolidates shared resources from its constituent CCNs to cooperatively deliver federated services. Furthermore, we design a utility-to-signaling ratio (USR) to quantify the tradeoff between sensing/communication utility and signaling overhead. Consequently, a USR maximization problem is formulated by jointly optimizing the network topology (i.e., service classification and CCN aggregation) and the allocation of dedicated and shared resources. However, this problem is challenging due to its distributed optimization nature and the absence of complete channel state information. To address this problem efficiently, we propose a multi-agent deep reinforcement learning (MADRL) framework with centralized training and decentralized execution.
DeCo-VAE: Learning Compact Latents for Video Reconstruction via Decoupled Representation
Nov 18, 2025Existing video Variational Autoencoders (VAEs) generally overlook the similarity between frame contents, leading to redundant latent modeling. In this paper, we propose decoupled VAE (DeCo-VAE) to achieve compact latent representation. Instead of encoding RGB pixels directly, we decompose video content into distinct components via explicit decoupling: keyframe, motion and residual, and learn dedicated latent representation for each. To avoid cross-component interference, we design dedicated encoders for each decoupled component and adopt a shared 3D decoder to maintain spatiotemporal consistency during reconstruction. We further utilize a decoupled adaptation strategy that freezes partial encoders while training the others sequentially, ensuring stable training and accurate learning of both static and dynamic features. Extensive quantitative and qualitative experiments demonstrate that DeCo-VAE achieves superior video reconstruction performance.
From Prompt Optimization to Multi-Dimensional Credibility Evaluation: Enhancing Trustworthiness of Chinese LLM-Generated Liver MRI Reports
Oct 27, 2025Large language models (LLMs) have demonstrated promising performance in generating diagnostic conclusions from imaging findings, thereby supporting radiology reporting, trainee education, and quality control. However, systematic guidance on how to optimize prompt design across different clinical contexts remains underexplored. Moreover, a comprehensive and standardized framework for assessing the trustworthiness of LLM-generated radiology reports is yet to be established. This study aims to enhance the trustworthiness of LLM-generated liver MRI reports by introducing a Multi-Dimensional Credibility Assessment (MDCA) framework and providing guidance on institution-specific prompt optimization. The proposed framework is applied to evaluate and compare the performance of several advanced LLMs, including Kimi-K2-Instruct-0905, Qwen3-235B-A22B-Instruct-2507, DeepSeek-V3, and ByteDance-Seed-OSS-36B-Instruct, using the SiliconFlow platform.
Deep Compositional Phase Diffusion for Long Motion Sequence Generation
Oct 16, 2025



Recent research on motion generation has shown significant progress in generating semantically aligned motion with singular semantics. However, when employing these models to create composite sequences containing multiple semantically generated motion clips, they often struggle to preserve the continuity of motion dynamics at the transition boundaries between clips, resulting in awkward transitions and abrupt artifacts. To address these challenges, we present Compositional Phase Diffusion, which leverages the Semantic Phase Diffusion Module (SPDM) and Transitional Phase Diffusion Module (TPDM) to progressively incorporate semantic guidance and phase details from adjacent motion clips into the diffusion process. Specifically, SPDM and TPDM operate within the latent motion frequency domain established by the pre-trained Action-Centric Motion Phase Autoencoder (ACT-PAE). This allows them to learn semantically important and transition-aware phase information from variable-length motion clips during training. Experimental results demonstrate the competitive performance of our proposed framework in generating compositional motion sequences that align semantically with the input conditions, while preserving phase transitional continuity between preceding and succeeding motion clips. Additionally, motion inbetweening task is made possible by keeping the phase parameter of the input motion sequences fixed throughout the diffusion process, showcasing the potential for extending the proposed framework to accommodate various application scenarios. Codes are available at https://github.com/asdryau/TransPhase.
Data-driven solar forecasting enables near-optimal economic decisions
Sep 08, 2025Solar energy adoption is critical to achieving net-zero emissions. However, it remains difficult for many industrial and commercial actors to decide on whether they should adopt distributed solar-battery systems, which is largely due to the unavailability of fast, low-cost, and high-resolution irradiance forecasts. Here, we present SunCastNet, a lightweight data-driven forecasting system that provides 0.05$^\circ$, 10-minute resolution predictions of surface solar radiation downwards (SSRD) up to 7 days ahead. SunCastNet, coupled with reinforcement learning (RL) for battery scheduling, reduces operational regret by 76--93\% compared to robust decision making (RDM). In 25-year investment backtests, it enables up to five of ten high-emitting industrial sectors per region to cross the commercial viability threshold of 12\% Internal Rate of Return (IRR). These results show that high-resolution, long-horizon solar forecasts can directly translate into measurable economic gains, supporting near-optimal energy operations and accelerating renewable deployment.
