 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven solar forecasting enables near-optimal economic decisions
Sep 08, 2025Solar energy adoption is critical to achieving net-zero emissions. However, it remains difficult for many industrial and commercial actors to decide on whether they should adopt distributed solar-battery systems, which is largely due to the unavailability of fast, low-cost, and high-resolution irradiance forecasts. Here, we present SunCastNet, a lightweight data-driven forecasting system that provides 0.05$^\circ$, 10-minute resolution predictions of surface solar radiation downwards (SSRD) up to 7 days ahead. SunCastNet, coupled with reinforcement learning (RL) for battery scheduling, reduces operational regret by 76--93\% compared to robust decision making (RDM). In 25-year investment backtests, it enables up to five of ten high-emitting industrial sectors per region to cross the commercial viability threshold of 12\% Internal Rate of Return (IRR). These results show that high-resolution, long-horizon solar forecasts can directly translate into measurable economic gains, supporting near-optimal energy operations and accelerating renewable deployment.
Data-driven Surface Solar Irradiance Estimation using Neural Operators at Global Scale
Nov 13, 2024



Accurate surface solar irradiance (SSI) forecasting is essential for optimizing renewable energy systems, particularly in the context of long-term energy planning on a global scale. This paper presents a pioneering approach to solar radiation forecasting that leverages recent advancements in numerical weather prediction (NWP) and data-driven machine learning weather models. These advances facilitate long, stable rollouts and enable large ensemble forecasts, enhancing the reliability of predictions. Our flexible model utilizes variables forecast by these NWP and AI weather models to estimate 6-hourly SSI at global scale. Developed using NVIDIA Modulus, our model represents the first adaptive global framework capable of providing long-term SSI forecasts. Furthermore, it can be fine-tuned using satellite data, which significantly enhances its performance in the fine-tuned regions, while maintaining accuracy elsewhere. The improved accuracy of these forecasts has substantial implications for the integration of solar energy into power grids, enabling more efficient energy management and contributing to the global transition to renewable energy sources.
Modulated Adaptive Fourier Neural Operators for Temporal Interpolation of Weather Forecasts
Oct 24, 2024



Weather and climate data are often available at limited temporal resolution, either due to storage limitations, or in the case of weather forecast models based on deep learning, their inherently long time steps. The coarse temporal resolution makes it difficult to capture rapidly evolving weather events. To address this limitation, we introduce an interpolation model that reconstructs the atmospheric state between two points in time for which the state is known. The model makes use of a novel network layer that modifies the adaptive Fourier neural operator (AFNO), which has been previously used in weather prediction and other applications of machine learning to physics problems. The modulated AFNO (ModAFNO) layer takes an embedding, here computed from the interpolation target time, as an additional input and applies a learned shift-scale operation inside the AFNO layers to adapt them to the target time. Thus, one model can be used to produce all intermediate time steps. Trained to interpolate between two time steps 6 h apart, the ModAFNO-based interpolation model produces 1 h resolution intermediate time steps that are visually nearly indistinguishable from the actual corresponding 1 h resolution data. The model reduces the RMSE loss of reconstructing the intermediate steps by approximately 50% compared to linear interpolation. We also demonstrate its ability to reproduce the statistics of extreme weather events such as hurricanes and heat waves better than 6 h resolution data. The ModAFNO layer is generic and is expected to be applicable to other problems, including weather forecasting with tunable lead time.
Estimating treatment effects from single-arm trials via latent-variable modeling
Nov 06, 2023Randomized controlled trials (RCTs) are the accepted standard for treatment effect estimation but they can be infeasible due to ethical reasons and prohibitive costs. Single-arm trials, where all patients belong to the treatment group, can be a viable alternative but require access to an external control group. We propose an identifiable deep latent-variable model for this scenario that can also account for missing covariate observations by modeling their structured missingness patterns. Our method uses amortized variational inference to learn both group-specific and identifiable shared latent representations, which can subsequently be used for (i) patient matching if treatment outcomes are not available for the treatment group, or for (ii) direct treatment effect estimation assuming outcomes are available for both groups. We evaluate the model on a public benchmark as well as on a data set consisting of a published RCT study and real-world electronic health records. Compared to previous methods, our results show improved performance both for direct treatment effect estimation as well as for effect estimation via patient matching.
