 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems remain brittle under realistic retrieval noise, even when the required evidence appears in the top-K results. A key reason is that retrievers and rerankers optimize solely for relevance, often selecting either trivial, answer-revealing passages or evidence that lacks the critical information required to answer the question, without considering whether the evidence is suitable for the generator. We propose BAR-RAG, which reframes the reranker as a boundary-aware evidence selector that targets the generator's Goldilocks Zone -- evidence that is neither trivially easy nor fundamentally unanswerable for the generator, but is challenging yet sufficient for inference and thus provides the strongest learning signal. BAR-RAG trains the selector with reinforcement learning using generator feedback, and adopts a two-stage pipeline that fine-tunes the generator under the induced evidence distribution to mitigate the distribution mismatch between training and inference. Experiments on knowledge-intensive question answering benchmarks show that BAR-RAG consistently improves end-to-end performance under noisy retrieval, achieving an average gain of 10.3 percent over strong RAG and reranking baselines while substantially improving robustness. Code is publicly avaliable at https://github.com/GasolSun36/BAR-RAG.
Grounding Agent Memory in Contextual Intent
Jan 15, 2026Deploying large language models in long-horizon, goal-oriented interactions remains challenging because similar entities and facts recur under different latent goals and constraints, causing memory systems to retrieve context-mismatched evidence. We propose STITCH (Structured Intent Tracking in Contextual History), an agentic memory system that indexes each trajectory step with a structured retrieval cue, contextual intent, and retrieves history by matching the current step's intent. Contextual intent provides compact signals that disambiguate repeated mentions and reduce interference: (1) the current latent goal defining a thematic segment, (2) the action type, and (3) the salient entity types anchoring which attributes matter. During inference, STITCH filters and prioritizes memory snippets by intent compatibility, suppressing semantically similar but context-incompatible history. For evaluation, we introduce CAME-Bench, a benchmark for context-aware retrieval in realistic, dynamic, goal-oriented trajectories. Across CAME-Bench and LongMemEval, STITCH achieves state-of-the-art performance, outperforming the strongest baseline by 35.6%, with the largest gains as trajectory length increases. Our analysis shows that intent indexing substantially reduces retrieval noise, supporting intent-aware memory for robust long-horizon reasoning.
Improving Scientific Document Retrieval with Academic Concept Index
Jan 02, 2026Adapting general-domain retrievers to scientific domains is challenging due to the scarcity of large-scale domain-specific relevance annotations and the substantial mismatch in vocabulary and information needs. Recent approaches address these issues through two independent directions that leverage large language models (LLMs): (1) generating synthetic queries for fine-tuning, and (2) generating auxiliary contexts to support relevance matching. However, both directions overlook the diverse academic concepts embedded within scientific documents, often producing redundant or conceptually narrow queries and contexts. To address this limitation, we introduce an academic concept index, which extracts key concepts from papers and organizes them guided by an academic taxonomy. This structured index serves as a foundation for improving both directions. First, we enhance the synthetic query generation with concept coverage-based generation (CCQGen), which adaptively conditions LLMs on uncovered concepts to generate complementary queries with broader concept coverage. Second, we strengthen the context augmentation with concept-focused auxiliary contexts (CCExpand), which leverages a set of document snippets that serve as concise responses to the concept-aware CCQGen queries. Extensive experiments show that incorporating the academic concept index into both query generation and context augmentation leads to higher-quality queries, better conceptual alignment, and improved retrieval performance.
