 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
Jun 01, 2026Search agents are often trained as policies over growing transcripts: the model must decide how to search while also remembering what it has seen, which evidence is useful, which constraints remain open, and which claims have actually been checked. We argue that this formulation puts too much routine state management inside the policy: reinforcement learning is forced to optimize both semantic search decisions and recoverable bookkeeping that the environment can maintain more reliably. We introduce Harness-1, a 20B search agent (retrieval subagent) trained with reinforcement learning inside a stateful search harness. The harness maintains environment-side working memory, including a candidate pool, an importance-tagged curated set, compact evidence links, verification records, compressed and deduplicated observations, and budget-aware context rendering. The policy retains the semantic decisions: what to search, which documents to keep or discard, what to verify, and when to stop. Across eight retrieval benchmarks spanning web, finance, patents, and multi-hop QA, Harness-1 achieves 0.730 average curated recall, outperforming the next strongest open search subagent by +11.4 points and remaining competitive with much larger frontier-model searchers. Its gains are especially strong on held-out transfer benchmarks, suggesting that reinforcement learning over explicit search state can produce retrieval behaviors that generalize beyond the training domains. Our code is available at https://github.com/pat-jj/harness-1.
Retrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
May 13, 2026Retrieval-Augmented Generation (RAG) has become a standard approach for knowledge-intensive question answering, but existing systems remain brittle on multi-hop questions, where solving the task requires chaining multiple retrieval and reasoning steps. Key challenges are that current methods represent reasoning through free-form natural language, where intermediate states are implicit, retrieval queries can drift from intended entities, and errors are detected by the same model that produces them making self-reflection an unreliable, ungrounded signal. We observe that multi-hop question answering is a typical form of step-by-step computation, and that this structured process aligns closely with how code-specialized language models are trained to operate. Motivated by this, we introduce \pyrag, a framework that reformulates multi-hop RAG as program synthesis and execution. Instead of free-form reasoning trajectories, \pyrag represents the reasoning process as an executable Python program over retrieval and QA tools, exposing intermediate states as variables, producing deterministic feedback through execution, and yielding an inspectable trace of the entire reasoning process. This formulation further enables compiler-grounded self-repair and execution-driven adaptive retrieval without any additional training. Experiments on five QA benchmarks (PopQA, HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle) show that \pyrag consistently outperforms strong baselines under both training-free and RL-trained settings, with especially large gains on compositional multi-hop datasets. Our code, data and models are publicly available at https://github.com/GasolSun36/PyRAG.
Let the Abyss Stare Back Adaptive Falsification for Autonomous Scientific Discovery
Mar 30, 2026Autonomous scientific discovery is entering a more dangerous regime: once the evaluator is frozen, a sufficiently strong search process can learn to win the exam without learning the mechanism the task was meant to reveal. This is the idea behind our title. To let the abyss stare back is to make evaluation actively push against the candidate through adaptive falsification, rather than passively certify it through static validation. We introduce DASES, a falsification-driven framework in which an Innovator, an Abyss Falsifier, and a Mechanistic Causal Extractor co-evolve executable scientific artifacts and scientifically admissible counterexample environments under a fixed scientific contract. In a controlled loss-discovery problem with a single editable locus, DASES rejects artifacts that static validation would have accepted, identifies the first candidate that survives the admissible falsification frontier, and discovers FNG-CE, a loss that transfers beyond the synthetic discovery environment and consistently outperforms CE and CE+L2 under controlled comparisons across standard benchmarks, including ImageNet.