Sticker-TTS: Learn to Utilize Historical Experience with a Sticker-driven Test-Time Scaling Framework
Sep 05, 2025Large reasoning models (LRMs) have exhibited strong performance on complex reasoning tasks, with further gains achievable through increased computational budgets at inference. However, current test-time scaling methods predominantly rely on redundant sampling, ignoring the historical experience utilization, thereby limiting computational efficiency. To overcome this limitation, we propose Sticker-TTS, a novel test-time scaling framework that coordinates three collaborative LRMs to iteratively explore and refine solutions guided by historical attempts. At the core of our framework are distilled key conditions-termed stickers-which drive the extraction, refinement, and reuse of critical information across multiple rounds of reasoning. To further enhance the efficiency and performance of our framework, we introduce a two-stage optimization strategy that combines imitation learning with self-improvement, enabling progressive refinement. Extensive evaluations on three challenging mathematical reasoning benchmarks, including AIME-24, AIME-25, and OlymMATH, demonstrate that Sticker-TTS consistently surpasses strong baselines, including self-consistency and advanced reinforcement learning approaches, under comparable inference budgets. These results highlight the effectiveness of sticker-guided historical experience utilization. Our code and data are available at https://github.com/RUCAIBox/Sticker-TTS.
UniAPO: Unified Multimodal Automated Prompt Optimization
Aug 25, 2025



Prompting is fundamental to unlocking the full potential of large language models. To automate and enhance this process, automatic prompt optimization (APO) has been developed, demonstrating effectiveness primarily in text-only input scenarios. However, extending existing APO methods to multimodal tasks, such as video-language generation introduces two core challenges: (i) visual token inflation, where long visual token sequences restrict context capacity and result in insufficient feedback signals; (ii) a lack of process-level supervision, as existing methods focus on outcome-level supervision and overlook intermediate supervision, limiting prompt optimization. We present UniAPO: Unified Multimodal Automated Prompt Optimization, the first framework tailored for multimodal APO. UniAPO adopts an EM-inspired optimization process that decouples feedback modeling and prompt refinement, making the optimization more stable and goal-driven. To further address the aforementioned challenges, we introduce a short-long term memory mechanism: historical feedback mitigates context limitations, while historical prompts provide directional guidance for effective prompt optimization. UniAPO achieves consistent gains across text, image, and video benchmarks, establishing a unified framework for efficient and transferable prompt optimization.
OneLoc: Geo-Aware Generative Recommender Systems for Local Life Service
Aug 20, 2025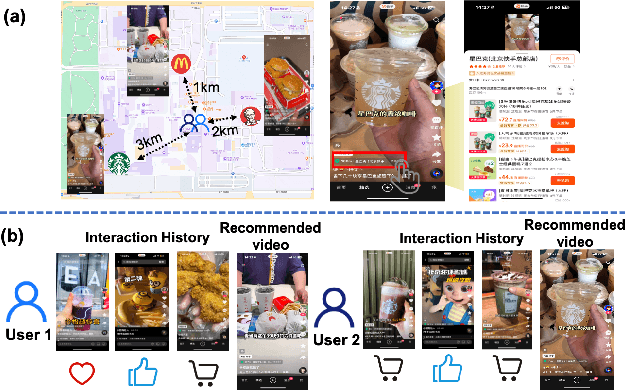
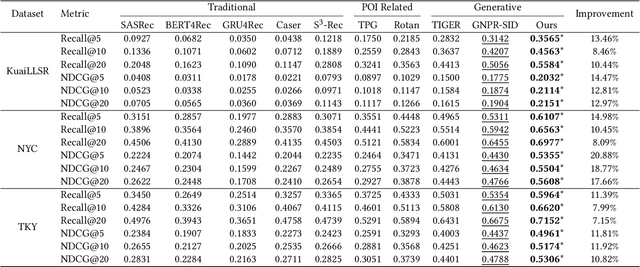
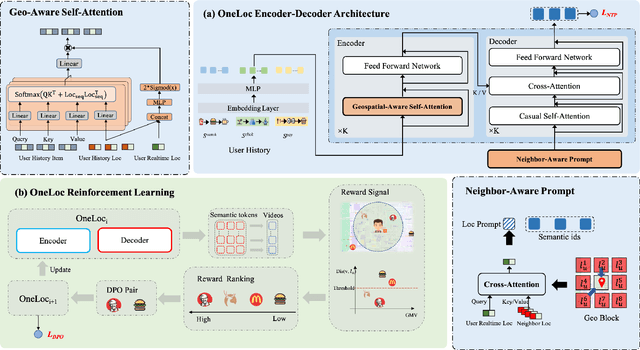

Local life service is a vital scenario in Kuaishou App, where video recommendation is intrinsically linked with store's location information. Thus, recommendation in our scenario is challenging because we should take into account user's interest and real-time location at the same time. In the face of such complex scenarios, end-to-end generative recommendation has emerged as a new paradigm, such as OneRec in the short video scenario, OneSug in the search scenario, and EGA in the advertising scenario. However, in local life service, an end-to-end generative recommendation model has not yet been developed as there