Adaptation of Agentic AI
Dec 22, 2025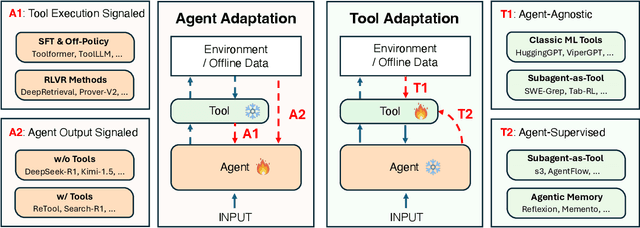
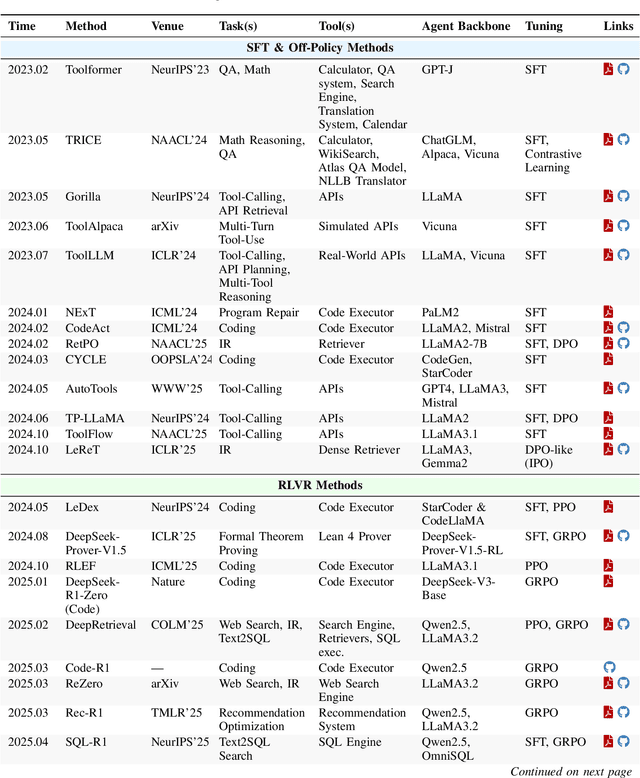
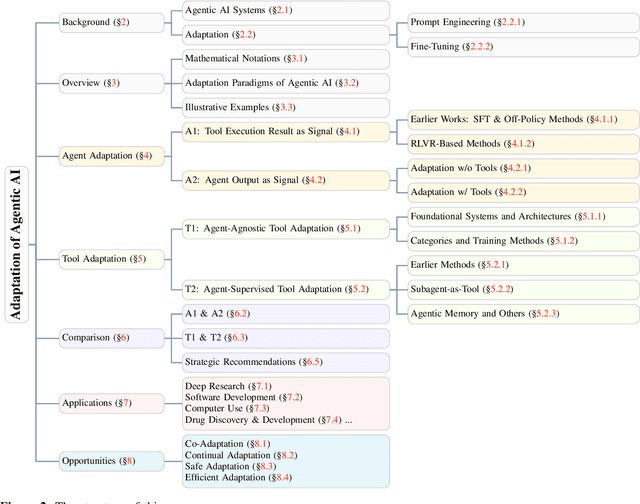
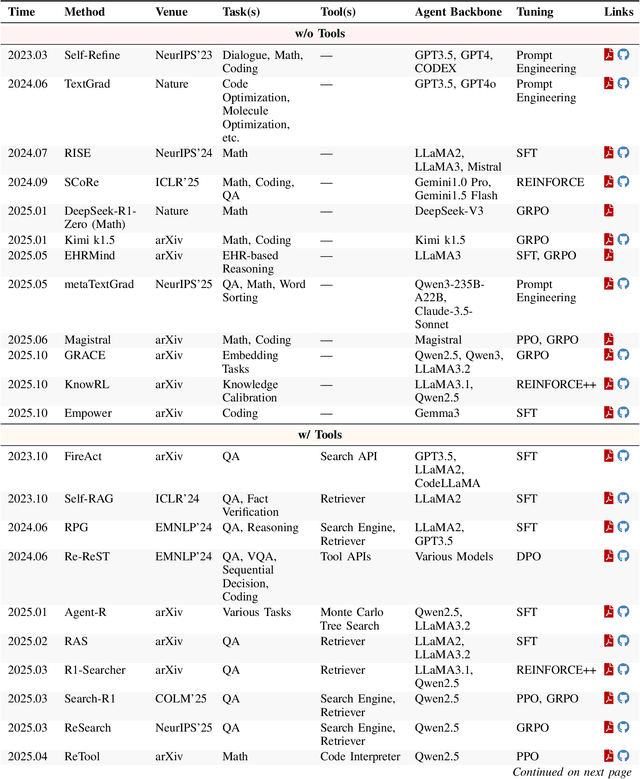
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Vibe Checker: Aligning Code Evaluation with Human Preference
Oct 08, 2025



Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.