Latent diffusion models for generative precipitation nowcasting with accurate uncertainty quantification
Apr 25, 2023



Diffusion models have been widely adopted in image generation, producing higher-quality and more diverse samples than generative adversarial networks (GANs). We introduce a latent diffusion model (LDM) for precipitation nowcasting - short-term forecasting based on the latest observational data. The LDM is more stable and requires less computation to train than GANs, albeit with more computationally expensive generation. We benchmark it against the GAN-based Deep Generative Models of Rainfall (DGMR) and a statistical model, PySTEPS. The LDM produces more accurate precipitation predictions, while the comparisons are more mixed when predicting whether the precipitation exceeds predefined thresholds. The clearest advantage of the LDM is that it generates more diverse predictions than DGMR or PySTEPS. Rank distribution tests indicate that the distribution of samples from the LDM accurately reflects the uncertainty of the predictions. Thus, LDMs are promising for any applications where uncertainty quantification is important, such as weather and climate.
Thunderstorm nowcasting with deep learning: a multi-hazard data fusion model
Nov 02, 2022Predictions of thunderstorm-related hazards are needed in several sectors, including first responders, infrastructure management and aviation. To address this need, we present a deep learning model that can be adapted to different hazard types. The model can utilize multiple data sources; we use data from weather radar, lightning detection, satellite visible/infrared imagery, numerical weather prediction and digital elevation models. It can be trained to operate with any combination of these sources, such that predictions can still be provided if one or more of the sources become unavailable. We demonstrate the ability of the model to predict lightning, hail and heavy precipitation probabilistically on a 1 km resolution grid, with a time resolution of 5 min and lead times up to 60 min. Shapley values quantify the importance of the different data sources, showing that the weather radar products are the most important predictors for all three hazard types.
Seamless lightning nowcasting with recurrent-convolutional deep learning
Mar 15, 2022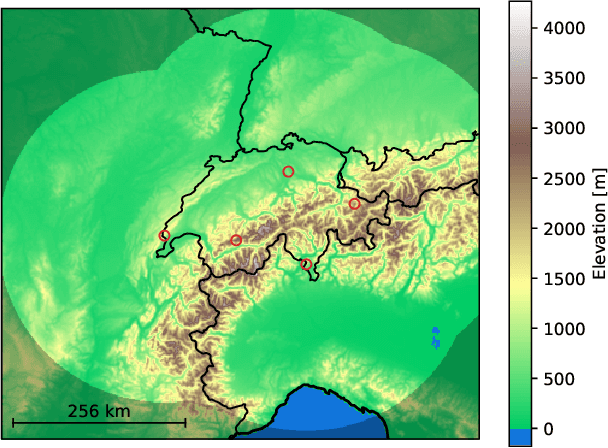


A deep learning model is presented to nowcast the occurrence of lightning at a five-minute time resolution 60 minutes into the future. The model is based on a recurrent-convolutional architecture that allows it to recognize and predict the spatiotemporal development of convection, including the motion, growth and decay of thunderstorm cells. The predictions are performed on a stationary grid, without the use of storm object detection and tracking. The input data, collected from an area in and surrounding Switzerland, comprise ground-based radar data, visible/infrared satellite data and derived cloud products, lightning detection, numerical weather prediction and digital elevation model data. We analyze different alternative loss functions, class weighting strategies and model features, providing guidelines for future studies to select loss functions optimally and to properly calibrate the probabilistic predictions of their model. Based on these analyses, we use focal loss in this study, but conclude that it only provides a small benefit over cross entropy, which is a viable option if recalibration of the model is not practical.