Learning to Predict Future-Aligned Research Proposals with Language Models
Mar 28, 2026Large language models (LLMs) are increasingly used to assist ideation in research, but evaluating the quality of LLM-generated research proposals remains difficult: novelty and soundness are hard to measure automatically, and large-scale human evaluation is costly. We propose a verifiable alternative by reframing proposal generation as a time-sliced scientific forecasting problem. Given a research question and inspiring papers available before a cutoff time, the model generates a structured proposal and is evaluated by whether it anticipates research directions that appear in papers published after the time. We operationalize this objective with the Future Alignment Score (FAS), computed via retrieval and LLM-based semantic scoring against a held-out future corpus. To train models, we build a time-consistent dataset of 17,771 papers from targets and their pre-cutoff citations, and synthesize reasoning traces that teach gap identification and inspiration borrowing. Across Llama-3.1 and Qwen2.5 models, future-aligned tuning improves future alignment over unaligned baselines (up to +10.6% overall FAS), and domain-expert human evaluation corroborates improved proposal quality. Finally, we demonstrate practical impact by implementing two model-generated proposals with a code agent, obtaining 4.17% accuracy gain on MATH from a new prompting strategy and consistent improvements for a novel model-merging method.
TaSR-RAG: Taxonomy-guided Structured Reasoning for Retrieval-Augmented Generation
Mar 10, 2026Retrieval-Augmented Generation (RAG) helps large language models (LLMs) answer knowledge-intensive and time-sensitive questions by conditioning generation on external evidence. However, most RAG systems still retrieve unstructured chunks and rely on one-shot generation, which often yields redundant context, low information density, and brittle multi-hop reasoning. While structured RAG pipelines can improve grounding, they typically require costly and error-prone graph construction or impose rigid entity-centric structures that do not align with the query's reasoning chain. We propose \textsc{TaSR-RAG}, a taxonomy-guided structured reasoning framework for evidence selection. We represent both queries and documents as relational triples, and constrain entity semantics with a lightweight two-level taxonomy to balance generalization and precision. Given a complex question, \textsc{TaSR-RAG} decomposes it into an ordered sequence of triple sub-queries with explicit latent variables, then performs step-wise evidence selection via hybrid triple matching that combines semantic similarity over raw triples with structural consistency over typed triples. By maintaining an explicit entity binding table across steps, \textsc{TaSR-RAG} resolves intermediate variables and reduces entity conflation without explicit graph construction or exhaustive search. Experiments on multiple multi-hop question answering benchmarks show that \textsc{TaSR-RAG} consistently outperforms strong RAG and structured-RAG baselines by up to 14\%, while producing clearer evidence attribution and more faithful reasoning traces.
Steer2Adapt: Dynamically Composing Steering Vectors Elicits Efficient Adaptation of LLMs
Feb 07, 2026Activation steering has emerged as a promising approach for efficiently adapting large language models (LLMs) to downstream behaviors. However, most existing steering methods rely on a single static direction per task or concept, making them inflexible under task variation and inadequate for complex tasks that require multiple coordinated capabilities. To address this limitation, we propose STEER2ADAPT, a lightweight framework that adapts LLMs by composing steering vectors rather than learning new ones from scratch. In many domains (e.g., reasoning or safety), tasks share a small set of underlying concept dimensions. STEER2ADAPT captures these dimensions as a reusable, low-dimensional semantic prior subspace, and adapts to new tasks by dynamically discovering a linear combination of basis vectors from only a handful of examples. Experiments across 9 tasks and 3 models in both reasoning and safety domains demonstrate the effectiveness of STEER2ADAPT, achieving an average improvement of 8.2%. Extensive analyses further show that STEER2ADAPT is a data-efficient, stable, and transparent inference-time adaptation method for LLMs.
Rethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems remain brittle under realistic retrieval noise, even when the required evidence appears in the top-K results. A key reason is that retrievers and rerankers optimize solely for relevance, often selecting either trivial, answer-revealing passages or evidence that lacks the critical information required to answer the question, without considering whether the evidence is suitable for the generator. We propose BAR-RAG, which reframes the reranker as a boundary-aware evidence selector that targets the generator's Goldilocks Zone -- evidence that is neither trivially easy nor fundamentally unanswerable for the generator, but is challenging yet sufficient for inference and thus provides the strongest learning signal. BAR-RAG trains the selector with reinforcement learning using generator feedback, and adopts a two-stage pipeline that fine-tunes the generator under the induced evidence distribution to mitigate the distribution mismatch between training and inference. Experiments on knowledge-intensive question answering benchmarks show that BAR-RAG consistently improves end-to-end performance under noisy retrieval, achieving an average gain of 10.3 percent over strong RAG and reranking baselines while substantially improving robustness. Code is publicly avaliable at https://github.com/GasolSun36/BAR-RAG.