GRACE: Generative Representation Learning via Contrastive Policy Optimization
Oct 06, 2025Prevailing methods for training Large Language Models (LLMs) as text encoders rely on contrastive losses that treat the model as a black box function, discarding its generative and reasoning capabilities in favor of static embeddings. We introduce GRACE (Generative Representation Learning via Contrastive Policy Optimization), a novel framework that reimagines contrastive signals not as losses to be minimized, but as rewards that guide a generative policy. In GRACE, the LLM acts as a policy that produces explicit, human-interpretable rationales--structured natural language explanations of its semantic understanding. These rationales are then encoded into high-quality embeddings via mean pooling. Using policy gradient optimization, we train the model with a multi-component reward function that maximizes similarity between query positive pairs and minimizes similarity with negatives. This transforms the LLM from an opaque encoder into an interpretable agent whose reasoning process is transparent and inspectable. On MTEB benchmark, GRACE yields broad cross category gains: averaged over four backbones, the supervised setting improves overall score by 11.5% over base models, and the unsupervised variant adds 6.9%, while preserving general capabilities. This work treats contrastive objectives as rewards over rationales, unifying representation learning with generation to produce stronger embeddings and transparent rationales. The model, data and code are available at https://github.com/GasolSun36/GRACE.
Topic Coverage-based Demonstration Retrieval for In-Context Learning
Sep 15, 2025The effectiveness of in-context learning relies heavily on selecting demonstrations that provide all the necessary information for a given test input. To achieve this, it is crucial to identify and cover fine-grained knowledge requirements. However, prior methods often retrieve demonstrations based solely on embedding similarity or generation probability, resulting in irrelevant or redundant examples. In this paper, we propose TopicK, a topic coverage-based retrieval framework that selects demonstrations to comprehensively cover topic-level knowledge relevant to both the test input and the model. Specifically, TopicK estimates the topics required by the input and assesses the model's knowledge on those topics. TopicK then iteratively selects demonstrations that introduce previously uncovered required topics, in which the model exhibits low topical knowledge. We validate the effectiveness of TopicK through extensive experiments across various datasets and both open- and closed-source LLMs. Our source code is available at https://github.com/WonbinKweon/TopicK_EMNLP2025.
Ov3R: Open-Vocabulary Semantic 3D Reconstruction from RGB Videos
Jul 29, 2025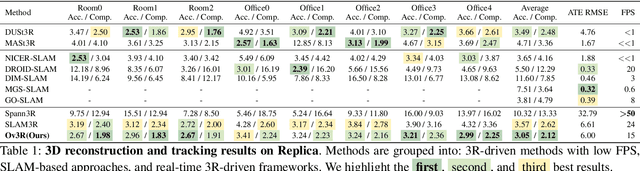
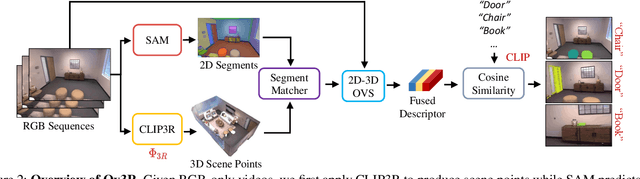

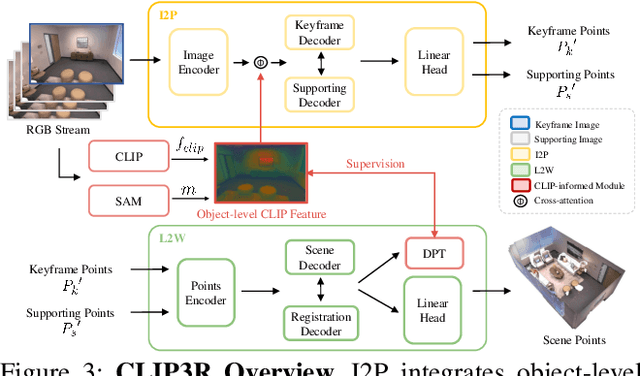
We present Ov3R, a novel framework for open-vocabulary semantic 3D reconstruction from RGB video streams, designed to advance Spatial AI. The system features two key components: CLIP3R, a CLIP-informed 3D reconstruction module that predicts dense point maps from overlapping clips while embedding object-level semantics; and 2D-3D OVS, a 2D-3D open-vocabulary semantic module that lifts 2D features into 3D by learning fused descriptors integrating spatial, geometric, and semantic cues. Unlike prior methods, Ov3R incorporates CLIP semantics directly into the reconstruction process, enabling globally consistent geometry and fine-grained semantic alignment. Our framework achieves state-of-the-art performance in both dense 3D reconstruction and open-vocabulary 3D segmentation, marking a step forward toward real-time, semantics-aware Spatial AI.