are some key challenges to be solved. The first challenge is how to make full use of geographic information. The second challenge is how to balance multiple objectives, including user interests, the distance between user and stores, and some other business objectives. To address the challenges, we propose OneLoc. Specifically, we leverage geographic information from different perspectives: (1) geo-aware semantic ID incorporates both video and geographic information for tokenization, (2) geo-aware self-attention in the encoder leverages both video location similarity and user's real-time location, and (3) neighbor-aware prompt captures rich context information surrounding users for generation. To balance multiple objectives, we use reinforcement learning and propose two reward functions, i.e., geographic reward and GMV reward. With the above design, OneLoc achieves outstanding offline and online performance. In fact, OneLoc has been deployed in local life service of Kuaishou App. It serves 400 million active users daily, achieving 21.016% and 17.891% improvements in terms of gross merchandise value (GMV) and orders numbers.
From Trial-and-Error to Improvement: A Systematic Analysis of LLM Exploration Mechanisms in RLVR
Aug 11, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). Unlike traditional RL approaches, RLVR leverages rule-based feedback to guide LLMs in generating and refining complex reasoning chains -- a process critically dependent on effective exploration strategies. While prior work has demonstrated RLVR's empirical success, the fundamental mechanisms governing LLMs' exploration behaviors remain underexplored. This technical report presents a systematic investigation of exploration capacities in RLVR, covering four main aspects: (1) exploration space shaping, where we develop quantitative metrics to characterize LLMs' capability boundaries; (2) entropy-performance exchange, analyzed across training stages, individual instances, and token-level patterns; and (3) RL performance optimization, examining methods to effectively translate exploration gains into measurable improvements. By unifying previously identified insights with new empirical evidence, this work aims to provide a foundational framework for advancing RLVR systems.
UW-3DGS: Underwater 3D Reconstruction with Physics-Aware Gaussian Splatting
Aug 08, 2025Underwater 3D scene reconstruction faces severe challenges from light absorption, scattering, and turbidity, which degrade geometry and color fidelity in traditional methods like Neural Radiance Fields (NeRF). While NeRF extensions such as SeaThru-NeRF incorporate physics-based models, their MLP reliance limits efficiency and spatial resolution in hazy environments. We introduce UW-3DGS, a novel framework adapting 3D Gaussian Splatting (3DGS) for robust underwater reconstruction. Key innovations include: (1) a plug-and-play learnable underwater image formation module using voxel-based regression for spatially varying attenuation and backscatter; and (2) a Physics-Aware Uncertainty Pruning (PAUP) branch that adaptively removes noisy floating Gaussians via uncertainty scoring, ensuring artifact-free geometry. The pipeline operates in training and rendering stages. During training, noisy Gaussians are optimized end-to-end with underwater parameters, guided by PAUP pruning and scattering modeling. In rendering, refined Gaussians produce clean Unattenuated Radiance Images (URIs) free from media effects, while learned physics enable realistic Underwater Images (UWIs) with accurate light transport. Experiments on SeaThru-NeRF and UWBundle datasets show superior performance, achieving PSNR of 27.604, SSIM of 0.868, and LPIPS of 0.104 on SeaThru-NeRF, with ~65% reduction in floating artifacts.