Improvements to short-term weather prediction with recurrent-convolutional networks
Nov 24, 2021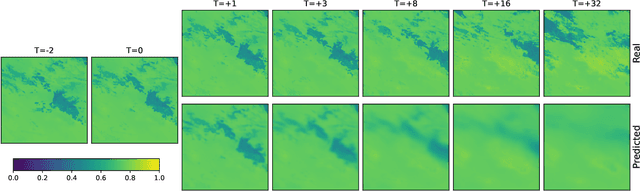

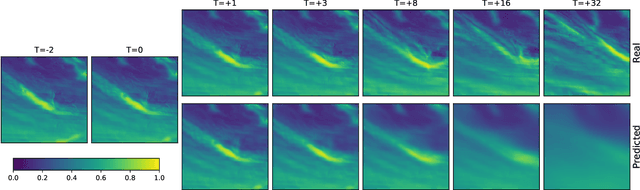
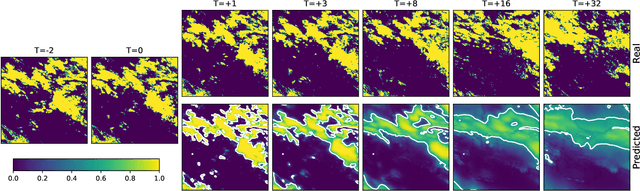
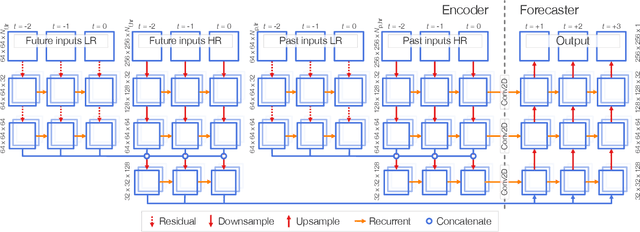
The Weather4cast 2021 competition gave the participants a task of predicting the time evolution of two-dimensional fields of satellite-based meteorological data. This paper describes the author's efforts, after initial success in the first stage of the competition, to improve the model further in the second stage. The improvements consisted of a shallower model variant that is competitive against the deeper version, adoption of the AdaBelief optimizer, improved handling of one of the predicted variables where the training set was found not to represent the validation set well, and ensembling multiple models to improve the results further. The largest quantitative improvements to the competition metrics can be attributed to the increased amount of training data available in the second stage of the competition, followed by the effects of model ensembling. Qualitative results show that the model can predict the time evolution of the fields, including the motion of the fields over time, starting with sharp predictions for the immediate future and blurring of the outputs in later frames to account for the increased uncertainty.
Spatiotemporal Weather Data Predictions with Shortcut Recurrent-Convolutional Networks: A Solution for the Weather4cast challenge
Nov 03, 2021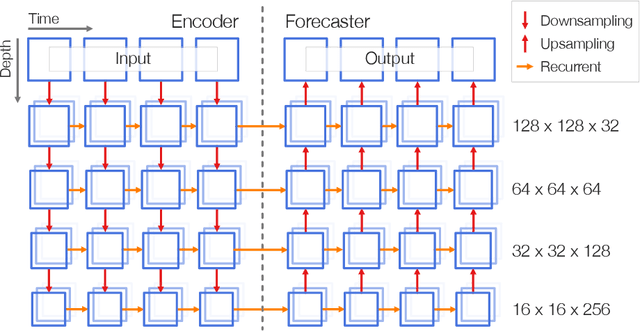
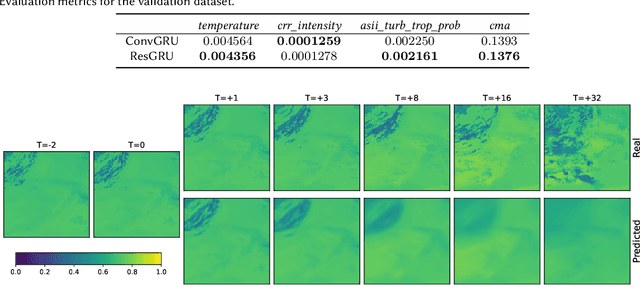
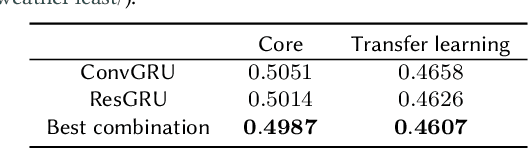

This paper presents the neural network model that was used by the author in the Weather4cast 2021 Challenge Stage 1, where the objective was to predict the time evolution of satellite-based weather data images. The network is based on an encoder-forecaster architecture making use of gated recurrent units (GRU), residual blocks and a contracting/expanding architecture with shortcuts similar to U-Net. A GRU variant utilizing residual blocks in place of convolutions is also introduced. Example predictions and evaluation metrics for the model are presented. These demonstrate that the model can retain sharp features of the input for the first predictions, while the later predictions become more blurred to reflect the increasing uncertainty.