Beyond True or False: Retrieval-Augmented Hierarchical Analysis of Nuanced Claims
Jun 12, 2025



Claims made by individuals or entities are oftentimes nuanced and cannot be clearly labeled as entirely "true" or "false" -- as is frequently the case with scientific and political claims. However, a claim (e.g., "vaccine A is better than vaccine B") can be dissected into its integral aspects and sub-aspects (e.g., efficacy, safety, distribution), which are individually easier to validate. This enables a more comprehensive, structured response that provides a well-rounded perspective on a given problem while also allowing the reader to prioritize specific angles of interest within the claim (e.g., safety towards children). Thus, we propose ClaimSpect, a retrieval-augmented generation-based framework for automatically constructing a hierarchy of aspects typically considered when addressing a claim and enriching them with corpus-specific perspectives. This structure hierarchically partitions an input corpus to retrieve relevant segments, which assist in discovering new sub-aspects. Moreover, these segments enable the discovery of varying perspectives towards an aspect of the claim (e.g., support, neutral, or oppose) and their respective prevalence (e.g., "how many biomedical papers believe vaccine A is more transportable than B?"). We apply ClaimSpect to a wide variety of real-world scientific and political claims featured in our constructed dataset, showcasing its robustness and accuracy in deconstructing a nuanced claim and representing perspectives within a corpus. Through real-world case studies and human evaluation, we validate its effectiveness over multiple baselines.
TaxoAdapt: Aligning LLM-Based Multidimensional Taxonomy Construction to Evolving Research Corpora
Jun 12, 2025The rapid evolution of scientific fields introduces challenges in organizing and retrieving scientific literature. While expert-curated taxonomies have traditionally addressed this need, the process is time-consuming and expensive. Furthermore, recent automatic taxonomy construction methods either (1) over-rely on a specific corpus, sacrificing generalizability, or (2) depend heavily on the general knowledge of large language models (LLMs) contained within their pre-training datasets, often overlooking the dynamic nature of evolving scientific domains. Additionally, these approaches fail to account for the multi-faceted nature of scientific literature, where a single research paper may contribute to multiple dimensions (e.g., methodology, new tasks, evaluation metrics, benchmarks). To address these gaps, we propose TaxoAdapt, a framework that dynamically adapts an LLM-generated taxonomy to a given corpus across multiple dimensions. TaxoAdapt performs iterative hierarchical classification, expanding both the taxonomy width and depth based on corpus' topical distribution. We demonstrate its state-of-the-art performance across a diverse set of computer science conferences over the years to showcase its ability to structure and capture the evolution of scientific fields. As a multidimensional method, TaxoAdapt generates taxonomies that are 26.51% more granularity-preserving and 50.41% more coherent than the most competitive baselines judged by LLMs.