BibAgent: An Agentic Framework for Traceable Miscitation Detection in Scientific Literature
Jan 12, 2026Citations are the bedrock of scientific authority, yet their integrity is compromised by widespread miscitations: ranging from nuanced distortions to fabricated references. Systematic citation verification is currently unfeasible; manual review cannot scale to modern publishing volumes, while existing automated tools are restricted by abstract-only analysis or small-scale, domain-specific datasets in part due to the "paywall barrier" of full-text access. We introduce BibAgent, a scalable, end-to-end agentic framework for automated citation verification. BibAgent integrates retrieval, reasoning, and adaptive evidence aggregation, applying distinct strategies for accessible and paywalled sources. For paywalled references, it leverages a novel Evidence Committee mechanism that infers citation validity via downstream citation consensus. To support systematic evaluation, we contribute a 5-category Miscitation Taxonomy and MisciteBench, a massive cross-disciplinary benchmark comprising 6,350 miscitation samples spanning 254 fields. Our results demonstrate that BibAgent outperforms state-of-the-art Large Language Model (LLM) baselines in citation verification accuracy and interpretability, providing scalable, transparent detection of citation misalignments across the scientific literature.
Adaptation of Agentic AI
Dec 22, 2025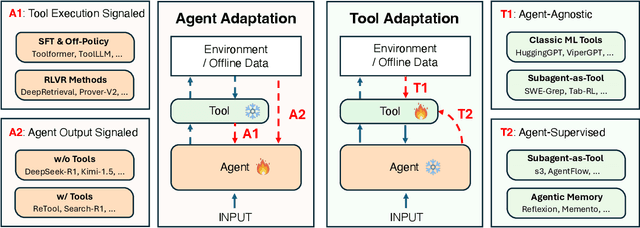
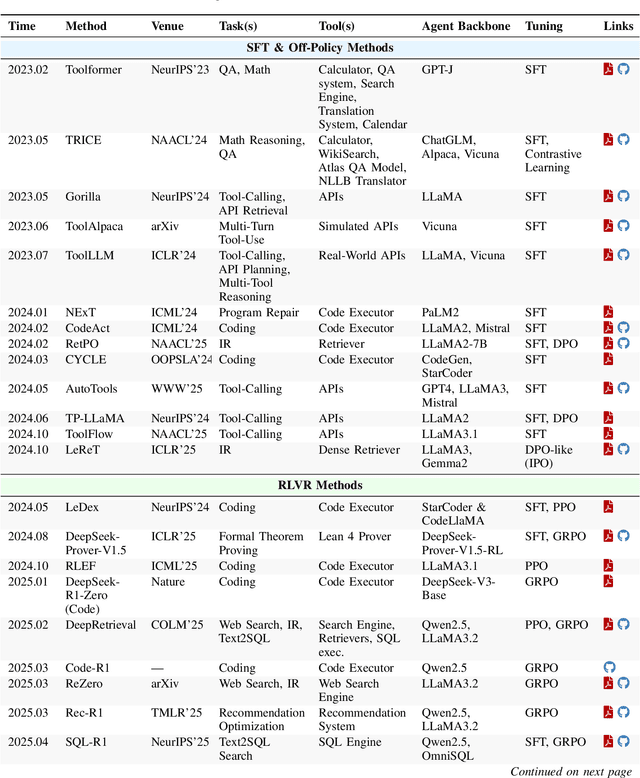
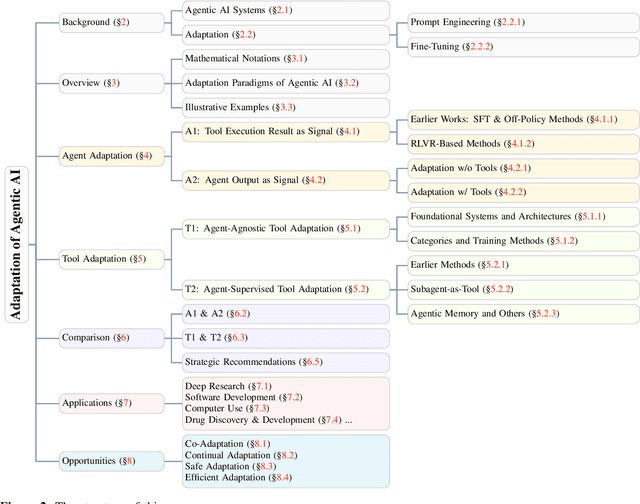
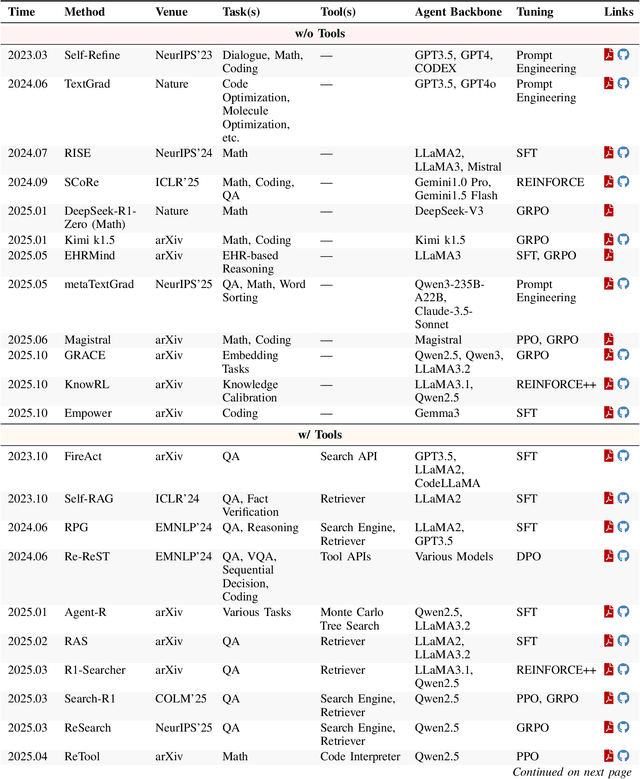
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
GRACE: Generative Representation Learning via Contrastive Policy Optimization
Oct 06, 2025Prevailing methods for training Large Language Models (LLMs) as text encoders rely on contrastive losses that treat the model as a black box function, discarding its generative and reasoning capabilities in favor of static embeddings. We introduce GRACE (Generative Representation Learning via Contrastive Policy Optimization), a novel framework that reimagines contrastive signals not as losses to be minimized, but as rewards that guide a generative policy. In GRACE, the LLM acts as a policy that produces explicit, human-interpretable rationales--structured natural language explanations of its semantic understanding. These rationales are then encoded into high-quality embeddings via mean pooling. Using policy gradient optimization, we train the model with a multi-component reward function that maximizes similarity between query positive pairs and minimizes similarity with negatives. This transforms the LLM from an opaque encoder into an interpretable agent whose reasoning process is transparent and inspectable. On MTEB benchmark, GRACE yields broad cross category gains: averaged over four backbones, the supervised setting improves overall score by 11.5% over base models, and the unsupervised variant adds 6.9%, while preserving general capabilities. This work treats contrastive objectives as rewards over rationales, unifying representation learning with generation to produce stronger embeddings and transparent rationales. The model, data and code are available at https://github.com/GasolSun36/GRACE.