Stochastic Super-Resolution for Downscaling Time-Evolving Atmospheric Fields with a Generative Adversarial Network
May 20, 2020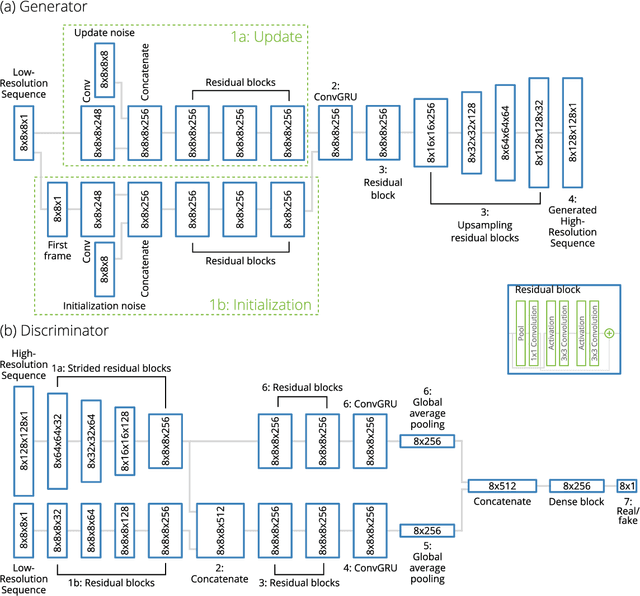
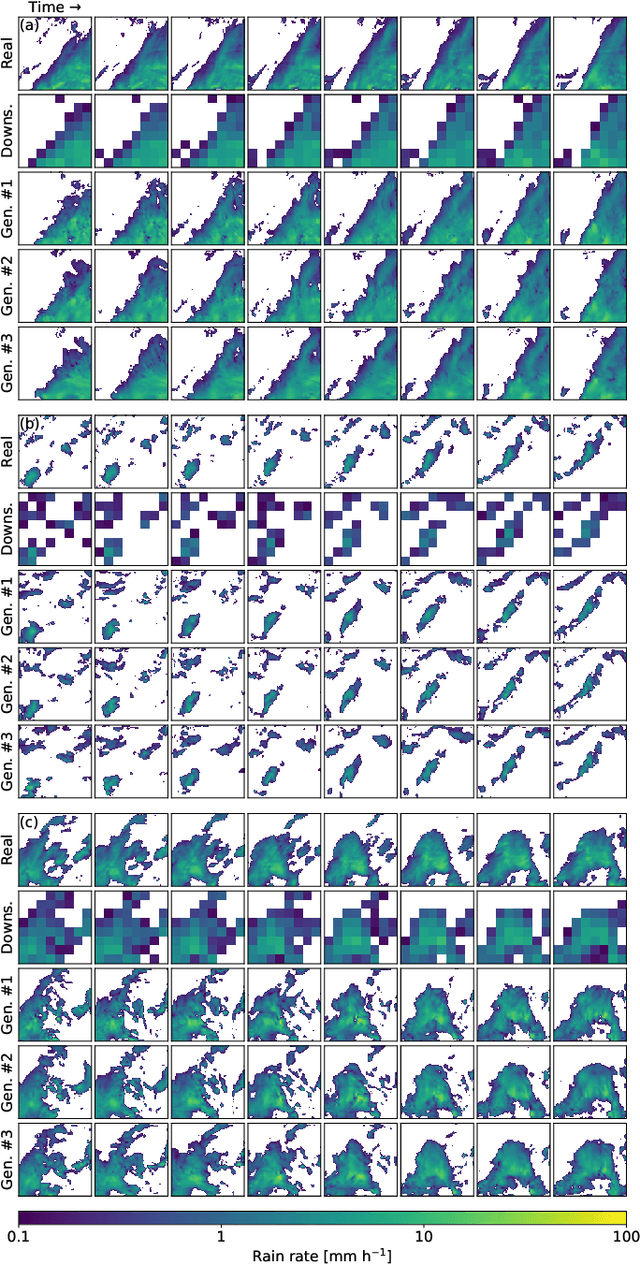
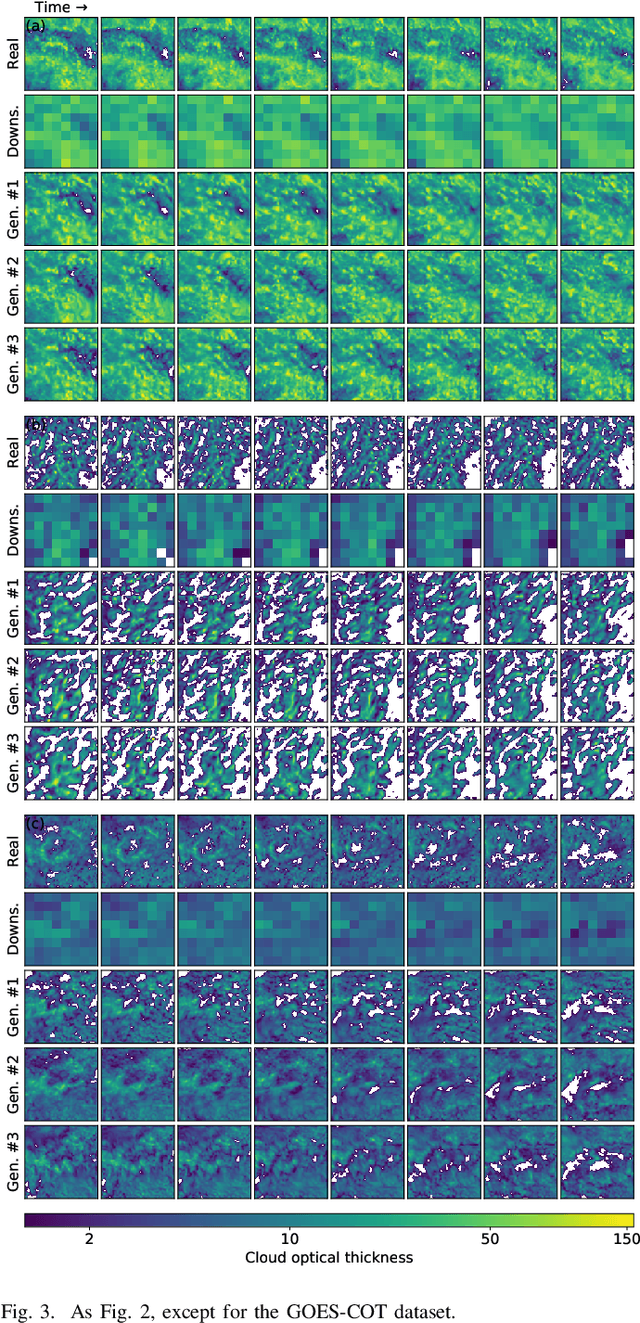
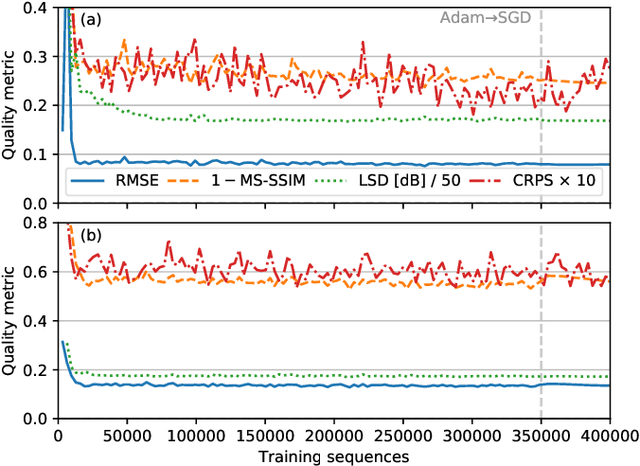
Generative adversarial networks (GANs) have been recently adopted for super-resolution, an application closely related to what is referred to as "downscaling" in the atmospheric sciences. The ability of conditional GANs to generate an ensemble of solutions for a given input lends itself naturally to stochastic downscaling, but the stochastic nature of GANs is not usually considered in super-resolution applications. Here, we introduce a recurrent, stochastic super-resolution GAN that can generate ensembles of time-evolving high-resolution atmospheric fields for an input consisting of a low-resolution sequence of images of the same field. We test the GAN using two datasets, one consisting of radar-measured precipitation from Switzerland, the other of cloud optical thickness derived from the Geostationary Earth Observing Satellite 16 (GOES-16). We find that the GAN can generate realistic, temporally consistent solutions for both datasets. The statistical properties of the generated ensemble are analyzed using rank statistics, a method adapted from ensemble weather forecasting; these analyses indicate that the GAN produces close to the correct amount of variability in its outputs. As the GAN generator is fully convolutional, it can be applied after training to input images larger than the images used to train it. It is also able to generate time series much longer than the training sequences, as demonstrated by applying the generator to a three-month dataset of the precipitation radar data.